
Apache Spark is considered as a powerful complement to Hadoop, big data’s original technology. Spark is a more accessible, powerful and capable big data tool for tackling various big data challenges. It has become mainstream and most in-demand big data framework across all major industries. Spark has become part of the Hadoop since 2.0. And is one of the most useful technologies for Python Big Data Engineers.
This series of posts is a single-stop resource that gives spark architecture overview and it's good for people looking to learn spark.
Whole series:
- Things you need to know about Hadoop and YARN being a Spark developer
- Spark core concepts explained
- Spark. Anatomy of Spark application
Architecture

The components of the spark application are:
- Driver
- Application Master
- Spark Context
- Executors
- Cluster Resource Manager(aka Cluster Manager)
Spark uses a master/slave architecture with the central coordinator, named Driver, and a set of executable worker process, called Executors, which are located on different cluster nodes.
Driver
The Driver (aka an application’s driver process) is responsible for converting a user application into smaller execution units called tasks and then schedules them to run on the executors. The Driver is also responsible for the execution of the spark application and returning the status/results back to the user.
Spark Driver contains various components – DAGScheduler, TaskScheduler, BackendScheduler and Block Manager. They are responsible for the translation of user code into actual spark jobs executed on the cluster.
Other Driver properties:
- can run in an independent process, or on one of the worker node for High Availability(HA);
- stores the metadata about all the Resilient Distributed Databases and their partitions;
- is created once the user submits the spark application to the cluster manager(YARN in our case);
- runs in his own JVM;
- optimizes the logical DAG of transformations and combine them into stages if possible;
- brings up Spark WebUI with application details;
Application Master
As we described in the first post — Application Master is a framework-specific entity and is tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and monitor the application tasks.
Spark Master is created at the same time as the Driver on the same node(in case of cluster mode) when the user submits the spark application using spark-submit.
The Driver informs the Application Master about the executor's requirements for the application and the Application Master negotiates the resources with the Resource Manager to host these executors.
In a standalone mode, the Spark Master plays the role of Cluster manager.
Spark Context
The Spark Context is the main entry point for Spark functionality and so the heart of any Spark application. It allows Spark Driver to access the cluster through a Cluster Resource Manager and it can be used to create RDDs, accumulators and broadcast variables on the cluster. Spark Context also keep track of live executors by sending heartbeat messages regularly.
The Spark Context is created by the Spark Driver for each individual Spark application when it is first submitted by the user. It exists throughout the entire life of a spark application.
The Spark Context terminates once the spark application completes. Only one Spark Context can be active per JVM. You must stop() the active Spark Context before creating a new one.
Cluster Resource Manager
Cluster Manager in a distributed Spark application is the process that monitors, governs, reserves resources in the form of containers on the cluster worker nodes. These containers are reserved upon request by the Application Masters and allocated to the Application Master when released or available.
Once the Cluster Manager allocates the containers, the Application Master provides the container's resources back to Spark Driver and Spark Driver will be responsible for executing the various stages and tasks of Spark application.
Executors
Executors are processes on the worker nodes whose job is to execute the assigned tasks. These tasks are executed on the partitioned RDDs on the worker nodes and then return the result back to the Spark Driver.
Executors launch once at the beginning of Spark Application and then they run for the entire lifetime of an application this phenomenon is known as "Static Allocation of Executors". However, users can also opt for dynamic allocations of executors wherein they can add or remove spark executors dynamically to match with the overall workload. Even if the Spark executor fails, the Spark application can continue.
Executors provide in-memory storage for RDD's partitions that are cached(locally) in Spark applications (via BlockManager).
Other executor properties:
- stores the data in the cache in JVM heap or on HDDs
- reads data from external sources
- writes data to external sources
- performs all the data processing
Spark Application running steps
On this level of understanding let's create and break down one of the simplest spark applications.
from pyspark.sql import SparkSession
# initialization of spark context
conf = SparkConf().setAppName(appName).setMaster(master)
sc = SparkSession\
.builder\
.appName("PythonWordCount")\
.config(conf=conf)
.getOrCreate()
# read data from HDFS, as a result we get RDD of lines
linesRDD = sc.textFile("hdfs://...")
