Smart Stocks with FLaNK (NiFi, Kafka, Flink SQL)

I would like to track stocks from IBM and Cloudera frequently during the day using Apache NiFi to read the REST API. After that I have some Streaming Analytics to perform with Apache Flink SQL and I also want permanent fast storage in Apache Kudu queried with Apache Impala.
Let's build that in the cloud in seconds.
*Source Code: * https://github.com/tspannhw/SmartStocks
To Script Loading Schemas, Tables, Alerts see scripts/setup.sh:
*Source Code: * https://github.com/tspannhw/ApacheConAtHome2020
- Kafka Topic
- Kafka Schema
- Kudu Table
- Flink Prep
- Flink SQL Client Run
- Flink SQL Client Configuration
Once our automated admin has built our cloud environment and populated it with the goodness of our app, we can being out continuous sql.

If you know your data, build a schema, share to the registry
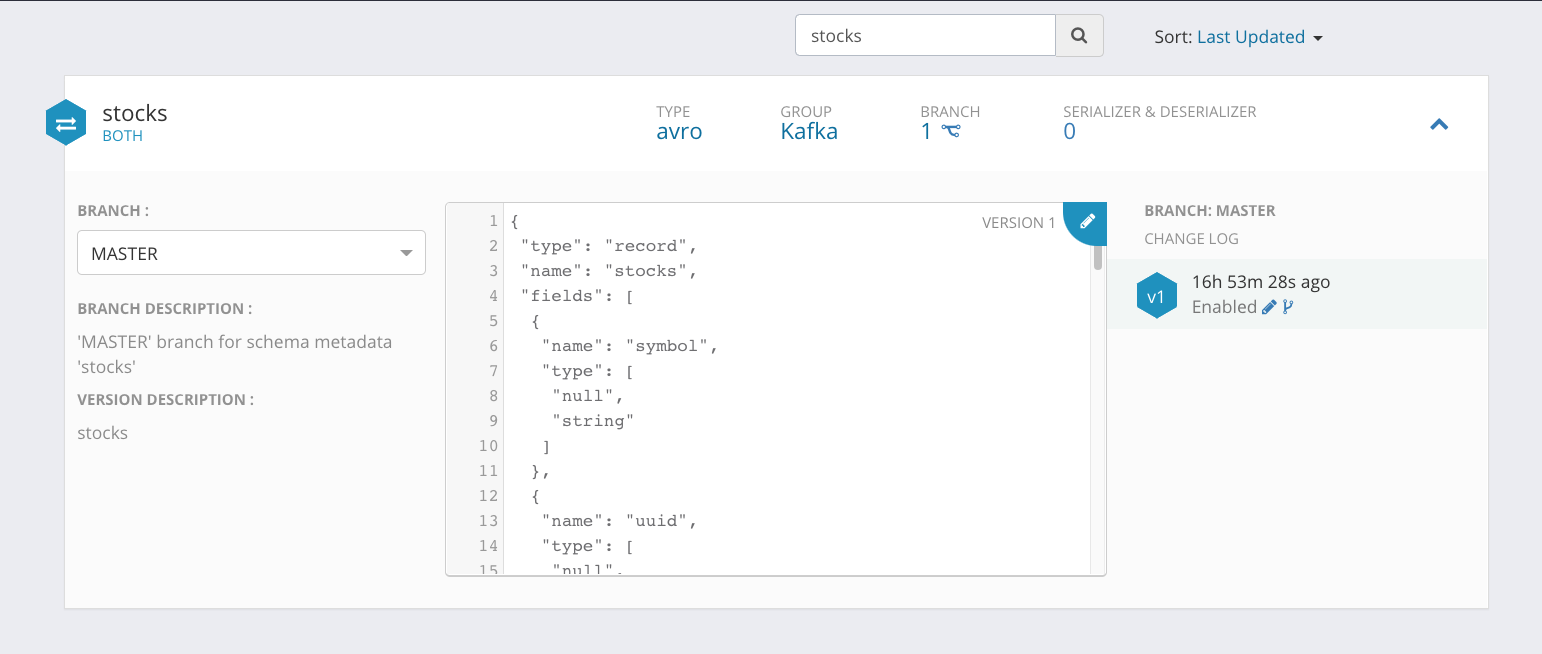
One unique thing we added was a default value in our Avro schema and making it a logicalType for timestamp-millis. This is helpful for Flink SQL timestamp related queries.
