
Machine Learning
There is an increasing focus on data and machine learning these days.Machine learning helps us to make informed decision and now we have data and scientific methods to derive more intelligent and accurate forecasts.
Machine learning provides systems the ability to automatically learn and improve from experience without being explicitly programmed. AWS ML is a robust,cloud-based service that makes it easy for developers of all skill levels to use machine learning technology.
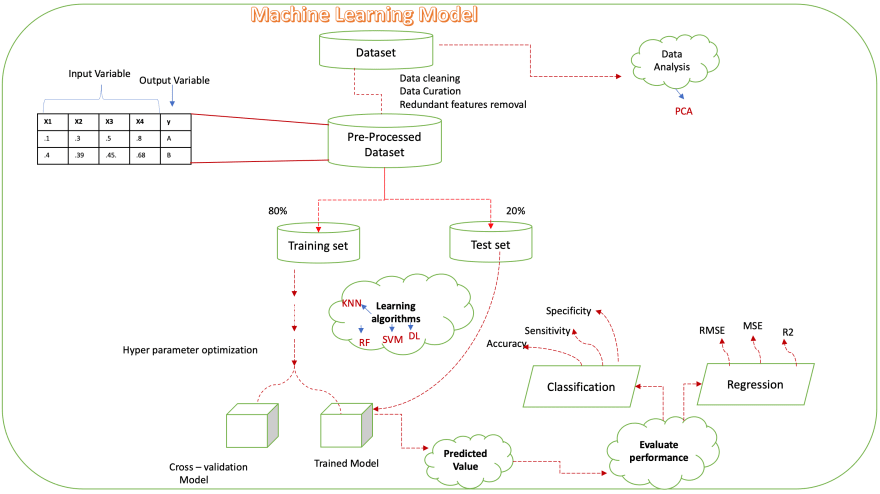
Steps to build an ML model.
1.Gather the dataset.
2.Perform data analysis to produce a low dimensional
representation of a higher dimensional data set using
unsupervised machine learning techniques like PCA and SOM.
3.Data cleaning and curation to get the pre-processed
data.
4.Split the data set into two
i) Training data set (80% of the pre-processed dataset)
ii) Test data set (20% of the pre-processed dataset)
5.Apply machine learning algorithms to get the validation
model and test model.
6.Derive the prediction value from the Model.
7.Evaluate the model performance using confusion matrix
and other ML formulas.
8.Re-iterate through this process until you get sufficient
accuracy for the prediction.
9.Deploy the model to use it in Production (Enterprise
level)
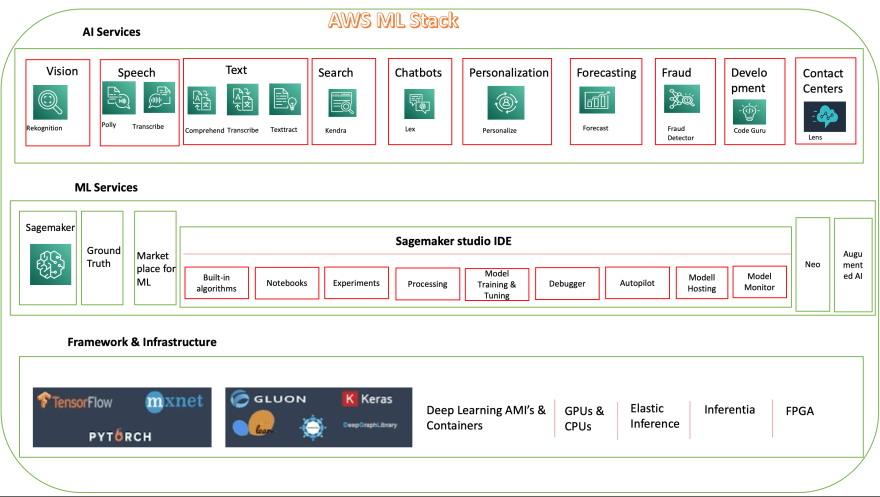
AWS ML
Amazon ML supports three types of ML models.
Binary classification
Multi-class classification
Regression
Both Binary classification and Multi-class classification comes under supervised learning and Regression comes under unsupervised learning.
Binary classification Predict values that can only have two categories such as true or false.
Multi-class classification Predict values that belong to limited, predefined categories.
Regression (squared loss function + SGD) Predict a numeric value.
Below table provides details about the ML algorithm's

AWS ML STACK
Amazon SageMaker, machine-learning platform that takes care of abstracting a ton of software development skills necessary to accomplish the task.
SageMaker supports frameworks like TensorFlow, PyTorch, Apache MXNet, Chainer, Keras, Gluon, Horovod, Scikit-learn, and Deep Graph Library.
Amazon SageMaker Studio, the fully integrated development environment (IDE) for machine learning and helps developers to set up an end-to-end ML solution.