# from RDD of lines create RDD of lists of words
wordsRDD = linesRDD.flatMap(lambda line: line.split(" ")
# from RDD of lists of words make RDD of words tuples where
# the first element is word and the second is counter, at the
# beginning it should be 1
wordCountRDD= wordsRDD.map(lambda word: (word, 1))
# combine elements with the same word value
resultRDD = wordCountRDD.reduceByKey(lambda a, b: a + b)
# write it back to HDFS
resultRDD.saveAsTextFile("hdfs://...")
spark.stop()
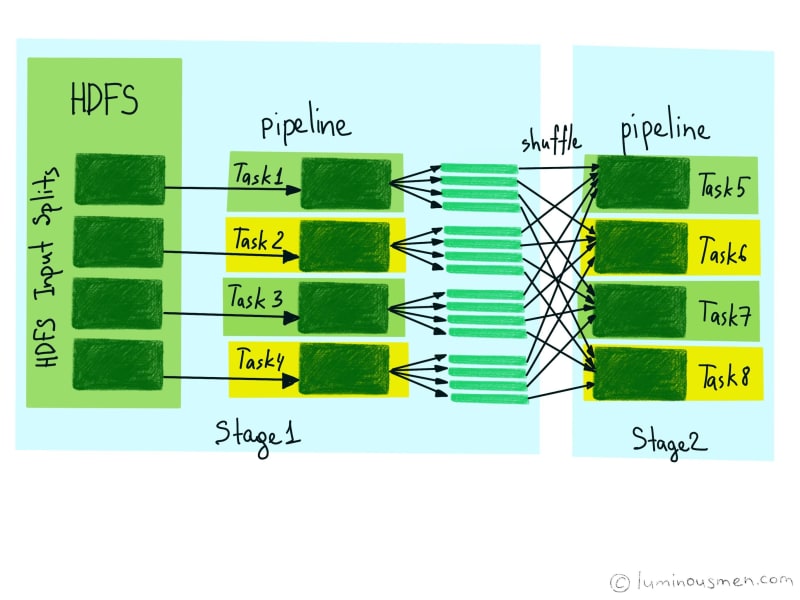
- When we submit a Spark application via the cluster mode,
spark-submitutility will interact with the Cluster Resource Manager to start the Application Master. - The Resource Manager gets responsibility for allocating the required container where the Application Master will be launched. Then Resource Manager launches the Application Master.
- The Application Master registers itself on Resource Manager. Registration allows the client program to ask the Resource Manager for specific information which allows it to directly communicate with its own Application Master.
- Next Spark Driver runs on the Application Master container(in case of cluster mode).
- The driver implicitly converts user code that contains transformations and actions into a logical plan called DAG of RDDs. All RDDs are created on the Driver and do not do anything until action is called. On this step, Driver also performs optimizations such as pipelining transformations.
- After that, it converts the DAG into a physical execution plan. After converting into a physical execution plan, it creates physical execution units called tasks under each stage.
- Now the Driver talks to the Cluster Manager and negotiates the resources. Cluster Manager will then allocate containers and launches executors on all the allocated containers and assigns tasks to run on behalf of the Driver. When executors start, they register themselves with Driver. So, the Driver will have a complete view of executors that are executing the task.
- At this point, the driver will send the tasks to the executors based on data placement. The cluster manager is responsible for the scheduling and allocation of resources across the worker machines forming the cluster. At this point, the Driver sends tasks to the Cluster Manager based on data placement.
- Upon successful receipt of the containers, the Application Master launches the container by providing the Node Manager with a container configuration.
- Inside the container, the user application code starts. It provides information (stage of execution, status) to Application Master.
- So, on this step, we will actually start executing our code. Our first RDD will be created by reading the data from HDFS into different partitions on different nodes in parallel. So each node will have a subset of the data.
- After reading the data we have two map transformations which will be executing in parallel on each partition.
- Then we have a
reduceByKeytransformation, it's not a standard pipe operation likemaphence it will create an additional stage. It combines the records with the same keys, then it moves data between nodes(shuffle) and partitions to combine the same record's keys together. - Then we have the action operation -- writing back to HDFS, which will trigger the whole DAG execution.
- During the user application execution, the client communicates with the Application Master to obtain the status of the application.
- When the application has completed execution and all the necessary work has been finished, the Application Master deregisters from Resource Manager and shuts down, freeing its container for other purposes.
Thank you for reading!
Any questions? Leave your comment below to start fantastic discussions!
Check out my blog or come to say hi 👋 on Twitter or subscribe to my telegram channel.
Plan your best!

Top comments (0)