
Data is at the core of modern businesses, and AWS provides a suite of powerful analytics services to process, query, and analyze vast amounts of structured and unstructured data. AWS Glue, Amazon Athena, and Amazon Redshift are three key services that help organizations manage ETL (Extract, Transform, Load), run serverless SQL queries, and perform data warehousing at scale.
This article provides an in-depth look at these services, their use cases, and how they work together to enable efficient data analytics on AWS.
Overview of AWS Data Analytics Services
AWS provides a comprehensive set of data analytics tools to support various workloads:
- AWS Glue – A serverless ETL (Extract, Transform, Load) service that automates data preparation.
- Amazon Athena – A serverless, interactive query service for analyzing structured and semi-structured data using SQL.
- Amazon Redshift – A cloud data warehouse designed for large-scale analytics with high performance.
These services can work independently or together to process, analyze, and visualize data in a seamless pipeline.
AWS Glue: Serverless Data Integration & ETL
What is AWS Glue?
AWS Glue is a fully managed ETL (Extract, Transform, Load) service that helps businesses prepare, clean, and transform data for analysis. It automates the tedious process of data cataloguing, schema discovery, and job execution.
Key Features of AWS Glue
- Serverless – No infrastructure management required.
- Data Catalog – Automatically discovers and catalogues metadata.
- Supports Multiple Data Sources – Works with S3, RDS, DynamoDB, Redshift, and more.
- ETL Job Automation – Runs scheduled or event-driven ETL jobs.
Example: Creating an ETL Pipeline with AWS Glue
- Extract data from an S3 bucket.
- Transform data using AWS Glue's PySpark-based ETL scripts.
- Load processed data into Amazon Redshift for analysis.
import sys
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
sc = SparkContext()
glueContext = GlueContext(sc)
datasource = glueContext.create_dynamic_frame.from_catalog(database="mydb", table_name="raw_data")
transformed = ApplyMapping.apply(frame=datasource, mappings=[("col1", "string", "new_col1", "string")])
glueContext.write_dynamic_frame.from_options(frame=transformed, connection_type="s3", connection_options={"path": "s3://processed-data"})
Use Cases for AWS Glue:
- Data preparation for analytics – Clean and format raw data for Athena, Redshift, or BI tools.
- Data migration – Move and transform data from on-premises databases to AWS.
- Event-driven ETL – Trigger data processing workflows using AWS Lambda or EventBridge.
Amazon Athena: Serverless Querying for Data in S3
What is Amazon Athena?
Amazon Athena is a serverless, interactive query service that enables users to analyze data stored in Amazon S3 using standard SQL. It eliminates the need for database provisioning, offering a cost-effective, pay-per-query model.
Key Features of Amazon Athena
- No infrastructure management – Runs queries without setting up servers.
- Supports multiple file formats – Works with CSV, JSON, Parquet, ORC, and Avro.
- Integrates with AWS Glue – Uses AWS Glue Data Catalog for schema discovery.
- Pay-per-query pricing – Costs are based on the amount of data scanned.
Example: Querying an S3 Dataset with Athena
Suppose you have logs stored in Amazon S3 in Parquet format. You can query the data using SQL in Athena:
SELECT user_id, COUNT(*) AS logins
FROM logs
WHERE event_type = 'login'
GROUP BY user_id
ORDER BY logins DESC;
Use Cases for Amazon Athena
- Ad hoc querying of large datasets – Analyze logs, clickstreams, or IoT data.
- Log analysis and security monitoring – Query VPC Flow Logs, CloudTrail logs, and application logs.
- BI and reporting – Use Athena with Amazon QuickSight for interactive dashboards.
Amazon Redshift: Cloud Data Warehousing for Large-Scale Analytics
What is Amazon Redshift?
Amazon Redshift is a fully managed, petabyte-scale data warehouse that provides high-performance analytics over structured data. It supports columnar storage, parallel processing, and compression to optimize query execution.
Key Features of Amazon Redshift
- Massively parallel processing (MPP) – Distributes queries across multiple nodes.
- Columnar storage – Speeds up analytical queries by storing data efficiently.
- Integration with AWS services – Works with AWS Glue, S3, and Athena.
- Redshift Spectrum – Enables direct querying of S3 data using Redshift SQL.