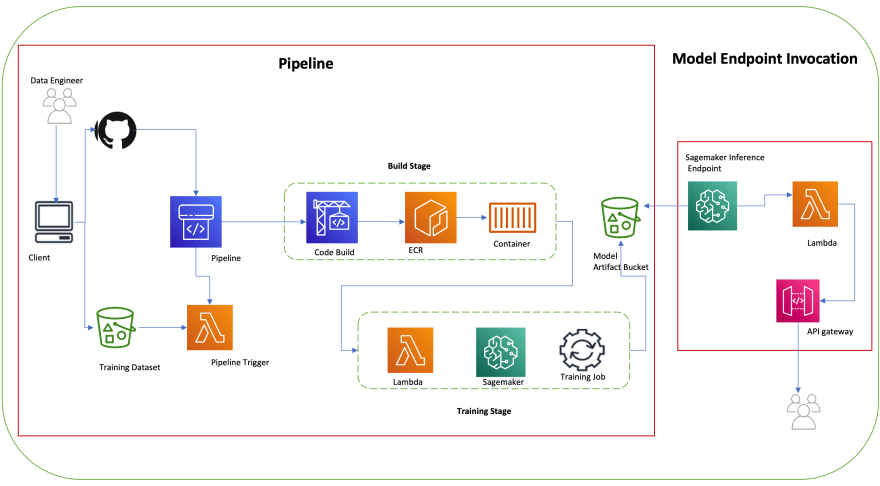
Simple Machine learning Pipeline
Automated ml pipeline can be created using the AWS code pipeline and Sagemaker services.
Build: Compile and build your custom source application code and output a docker image.
Training: Run training on the docker image with SageMaker API and output model artefacts to S3 bucket.
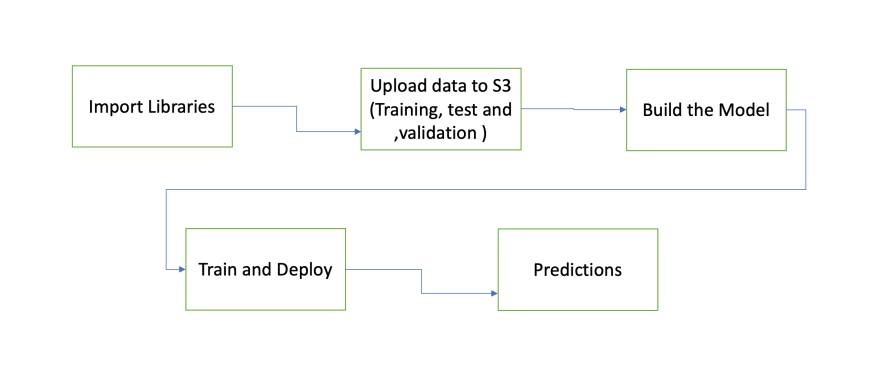
Sagemaker Jupyter notebook to build and deploy, train the model
Let's see how to build the sagemaker jupyter notebook to solve the common Bike-sharing demand prediction problem.
Problem : You are provided hourly rental data spanning two years. The training set is comprised of the first 19 days of each month, while the test set is the 20th to the end of the month. You must predict the total count of bikes rented during each hour covered by the test set, using only information available prior to the rental period.
First Import Libraries
import numpy as np
import pandas as pd
import boto3
import re
import sagemaker
from sagemaker import get_execution_role
Upload Data to S3
# Specify your bucket name
bucket_name = 'selva-ml-sagemaker'
training_folder = r'bikerental/training/'
validation_folder = r'bikerental/validation/'
test_folder = r'bikerental/test/'
s3_model_output_location = r's3://{0}/bikerental/model'.format(bucket_name)
s3_training_file_location = r's3://{0}/{1}'.format(bucket_name,training_folder)
s3_validation_file_location = r's3://{0}/{1}'.format(bucket_name,validation_folder)
s3_test_file_location = r's3://{0}/{1}'.format(bucket_name,test_folder)
def write_to_s3(filename, bucket, key):
with open(filename,'rb') as f: # Read in binary mode
return boto3.Session().resource('s3').Bucket(bucket).Object(key).upload_fileobj(f)
write_to_s3('bike_train.csv',
bucket_name,
training_folder + 'bike_train.csv')
write_to_s3('bike_validation.csv',
bucket_name,
validation_folder + 'bike_validation.csv')
write_to_s3('bike_test.csv',
bucket_name,
test_folder + 'bike_test.csv')
Build
use_spot_instances = True
max_run = 3600 # in seconds
max_wait = 7200 if use_spot_instances else None # in seconds
job_name = 'xgboost-bikerental-v1'
checkpoint_s3_uri = None
if use_spot_instances:
checkpoint_s3_uri = f's3://{bucket_name}/bikerental/checkpoints/{job_name}'
print (f'Checkpoint uri: {checkpoint_s3_uri}')
sess = sagemaker.Session()
role = get_execution_role()
container = sagemaker.image_uris.retrieve("xgboost",sess.boto_region_name,version="1.2-2")
estimator = sagemaker.estimator.Estimator(
container,
role,
instance_count=1,
instance_type='ml.m5.xlarge',
output_path=s3_model_output_location,
sagemaker_session=sess,
base_job_name = job_name,
use_spot_instances=use_spot_instances,
max_run=max_run,
max_wait=max_wait,
checkpoint_s3_uri=checkpoint_s3_uri)
estimator.set_hyperparameters(max_depth=5,
objective="reg:squarederror",
eta=0.1,
num_round=150)
estimator.hyperparameters()
training_input_config = sagemaker.session.TrainingInput(
s3_data=s3_training_file_location,
content_type='csv',
s3_data_type='S3Prefix')
validation_input_config = sagemaker.session.TrainingInput(
s3_data=s3_validation_file_location,
content_type='csv',
s3_data_type='S3Prefix'
)
data_channels = {'train': training_input_config, 'validation': validation_input_config}
Train and deploy
estimator.fit(data_channels)
predictor = estimator.deploy(initial_instance_count=1, instance_type='ml.m5.xlarge',endpoint_name = job_name)
Run Predictions
from sagemaker.serializers import CSVSerializer
predictor.serializer = CSVSerializer()
predictor.predict(‘input’)
Happy Machine learning coding

Top comments (0)