How do we leverage gRPC in a microservices architecture at Side
At Side we’ve been using gRPC along with Golang for more than a year now. A huge chunk of our internal microservices architecture relies on these technologies. We love the benefits of having a structured way to declare our services and the high performances that these technologies offer.
As you could expect, the first implementations weren’t without hiccups.
The purpose of this article is to share our experience around this topic. We will showcase what we think was good and what you should avoid if you were to start the gRPC’s adventure.
We won’t dive too much into the technologies but focus mainly on 2 different parts that we think are essential:
- Part 1 is about the developer experience we had while implementing gRPC in an already existing microservices environment.
- Part 2 is about the **DevOps toolbox **we leveraged to ensure that developers, as well as both development and production environments, were working properly with gRPC.
Part 1: The developer experience
Generated code
The first thing we had to deal with was the management of Protobuf files. In short:
Protobuf files are the description of our services’ methods and parameters.
They’re written in a neutral-language syntax that can later be used to generate code in multiple languages.
We started by putting the proto files inside the “server’s” repo because we thought that it was a good idea: Everything that was related to a given service was then contained in its repo.
However, it quickly became a pain to work with, for a few reasons:
1. The local setup We had to generate the code locally every time a change was made to the proto files. Meaning that every computer needed to be setup with the compiler and its dependencies. We could have used Docker for that but we wanted to avoid having to generate code locally as well.
While trying to find a solution for our problem, we learned how Namely managed their protobuf files from this article.
The idea is quite simple: have every service’s definition within a single repository, so whenever there is an update, it automatically populates the generated code using a Gitlab pipeline.
Generated code will then be pushed in separated repositories — one per language per service — named -.
At Side, we only generate code for Golang but it could easily be updated if needed.
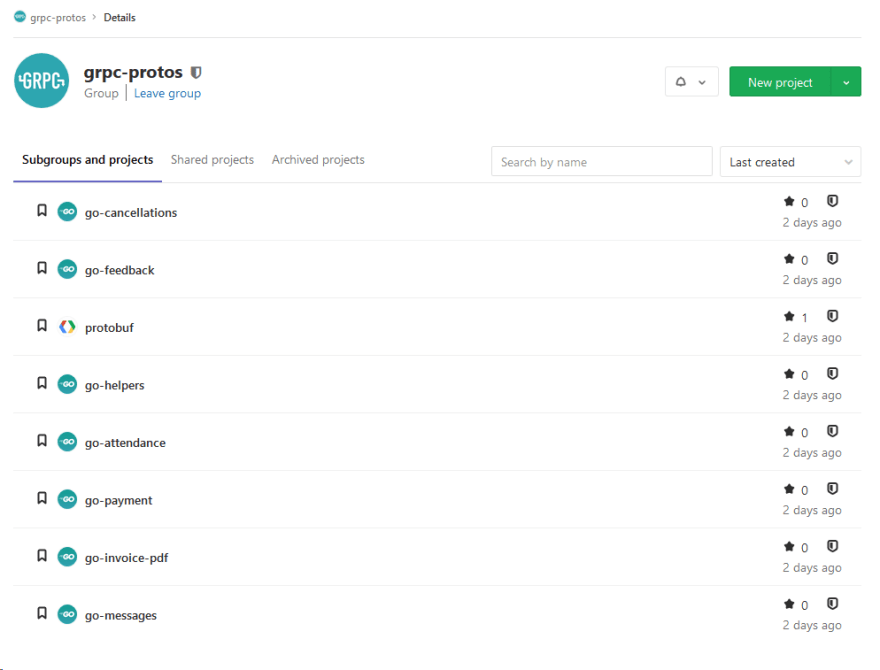
Our proto files are in the protobuf repo and as you can see on the screenshot above, all the go- are generated-code-repos that are being imported in our projects afterwards.
2. MR readability At first, we used to push the generated code within the server repo, our merge requests were including a lot of noisy code that wasn’t tied with the MR. For one line updated in the .proto file, we had at least a dozen of changes in the generated code (example of generated code).
For a few months now, we’ve been separating the service definition, the generated code and the service implementation.
As a result, our MRs only contain relevant code, are more efficient and are focused on the problems we are trying to solve through our products.
3. Documentation If you wanted to look at all the definitions of the gRPC’s services, you would have to go through all the server repos. This could be acceptable if you only have few services but when looking for scalability and efficiency, this is a blocking point.
We managed to introduce a tool so that every time you push an update of the proto files (in the single-repo) you would also generate documentation.
We are using the proto-gen-doc tool that can output the documentation in multiple formats (markdown, gitbook, html).
Error Handling
Another improvement we made along the road was the error handling in our gRPC servers.
Whenever an error was occurring on the server side, we were returning it as is.
Due to the lack of context, it was causing some frustrations when we were trying to understand why a given call was failing.
Later on, we realised that gRPC was already providing us with a solution through their status packages.
By using this package, you’ll be able to return a status code and a message, like you would do with a HTTP call.
Here’s a nice article that showcases it in a more detailed way.
API Guidelines
We know that it’s a bit obvious but we strongly recommend having guidelines on how you’ll write your proto files.
At the very least, have a naming convention for your services, methods and parameters.
We took some inspiration of what Uber’s teams are doing in terms of protobuf guidelines.
For example:
- Services should end in Service.
- Requests should end in Request.
- Responses should end in Response.
- Requests and Responses should always match the RPC name.
What are we planning to improve next?
- Tracing — We are using AWS X-Ray to track requests within our system. While it’s really simple to use along with HTTP requests, it’s more complex using gRPC. The only viable way we found so far is to make it work using gRPC Interceptors, both on clients and servers. Though, the end result lacks some information and we’ll improve this part.
