
It's easy to pay lip service to company culture. But few companies actively consider those few cultural characteristics that make a meaningful difference to performance---because that's the hard part.
For software teams, by far the biggest predictor of engineering health is ownership. In this practical guide, we'll examine exactly how you can incorporate this principle in your engineering team's day-to-day work, so that your codebase's health can take care of itself.
I'm lucky enough to meet some of the best engineers in the world as part of Stepsize's daily work. When discussing how technical debt is created with top engineers from the likes of Skyscanner, Spotify, Palantir, etc., one theme came up consistently: ownership.
In highly-collaborative, fast-moving engineering teams (i.e., modern ones) where engineers can commit to any part of the codebase, it's easy for the code to accumulate cruft and become a monster of Frankenstein-like proportions. And when things become bad enough, someone has to swoop in like Captain Marvel and fix them with a big refactoring.
To avoid this, engineering teams try to adhere to one of Robert C. Martin's ('Uncle Bob's') many brilliant pieces of advice, 'the boy scout rule': leave the code better than you found it. Here's a free VSCode extension to make this a lot easier for you.
Nevertheless, despite the skill and best intentions of engineers, it seems that an immutable law of software development is that technical debt accumulates until it becomes too much to bear and we have to carve out time for a big refactoring. We've begrudgingly accepted this as part of the software development lifecycle.
Is it simply down to a lack of discipline?I used to think so. Then I met Gareth Visagie, Chief Architect at Snyk.io, who hit me with:
Ownership is a leading indicator of engineering health.
What did he mean? And how could he make this claim?
There is an enormous amount of research showing that when team members own their work, are held accountable for it by managers, and take responsibility for successes and failures, all kinds of good stuff happens.
Unfortunately, it's hard to make this work in practice. This is partly due to the fact that, arguably, engineering productivity can't be measured, and that modern engineering practices can be interpreted as favouring weak code ownership in all situations. The truth is that, until now, it's been incredibly hard to properly measure ownership in engineering teams . . . so we didn't even know what 'good' looked like.
Luckily, recent academic research has shown that code ownership---the best proxy for the fuzzy concept that is 'ownership' in engineering teams---can be measured from Git commit activity. And it's a great leading indicator of your codebase's health.
Those parts of the codebase that receive contributions from many people accumulate cruft over time, while those receiving contributions from fewer people tend to be in a better state. Don't just take it from me---the good folk of Microsoft looked into this themselves.

Credit: Microsoft research
I can already hear some of you screaming that you don't want just one developer being the only person allowed to touch a piece of code---there are nasty downsides to this. I hear you, and that's not what we're proposing.
Hear me out.
Types of code ownership
There are different types of code ownership, suitable for different situations.
Collaborative ownership vs. Non-ownership
Colaborative ownership ---[ . . . ] an ownership where code is collectively owned, but responsibilities and schedules are clear. Each team member can work across subsystems or services as needed.*
Non-ownership ---[. . . ] a situation in which several developers make changes to the same subsystem but with minimal coordination or accountability for quality or team communication. In such systems, one might expect the quality to be low.*
Source: Microsoft research
We can break this down further, adding orphaned code and absolute ownership to the mix, but I don't want to bury the lede, so here's a graph illustrating the code ownership spectrum:
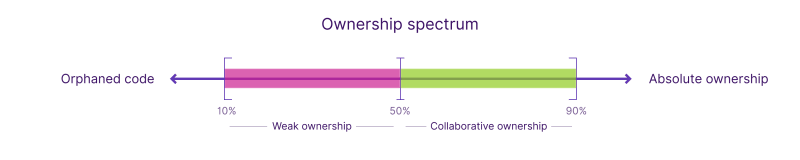
Collaborative ownership should be your default for most situations and what you strive for. Note that this doesn't mean only one engineer on your team has permission to modify the code, or that their approval is mandatory for any modification. It simply means that every engineer is absolutely clear on who they should speak to if they have any questions, and that the owner is probably the best person to review the code. In this way, they can enforce coding standards and be aware of how the code they own has been modified.
The code owner is responsible for the state of their code and managers should hold them accountable for it. This doesn't mean that they should get bashed on the head for every bug that creeps in, but it does mean that the code owner is empowered to make decisions relating to code quality and technical debt; they will be held accountable for these decisions using additional supporting metrics such as cohesion and churn (see more in our article about technical debt metrics).