Example: Running Queries in Amazon Redshift
To analyze sales data in Redshift:
SELECT region, SUM(revenue) AS total_revenue
FROM sales_data
GROUP BY region
ORDER BY total_revenue DESC;
Use Cases for Amazon Redshift
- Enterprise data warehousing – Centralize data for business intelligence and reporting.
- Customer analytics – Analyze customer behaviour, churn rates, and purchase patterns.
- Big data processing – Run high-performance queries over terabytes or petabytes of data.
How AWS Glue, Athena, and Redshift Work Together
These services complement each other in a modern AWS data analytics pipeline:
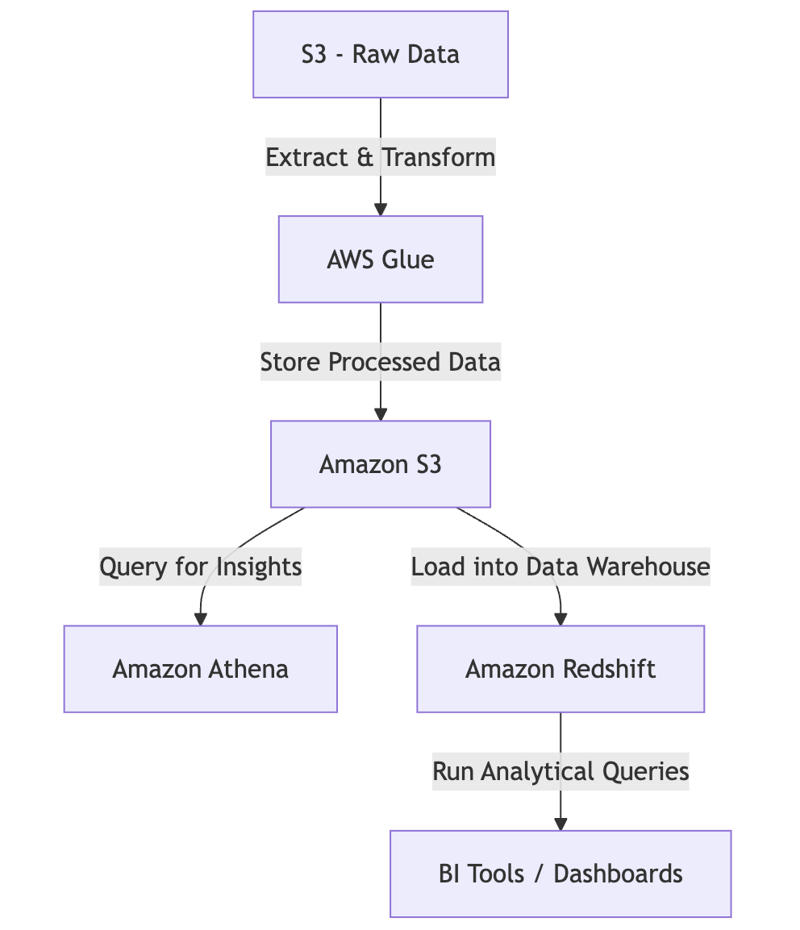
- AWS Glue extracts and transforms raw data, storing structured data in S3.
- Amazon Athena allows users to run ad hoc SQL queries on S3 data.
- Amazon Redshift enables high-performance data warehousing and analytics.
- BI tools like QuickSight, Tableau, and Power BI connect to Athena or Redshift for visualization.
Best Practices for AWS Data Analytics
- Optimize AWS Glue ETL Jobs – Use partitioning and parallelism to improve performance.
- Reduce Athena Query Costs – Compress data and use columnar storage formats (Parquet, ORC).
- Improve Redshift Performance – Use distribution keys, sort keys, and workload management (WLM).
- Automate Workflows – Use AWS Step Functions or Lambda to trigger analytics pipelines.
- Monitor and Optimize Costs – Use Amazon CloudWatch and AWS Cost Explorer to track usage.
Conclusion
AWS provides a powerful ecosystem of analytics tools that enable organizations to process, query, and analyze massive datasets efficiently. AWS Glue streamlines ETL, Amazon Athena offers cost-effective serverless querying, and Amazon Redshift provides a high-performance cloud data warehouse.
By using these services, businesses can gain deeper insights, drive better decisions, and optimize their data analytics workflows.
In the next article, we will explore AWS API Gateway, which enables secure, scalable API development for applications and microservices on AWS.

Top comments (0)