- Timeout — Rely more on timeouts so that we won’t have gRPC calls lasting forever. Actually, this hasn’t happened yet, with our current usage, but we want to prepare in order to prevent future issues.
- Context — Another subject we are planning to improve is the usage of the shared client <> server context. We could add a user ID so that the server would know who’s making the request and if it’s being authorised.
Part 2: The DevOps toolbox
Implementing a new protocol
Alongside the developer benefits, what is awesome about gRPC is the additional security layer it provides.
The calls are directly handled on networks, using HTTP/2 , and are using certificates both on the client and server sides. It ensures that only wanted services can interact together.
In order to implement gRPC, the infrastructure and networking parts aren’t the hardest. Though it showed how we could leverage on previous choices that were made.
Using a local network with a dedicated gateway and a homemade DNS isn’t the best fit to connect all developers’ machines as well as testing gRPC.
Two services on the same machine will be able to communicate together, but if a gRPC client (deployed on machine A) needs to call a gRPC server (deployed on machine B), things start to become complex. Most of the time you’ll need to make this possible in production as well, in a much more complex way. You may disallow any dial withInsecure as well, and it’ll require you to create and deploy certificates.
As our workload is being handled by Swarm clusters, we are going to present the two bricks we implemented and that became our best allies during this transition.
Traefik
Do you know Traefik: the (best?) open source reverse-proxy/load balancer? If you’ve never heard of it, we recommend you to take a look at this presentation (click bottom-right to start)
When we started with gRPC’s implementation, our swarms were already using Traefik and we were not really happy at the idea of reworking it. It was an elegant and well-working solution, especially if you need to onboard a new developer within the team.
Our initial research into Traefik was a little worrying: we found only stories of people that had tried and failed to enable it properly. However, there were no worthy available alternatives, so we still proceeded with it.
Fortunately, since* Traefik* 1.5.2*, there has been good documentation on how to handle gRPC calls within its network: https://docs.traefik.io/v1.5/user-guide/grpc/.
It requires very little configuration network wise.
By doing this, you’ll have all your services on the same network and be able to interact thanks to Traefik. Now, only a good way to handle the certificates is required
** Note that with the new versions of Traefik, it’s becoming more and more smooth and fast. Give it a go! (pun intended)*
Docker Secrets
Certificates and their security are great but if you don’t know how to store them nor give them clean services’ access, you end up losing all the benefits.
As you may have one, two, three, forty-two environments to handle: pre-prod, staging, prod, maybe demos or squads environments, you most probably want to have a scalable way to handle certificates.
To answer this need, we are using Docker secrets. It’s the only solution we found to have a decent and scalable way to provide the good certificates to the corresponding services. It also provides an answer to the unmaintainable 200-lines-long switch cases you can get in configuration files.
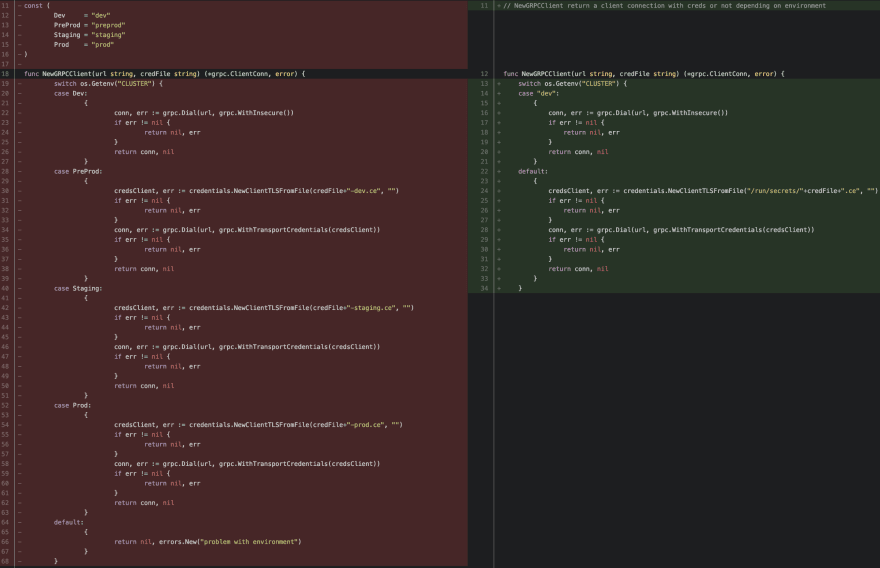
It provides us with a way to retrieve certificates, that isn’t dependent on the environments, nor the service, nor anything else.
We made certificates using OpenSSL, stored them in our swarms following the same name and being mounted at the same path* for all our services.
This way, we have a resilient way to store our certificates, encrypted on the managers. Along with the fact that we are sure to only make them available to the correct set of services.
If you are not used to using secrets, by default the path is /run/secrets/
Extra content on the topic
- Here is an interesting talk about best Practices for gRPC Services in Go.
Co-written by Bilel and Lucien of our TechOps team. Many thanks to them!
If you are interested in the subjects we are working on, feel free to have a look at our open positions.
Side
Flexible #jobs and unflexible #care for all students in Europe // #Jobs
flexibles et protection inflexible pour tous les étudiants d’Europe
Building the Future of Work





Top comments (1)
Hi!
Thanks for sharing your experience!
The link related to "Uber’s teams are doing in terms of protobuf guidelines." is broken, probably should be fixed with
github.com/uber/prototool/blob/mas...
(Seems they are working on a V2 Style Guide)