This blog is meant to help you use Akamai’s API and Libraries within AWS Lambda.
We have so many options to create/innovate. We have moved from physical hardware to Virtualization, Cloud, Containers, Serverless, etc, but regardless of the technology used when our audience grows, scaling can get expensive in resources/cost.
This is why Content Delivery Networks are always a great tool in your arsenal that you should always keep in the back of your mind. Having elasticity in your infrastructure does not replace the benefits from a CDN and because of it, we should think about how to integrate them into our application flow.
In this blog, we will use Akamai’s API’s to provide 100% offload to AWS s3 with little effort.
Using the following libraries in Python.
Let's use this scenario:
My company is using AWS infrastructure for our applications, and most of our static files are stored on s3. We have a requirement where we need to offload (the reason is not important) our bucket as much as possible. We have a special focus on one file that fetches every hour of every day but changes once a day. This company uses Akamai’s distributed platform already to handle a lot of the logic and provide application offload.
Option A:
One of the first things that come to mind is simply increasing TTL (Time To Live) on Akamai to a value of 2 days.
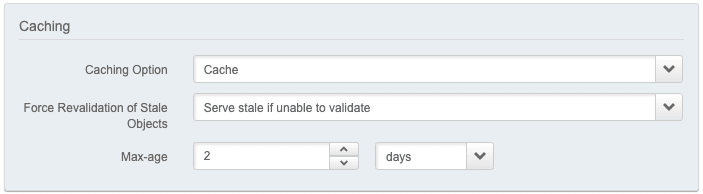
Then schedule recurrent cache invalidations at the time the object changes every day.

This would work in almost all scenarios except some that I’m going to mention. let’s say one day we did not have the file updated at the time we have planned, this would mean that:
We need to manually purge cache once it does
The cache was invalidated even if the object did not refresh. Making this solution a bit static for today’s world and making requests to reach our infrastructure.
Something that will always occur with this solution is that the TTL will always expire at some point meaning that requests will always reach AWS.
Option B:
This is a solution that is a bit more elaborate. Akamai has a Storage solution “NetStorage” using Akamai’s API’s we can integrate it with AWS Lambda.

With Lambda we can trigger a function when the object is refreshed in s3 and do the following:
Upload Object to NetStorage via API
Invalidate Akamai Cache once Uploaded to refresh Content via API.
This will allow us to ensure that we only purge/invalidate the cache when the object is refreshed and by using NetStorage we will achieve 100% Offload meeting the requirements of our example.
How do we do this?
As mentioned earlier we will use some libraries that can be found in Akamai’s Github Page.
In summary, we will need to:
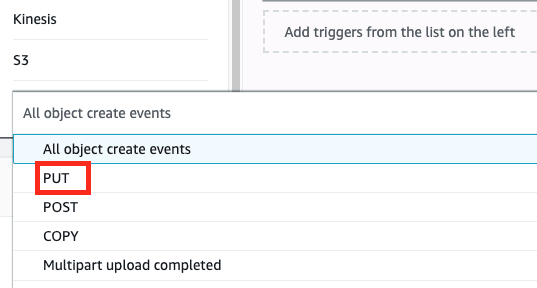
- Trigger the function: This will be using the event “PUT” on the object from s3. If you take a look at the documentation of AWS here you can see a sample event that provides insights into the data available within it.
Download the object from s3: AWS has Boto3 that is very easy to use and it allows us to download the object.
Upload the object to Netstorage: Using NetStorageKit.
Invalidate Cache: Using Akamai Fast Purge API we will be able to invalidate cache within seconds.
We are going to use boto3 to download the object from s3 then upload it with the NetStorage API and invalidate it with the Fast Purge API
.… sounds simple right? You will be surprised that it really is.

This is the final code we will be using in Lambda that can be found in my GitHub here
Let's take a close look.
ah! almost forgot! make sure you have the following before you start!:
# You need a role for lambda to access s3
# You need to provision Akamai NetStorage API Key/Upload Account.
# You need Akamai Open API User Account
# You need to know the NetStorage HOSTNAME, KEYNAME, KEY AND CPCODE
# You need to s3 Object Key (Path/File), optionally you can get this from the s3 event
Note: I’m not going to cover how to create the lambda function nor the Akamai credentials.
Take a look at this Github repository, the first thing you will notice is a bunch of folders and files in the “/src/” directory.

This is because in Lambda you can’t install or reference libraries, meaning you need to provide everything for it to work.
You will need to open the project directory in your terminal install/download the packages:
pip install edgegrid-python -t .
pip install netstorageapi -t .
pip install urllib.parse -t .
Once this is done your imports will work as expected.
ok, so we have 3 functions:
getObjectFromS3():
On this function, we download the object from s3 into a temp directory (you can get the object instead of downloading it).
s3 = boto3.resource('s3')
s3.meta.client.download_file(bucket, path+'/'+file, '/tmp/'+file)
If you notice we use the variable “path” and “file”. All variables are stored in Environment variables to avoid hardcoding them, especially because we need to store API credentials. To get the values from the Env Variables we use “os.environ[“KEYNAME”]” and assign the values to a variable that can be reused.
#Fetch Credentials from Env Variables from AWS
AO_ACCESS_TOKEN = os.environ['AO_ACCESS_TOKEN']
AO_CLIENT_SECRET = os.environ['AO_CLIENT_SECRET']
AO_API_HOST = os.environ['AO_API_HOST']
AO_CLIENT_TOKEN = os.environ['AO_CLIENT_TOKEN']
# Fetch s3 Variables from Env from AWS
S3_Bucket = os.environ['S3_Bucket']
S3_Path = os.environ['S3_PATH']
S3_File = os.environ['S3_File']
#Fetch Akamai NS Variables from Env from AWS
NS_HOSTNAME = os.environ['NS_HOSTNAME']
NS_KEYNAME = os.environ['NS_KEYNAME']
NS_KEY = os.environ['NS_KEY']
NS_CP = os.environ['NS_CP']
uploadToNS():
This function uses both mentioned above (variables and get the object from s3).
Here we get the variables for us to fetch the object and the credentials to use the NetStorage API that if you look closely, it only takes 2 lines to upload but here we validate that the object was downloaded and exists within the temp directory.
ns = Netstorage(NS_HOSTNAME, NS_KEYNAME, NS_KEY, *ssl*=False)
ns.upload('/tmp/'+S3_File,'/'+S3_Path+*str*(NS_CP)+'/')
# Note: SSL can be enabled
purgeCpcode():
Just like the previous function we get the needed credentials and start creating our HTTP request with the EdgeGrid authentication method for us to be able to talk to Akamai. We also set the request body and Content-Type header as per the EndPoint spec and once ready we make the request. If everything goes well we will get a 201 response from Akamai.
At this point, we have gone through the different sections of the script to see what they do and how. Once uploaded to AWS you should see something like this.

Conclusion
Knowing that you can implement/consume Akamai API’s within Lambda opens a world of possibilities, I wanted to share this blog to provide a quick example on how you would go about doing so and hopefully you find it useful.
The last disclaimer:
This script is an example I and would strongly recommend that you improve it as much as possible before taking it into production.
You can find this Blog on medium here:
https://medium.com/@roymartinezblanco/how-to-use-akamai-api-libraries-in-aws-lambda-5204fedc21f3

Top comments (0)