Non-ownership, or weak ownership, is the opposite of collaborative ownership and should be avoided in most situations. That being said---and this might be stating the obvious---it's fine if files like package.json don't have a clear owner. There's no need to be overzealous.
Orphaned code
This is the nasty type of non-ownership, one of the extremes on the code ownership spectrum. It's the one you really don't want. Avoid it at all cost . . . unless it's code you'll never touch again. But that's pretty rare.
Code is considered orphaned when the main contributor has ceased contributing to the codebase. They may have left the organisation, or moved from coding to management. Either way, you---and your codebase---are in trouble.
But there's a solution for this too. You need to transition the orphaned code to whichever other type of ownership is most appropriate for it. To avoid having any orphaned code in your codebase, make sure that your off-boarding and handover plans include the main owner bringing the new code owners up to speed. Ease them in by automatically assigning them to review pull requests that modify the code. Failing that, you can simply assign code ownership however you see fit.
Whichever method you choose, don't leave orphaned code loitering in your codebase. You never know what might happen when it's left to its own devices.
Absolute ownership
This is the other extreme on the code ownership spectrum. It can be fantastic. It can also spell trouble.
Code is considered absolutely owned when the owner is the only engineer who can modify or approve modifications to it, or when the owner is essentially the only engineer who ever modified it in the past.
Small startups often see this pattern in their data. Each engineer tends to be responsible for the full history of a file and is expected to maintain this ownership. It's not the end of the world; startups have limited resources after all, and sacrifices need to be made. But if the engineer ever got run over by a bus, this part of the codebase will be orphaned. You should have a contingency plan.
In larger engineering organisations, a low 'bus factor' can be a real problem, especially when it relates to critical parts of the codebase, when employee churn is high, and if the company has taken on too much technical debt. For example, if the engineer who cobbled together your whole custom payments system leaves, you've got a big headache if you want to modify your pricing model---or if you realise there's a bug in the codebase, which has been undercharging your biggest customers for months. Either somebody's going to have to try and understand the code to modify it, or you're going to have to declare technical bankruptcy on your payments system and rewrite it (but before you do, please consider this).
Don't let it happen to you.
But there are situations where absolute ownership is acceptable and even recommended. You might want absolute ownership on those 'if this thing fails we can pack our bags because the business won't be able to pay our salaries or because we're going to prison' parts of the codebase.
In these cases, even though you want to spread knowledge of the critical code among a few engineers to maintain a healthy bus factor, you may want to consider setting up rules to prevent PR being merged without the approval of the absolute owner.
Takeaways
Aim for collaborative ownership for the vast majority of the files in your codebase (50%--90% code ownership for any given file), and be more disciplined to increase code ownership and reduce technical debt wherever appropriate.
Benefits will include:
Higher coding standards, properly maintained. It's easier to maintain high standards in a small, well-informed group. This applies not just to engineers modifying code they own, but also to reviewing their colleagues' code when it modifies their ownership areas.
Easier communication. Explicit and clear ownership means that every engineer in the team knows who's best placed to answer their questions.
More focused and impactful refactoring. When you decide to pay back some technical debt, strong code owners are best placed for the job. Use ownership, cohesion, and code churn metrics to triangulate on problem areas in your codebase. Your engineers will use their technical debt budget wisely and they'll never waste time paying back the wrong technical debts again.
The bus factor will never get out of hand. You can use code ownership to inform knowledge-sharing in the organisation. If ownership is too high, assign other engineers to code reviews and tasks that modify the code in question. You'll gradually improve your ownership scores, which will lead to increased code quality and less technical debt.
Like anything that's worth doing, creating---and sticking to---an engineering culture of code ownership takes time and effort, but it'll pay back in spades. It directly impacts virtually any engineering health KPI you can imagine. Bake it into your culture, and it'll become a giant competitive advantage for the long-term.
Also, we built a SaaS product to do all that for you, you can try it out here :)





Top comments (1)
I like this. I'm actually trying to enforce it in the company I work at and I couldn't find any evidence of anyone else doing the same thing.
It makes sense though even just for merge conflicts... If everyone edits whatever they want, we'll have pointless formatting merge conflicts and other types of such waste of time