In some cases, in machine learning, you will run into times when semi-supervised learning is necessary. For example, let's say that you want to use supervised learning to run a classification model on your data, but you have no labels. In order for the model to be built, you need data with labels assigned to properly train the model. Semi-supervised learning provides a pathway to do that, even when you start out with unlabeled data.
Semi-Supervised Learning (vs. Supervised/Unsupervised)
The main difference between supervised and unsupervised learning is whether we know the output labels. Supervised learning, as the name suggests, needs labels in order to train a model, whereas unsupervised learning does not require labels. For example, a classification model requires supervised learning as it needs each data point to indicate which class that point belongs to as a prerequisite.
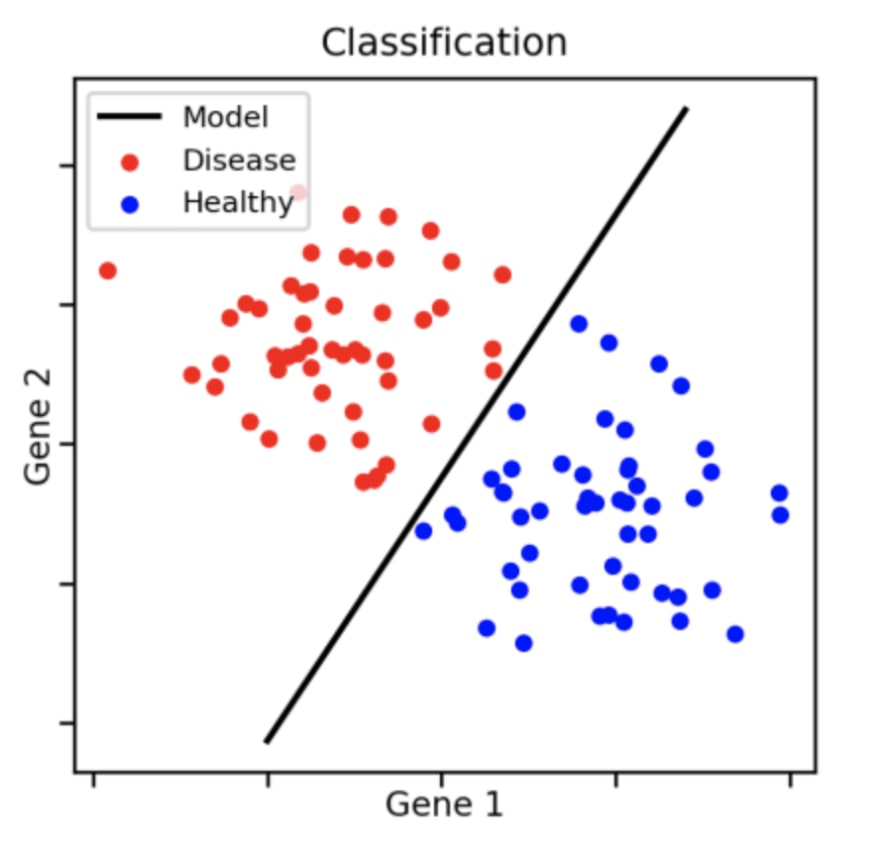
Here, we need each data point to tell us whether it belongs to red (disease) or blue (healthy) in order for us to accurately produce a model to separate the two groups.
For unsupervised learning, we can use the example of clustering.

Unlike the previous example, we don't know which group each data point belongs to before we run the model. For example, in k-means clustering, the model will identify centroids (centers for each group) and assign other data points to the closest centroid.
Semi-supervised learning can entail different methods. For example, I recently created a model to classify NBA players into specific playstyles. Obviously a player's playstyle isn't something objective as determining that is up to personal opinion. Even determining how many playstyles exist is up to opinion as well.
One method that I used was to predetermine which playstyles "existed" in this model and, for a small subset of the players, I would determine a playstyle for them. What this gave me was labeled data that I could use in supervised learning. Once that model was created, I ran the rest of the unlabeled data through it to give me playstyle predictions for everyone else. Then, I used supervised learning again on the fully-labeled data.
Another method, which took less manual work, was to first use unsupervised data to separate players into clusters. Then, using the average stats of each cluster, I could get a sense of what type of playstyle each cluster represented. Using the labels from the clusters, I was able to use supervised learning on the newly-labeled data.
So when you are faced with unlabeled data, but want to do a supervised learning task, don't be discouraged as there are available methods to work around it, such as semi-supervised learning.

Top comments (0)