Overview of My Submission
Atlas Search is one of MongoDB's most powerful features.
The choice for a project was to build a database cluster and use Atlas to search it.
But what information should we gather for our MongoDB?
Project Gutenberg has been chosen as the project's source for data.
Why? Because everyone loves books and free stuff!
Here's the code: https://github.com/timonvogel/gutenberg-search
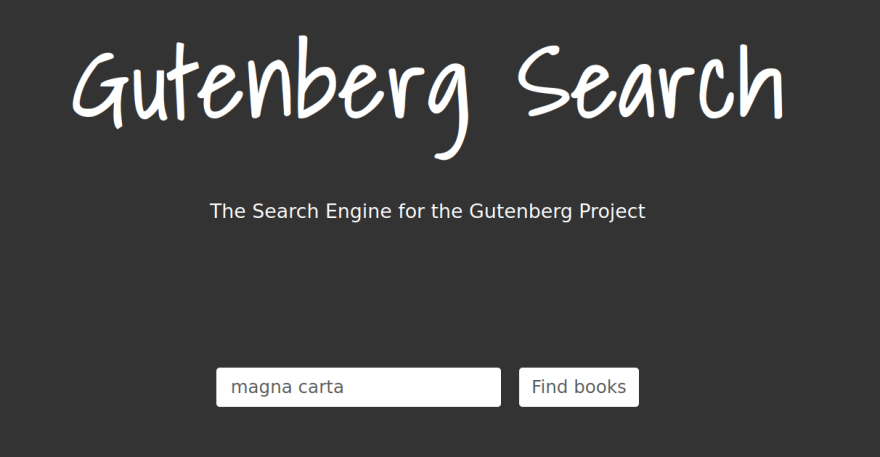
The Web Application
The web application is a straightforward Python Flask app. It routes just the index page and two simple templates. On it is a search box with the results below it.
Dealing with MongoDB and Atlas Search, which I will cover in the next parts, was the most interesting part.
MongoDB Gutenberg Cluster
I began by following MongoDB's excellent tutorial offered by MongoDB docs.atlas.mongodb.com. After playing around with a test cluster, I went ahead and built the real cluster as well as a user with write access.
It was rather straightforward, particularly in terms of connecting to the cluster using pymongo and the connection string.
The connection string was kept in a separate file called _secrets.py:
import pymongo
import _secrets
client = pymongo.MongoClient(_secrets.connection_string)
books = client.gutenberg.books
This is how the application accesses the Gutenberg cluster.
Populating with Data
There is a handy repository for downloading the whole Gutenberg Project database: https://github.com/pgcorpus/gutenberg.
The metadata I needed was obtained by running the get_data.py script.
Then it was just a matter of writing a little script to parse the csv data and push it to my new Gutenberg cluster.
for row in csv_it:
if len(books_buffer) > BOOKS_BUFF_LEN:
books.insert_many(books_buffer)
book_info = {
"book_id":row[0],
"title":row[1],
"author":insert_author((row[2], row[3], row[4])),
"language":row[5],
"subjects":row[7],
}
books_buffer.append(book_info)
Note how the whole buffer is inserted with just one command: books.insert_many(books_buffer)
Script: https://github.com/timonvogel/gutenberg-search/blob/main/metadata_to_mongodb.py
Fetching Gutenberg Books
When a user submits the search form the value is saved in a URL parameter that is visible to the server. It is then supplied to the atlas_search function where the Atlas Search is performed. The code looks like the following:
results = books.aggregate([
{
'$search': {
'index': 'default',
'text': {
'query': search_term,
'path': {
'wildcard': '*'
}
}
}
}, {
'$limit': 20
}, {
'$project': {
"title": 1,
"author": 1,
"book_id": 1,
"subjects": 1,
"_id": 0
}
}
])
The search term was a little tough to get correct, however the Atlas Search documentation helped me with some examples: https://docs.atlas.mongodb.com/atlas-search/index-definitions/
In the example above the search index default is used and the query string is stored in the variable search_term. The other important thing is the path field since it controls which data fields Atlas Search will index. I ended up with many blank responses because I messed this field up in the beginning.
Putting it together
Everything appeared to be ready when the Atlas query was implemented!
MongoDB was ready to provide the data, and the web application was ready to display the results.
In the search.html template, I programmed a simple results display, making sure it doesn't allow any invalid inputs and can handle connections.
Lessons learned
Is there anything I've learned from it?
Without a doubt!
Once you've mastered the fundamentals of MongoDB (and there isn't much to learn), you'll be tempted to use it for your next project instead of, say, MySQL, which requires you to deal with datatypes and sophisticated query expressions.
MondoDB is a lot easier to use, which I really appreciate.
I'm also glad to have Python Flask on hand, which helps me to quickly construct simple web applications.
This allowed me to concentrate on the most crucial aspect of the project, MongoDB and Atlas Search.
During this endeavor, I also found the MongoDB web interface. It came in handy in a variety of ways, but especially when it came to testing Atlas Search queries.
https://github.com/timonvogel/gutenberg-search
Submission Category:
This would be the own adventure thing though it's Atlas Search.
Link to Code
 timonvogel
/
gutenberg-search
timonvogel
/
gutenberg-search
Web application to search the Gutenberg Project's database, made with Python Flask and MongoDB

Gutenberg Search
A simple MonogDB web application.
About
This is a straightforward search interface for the Project Gutenberg database. It features a more appealing look than the original gutenberg.org website.
The data is stored in a MongoDB cluster and was retrieved using the scripts from the following repository: github.com/pgcorpus/gutenberg
The stack of this application can be summarized as follows:
docker-container{ python-flask --> uwsgi --> nginx --> :80 }.
The server connects to the MongoDB cluster perform an Atlas Search query for each response.
Installation
Install the python modules flask and pymongo.
pip: pip install flask pymongo
Clone this repo and follow the Development and deployment section.
Creating a Gutenberg MongoDB cluster
The result of this step is publicly available. To find the cluster and access credentials, look through the source code.
If you want to reproduce this work, follow these steps: :
git clone github.com/pgcorpus/gutenberg- Run
python get_data.py…

Top comments (0)