
Something I struggled with when I was beginning web development and I see many new devs struggle with as well: What is a "Server" actually capable of?
I've already given it away with the cover photo; but why not look at it top-to-bottom instead of left-to-right 😅 (and I will talk about each part in more detail)
Simplest Mental Model of a Server

A server is this: software that starts upon request, runs using the information in the request and data from longer term storage without further input, completing execution by updating the stored data and returning a response.
This model eradicates three main misconceptions:
- No processing or execution after the response
- No processing or execution before the request
- No interrupting or user interaction during the process
The above three things can only be achieved using the "storage" aspect in the diagram to coordinate something else to achieve it. The better we understand that something else is a completely separate process, the better prepared we are to handle the hazards in those patterns. The only way to do any of the above three things is with "storage".
What is "Storage"?
I'm using this as a stand-in for any non-volatile data store.
Most commonly a relational database. But it may also be a document database, key-value store, even an in-memory store like Redis* or just files on the local hard drive. In large or needy applications, more than one may be used, but we can mentally lump them all together into "storage".
This current state gets put in the top and updates come out the other side (if anything needs to update).
* Memory stores are usually considered "volatile" in comparison to hard drives, but to the length of an average request-response, a store like Redis comparably keeps data for eons.
The Request
The first big half of the "request-response lifecycle". Nothing, I repeat nothing, happens in HTTP without a request to start it.
A request can have all sorts of information, but the highlights are:
- Verb - aka
GET,POST,PUT,PATCH,DELETE, etc. each has a meaning; please use them appropriately - Host - like
www.buymeacoffee.com - Path - the slashy bits, like
/kallmanation; but also contains the raw query parameters like?via=kallmanation - Various Headers - all sorts of meta-data about the request, mostly look these up as needed; but one is worth mentioning here:
- Cookies - the thing we always have to "accept"; just a bunch of little pieces of text the requester keeps track of for the server
- Body - not on all requests; usually JSON, but can be any text for the server to use
Without data in either the storage or somewhere in this request (mainly in cookies), the server can not know about it and in its opinion that information does not exist and has never existed.
The Response
The end of the "request-response lifecycle". Truly, The End, Finito. Nothing happens in HTTP after the response has been returned.
Like requests, responses have all sorts of information, but the big parts are:
- Status - 200 for OK, 401 for unauthorized, 418 I'm a teapot, etc.; please use the appropriate status
- Headers - again all sorts of meta-data, look up as needed
- Cookies - a specific header can tell the requester to send the given cookie with any future requests (they can also be set by JavaScript)
- Body - HTML/CSS/JS/JSON/XML/etc./etc. whatever we want to send back
Nuanced Mental Model of a Server
To be slightly more pedantic and technical: an application server does not exactly have the entire database stuffed into it on each request. Instead some pre-processing needs to use the request information to formulate a query to storage to load only the needed data.
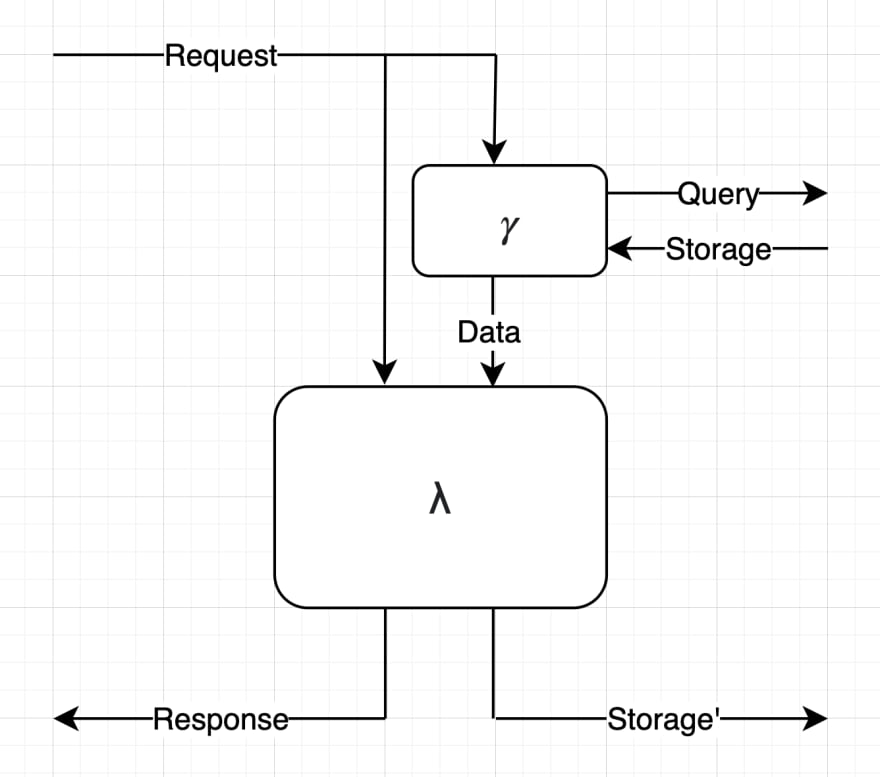
This "Query" might be a regular old SQL query. But it might be just finding the right file on disk by name and path. Or it could be a request to a separate web service managing storage (like in a Database-as-a-Service). Once the data is fetched, the rest of the server continues as it did in the simpler mental model.
To get even more technical; I've never seen a server application written in such distinct steps of fetch all data, process data, update data, return response. The fetching, processing, and updating usually muddles all together (sometimes rightly, oftentimes wrongly). But still, from an external perspective, a requester could not perceive a real difference between that technicality and the more controlled mental model diagrammed above. So I believe it to be a very useful model of an application server.

Top comments (1)
I'd love to hear your mental model of a server! The way we think is so interesting with such unexpected impact.
And if you enjoyed, consider supporting me on Buy Me a Coffee.