
In this article, I'll show you how you can do web scraping using Puppeteer and Nodejs. To get started we have to first understand what web scraping is and how Puppeteer can help us to do so.
Web Scraping
Web scraping is a process of extracting data from web pages. It involves fetching the web page and then extracting data from it. After extracting the data you can do whatever you want with that data. You can use that for an API or can store that in a CSV file.
Puppeteer
Puppeteer is an open-source Nodejs library developed by Google. It is based on chromium, a popular version of Google Chrome. Puppeteer runs headless by default but can be configured to run full (non-headless) Chrome or Chromium.
It not only allows us to do web scraping but we can do much more with it. Like:
- Generating screenshots of web pages.
- Generating pdf.
- Automate form submission, UI testing, keyboard input, etc.
Let's do some web scraping
To get started, we need Nodejs on our system. If you don't have Nodejs, you can install it by going to the official website.
Now create a folder and name it however you want and open it in vscode. Open the terminal and write the following command to initialize the project folder with a package.json file:
npm init -y
Now create an index.js file. After this, run the following command to install Puppeteer:
npm install --save puppeteer
Installation will take some time because it will also install chromium. So be patient.
For this particular guide, we will scrap this web page:

To keep things simple, we will only extract the title and the summary from this web page. Now open the index.js file and follow these steps:
Step 1
Require Puppeteer so that we can use it.
const puppeteer = require("puppeteer");
Step 2
Create an async function so that we can use the await keyword. This is because puppeteer uses promises.
async function scrap() {
}
scrap();
We will write the rest of the code in this function.
Step 3
Call puppeteer.launch() to launch the browser.
const browser = await puppeteer.launch();
Step 4
Call browser.newPage() to create an instance of the page.
const page = await browser.newPage();
Step 5
Call page.goto() and give the URL of the web page that we want to scrap as an argument.
await page.goto("https://www.imdb.com/title/tt1013752/");
Step 6
Call page.evaluate(). It takes a function as an argument. In this function, we can select any element from the web page. In our case, we will select the title and the summary from that web page.
Go to that web page and open the developer tools. Click on the inspect tool(on the top left corner) and then click on the title.
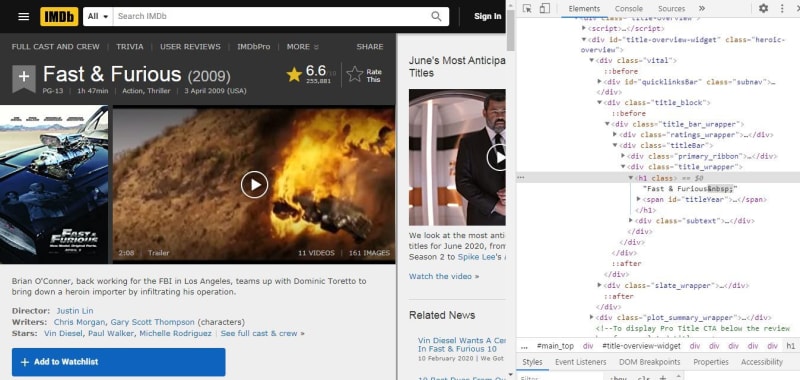
Right-click on the highlighted element on the Elements tab then click on "copy" and then click on "copy selector" to copy its css selector. In the same way, you can also copy the selector of the summary as well. Now take a look at the following code:
const data = await page.evaluate(() => {
const title = document.querySelector("#title-overview-widget > div.vital > div.title_block > div > div.titleBar > div.title_wrapper > h1").innerText;
const summary = document.querySelector("#title-overview-widget > div.plot_summary_wrapper > div.plot_summary > div.summary_text").innerText;
return {
title,
summary
}
});
In the above code, we selected the title and the summary and then stored the innerText in the variables(title and summary). After that, we returned an object(we use es6 shorthand syntax) which contains the title and summary. This object will be stored in the data variable. In the same way, you can select any element from the web page, and then whatever you will return from that function will be stored in the data variable.
Now as we have successfully extracted the data, we can do anything with it. We can store it in a CSV file or can use it for an api.
Last step
Call browser.close() to close the browser.
await browser.close();
To execute the index.js file write the following command in the terminal:
node index.js
This is how our code looks like:
const puppeteer = require("puppeteer");
async function scrap() {
// Launch the browser
const browser = await puppeteer.launch();
// Create an instance of the page
const page = await browser.newPage();
// Go to the web page that we want to scrap
await page.goto("https://www.imdb.com/title/tt1013752/");
// Here we can select elements from the web page
const data = await page.evaluate(() => {
const title = document.querySelector(
"#title-overview-widget > div.vital > div.title_block > div > div.titleBar > div.title_wrapper > h1"
).innerText;
const summary = document.querySelector(
"#title-overview-widget > div.plot_summary_wrapper > div.plot_summary > div.summary_text"
).innerText;
// This object will be stored in the data variable
return {
title,
summary,
};
});
// Here we can do anything with this data
// We close the browser
await browser.close();
}
scrap();
Conclusion
Web scraping is a fun thing to do. It has so many use cases. There are some other libraries that you can use for web scraping. However, Puppeteer makes it easier to do so. It not only allows us to do web scraping but there are some other things that we can also perform.
If you want to connect with me, follow me on twitter.

Top comments (2)
Great job , can we use Chrome instead?
html-to-pdf with puppeteer is great until you need production reliability
snapapi.pics has a PDF endpoint too — pass HTML or URL, get back a PDF. no chromium on your side