{ "name" : "dt", "type" : ["long"], "default": 1, "logicalType": "timestamp-millis"}
You can see the entire schema here:
https://raw.githubusercontent.com/tspannhw/SmartStocks/main/stocks.avsc
We will also want a topic for Stock Alerts that we will create later with Flink SQL, so let's define a schema for that as well.
https://raw.githubusercontent.com/tspannhw/SmartStocks/main/stockalerts.avsc
For our data today we will use AVRO data with AVRO schemas for use inside Kafka topics and whoever will consume it.
How to Build a Smart Stock DataFlow in X Easy Steps
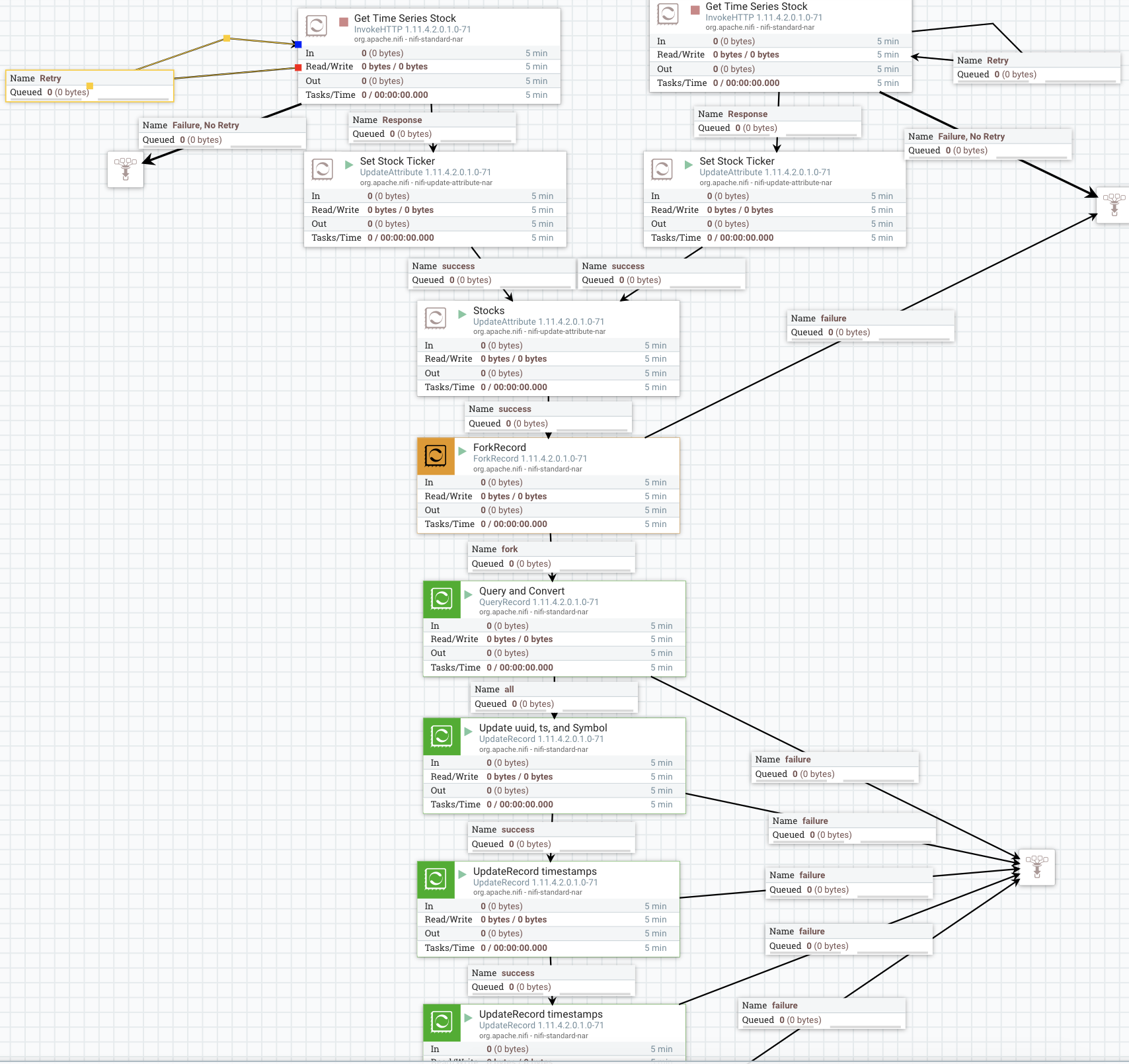
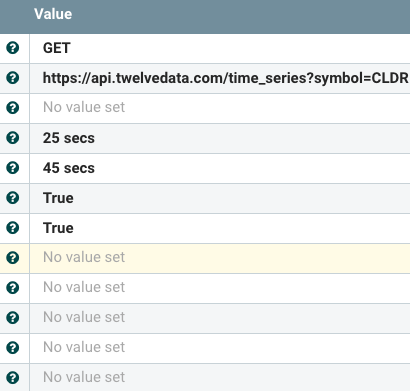
- Retrieve data from source (example: InvokeHTTP against SSL REST Feed - say TwelveData) with a schedule.
- Set a Schema Name ( UpdateAttribute )
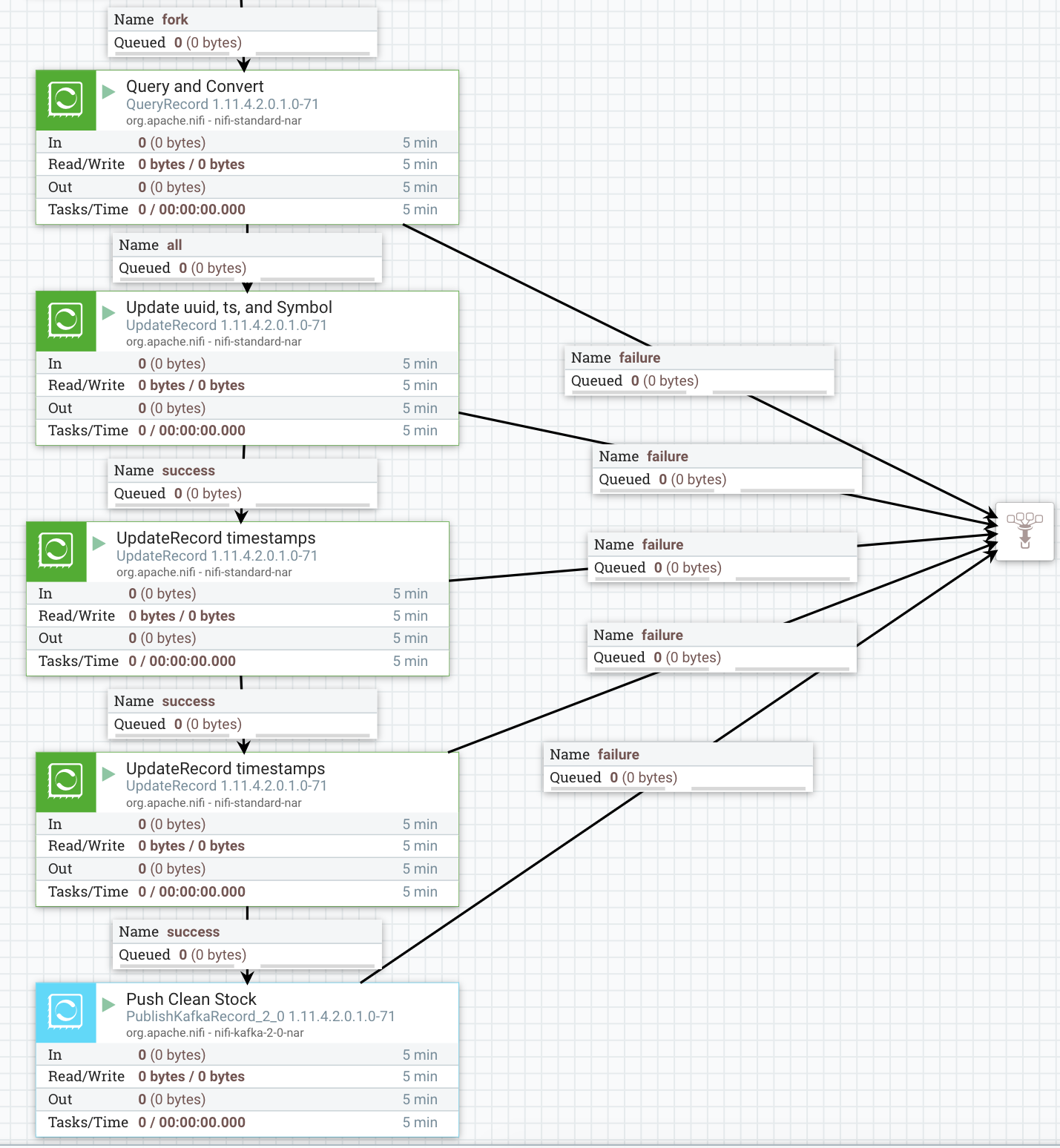
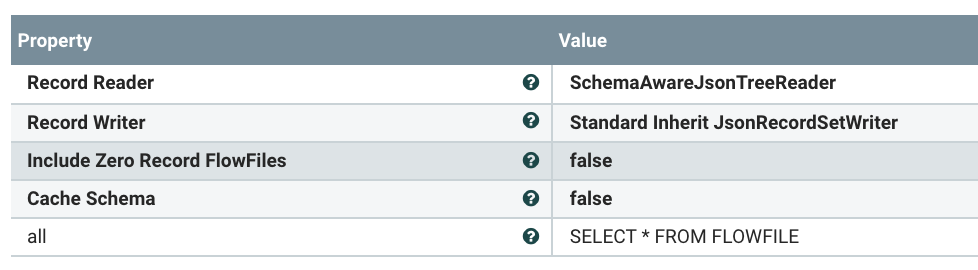
- ForkRecord : We use this to split out records from the header (/values) using RecordPath syntax.
- QueryRecord : Convert type and manipulate data with SQL. We aren't doing anything in this one, but this is an option to change fields, add fields, etc...
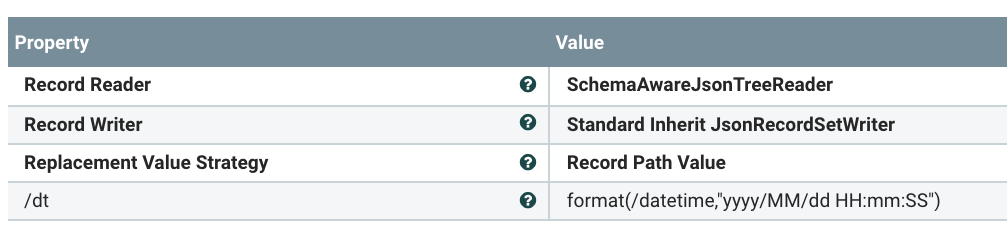
- *UpdateRecord: * This first one I am setting some fields in the record from attributes and adding a current timestamp. I also reformate by timestamp for conversion.
- UpdateRecord : I am making dt make numeric UNIX timestamp.
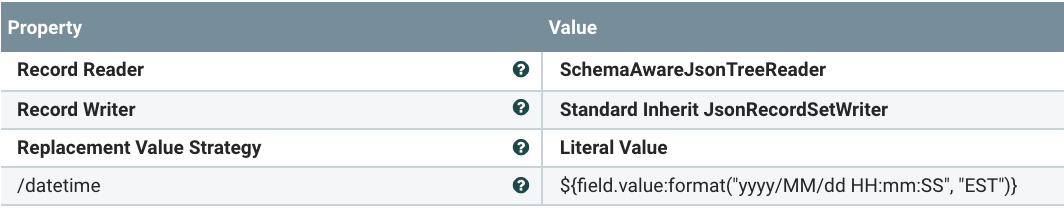
- UpdateRecord : I am making datetime my formatted String date time.
- (LookupRecord): I don't have this step yet as I don't have an internal record for this company in my Real-Time Data Mart. https://docs.cloudera.com/runtime/7.0.3/kudu-overview/topics/kudu-architecture-cdp.html. I will probably add this step to augment or check my data.
- ( ValidateRecord ): For less reliable data sources, I may want to validate my data against our schema, otherwise we will get warnings or errors.
- PublishKafkaRecord_2_0: ** Convert from JSON to AVRO, send to our Kafka topic with headers including reference to the correct schema **stocks and it's version 1.0.


Now that we are streaming our data to Kafka topics, we can utilize it in Flink SQL Continuous SQL applications, NiFi applications, Spark 3 applications and more. So in this case CFM NiFi is our Producer and we will have CFM NiFi and CSA Flink SQL as Kafka Consumers.
We can see what our data looks like in the new cleaned up format with all the fields we need.
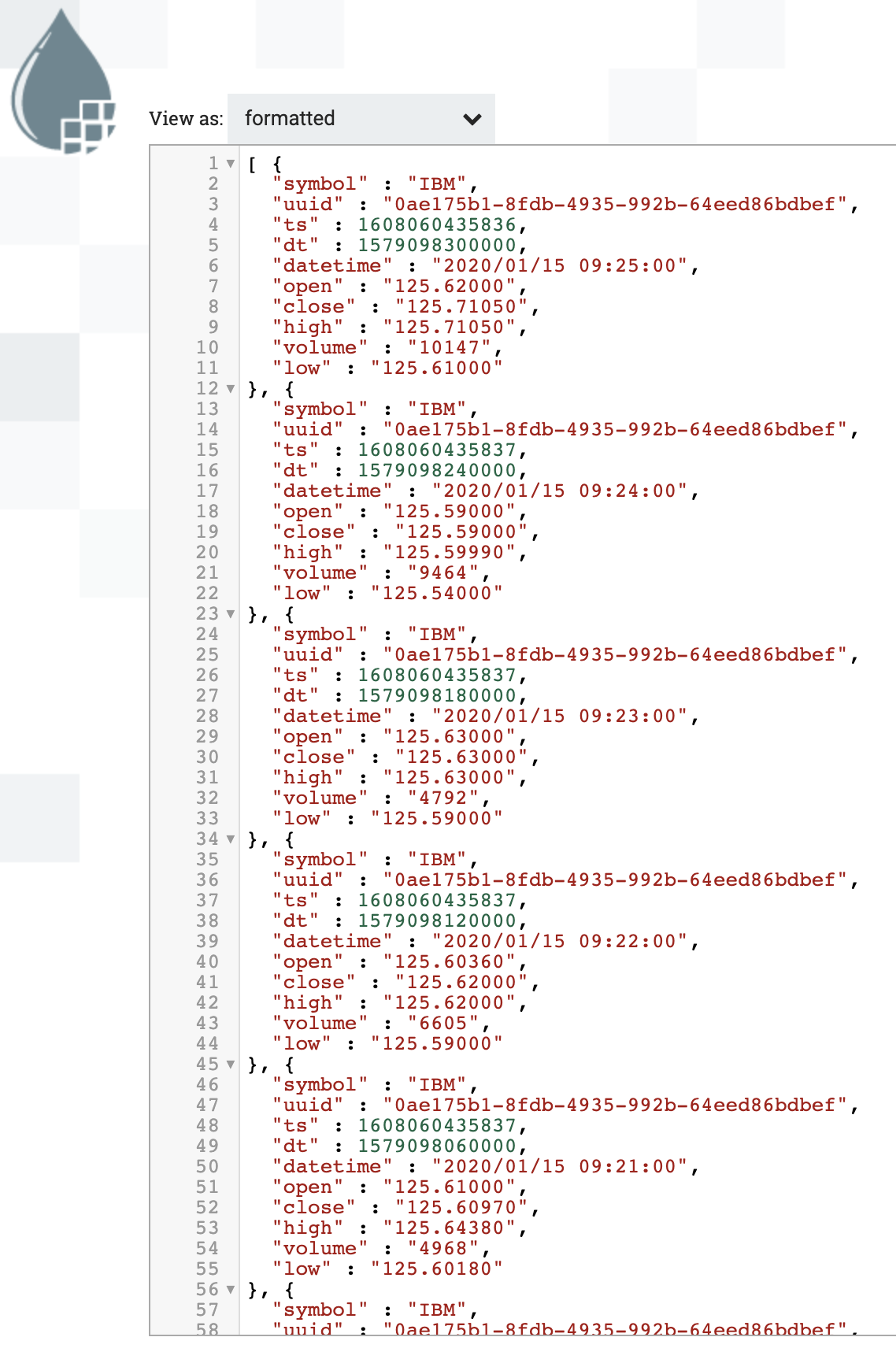
Viewing, Monitoring, Checking and Alerting On Our Streaming Data in Kafka
Cloudera Streams Messaging Manager solves all of these difficult problems from one easy to use pre integrated UI. It is pre-wired into my Kafka Datahubs and secured with SDX.
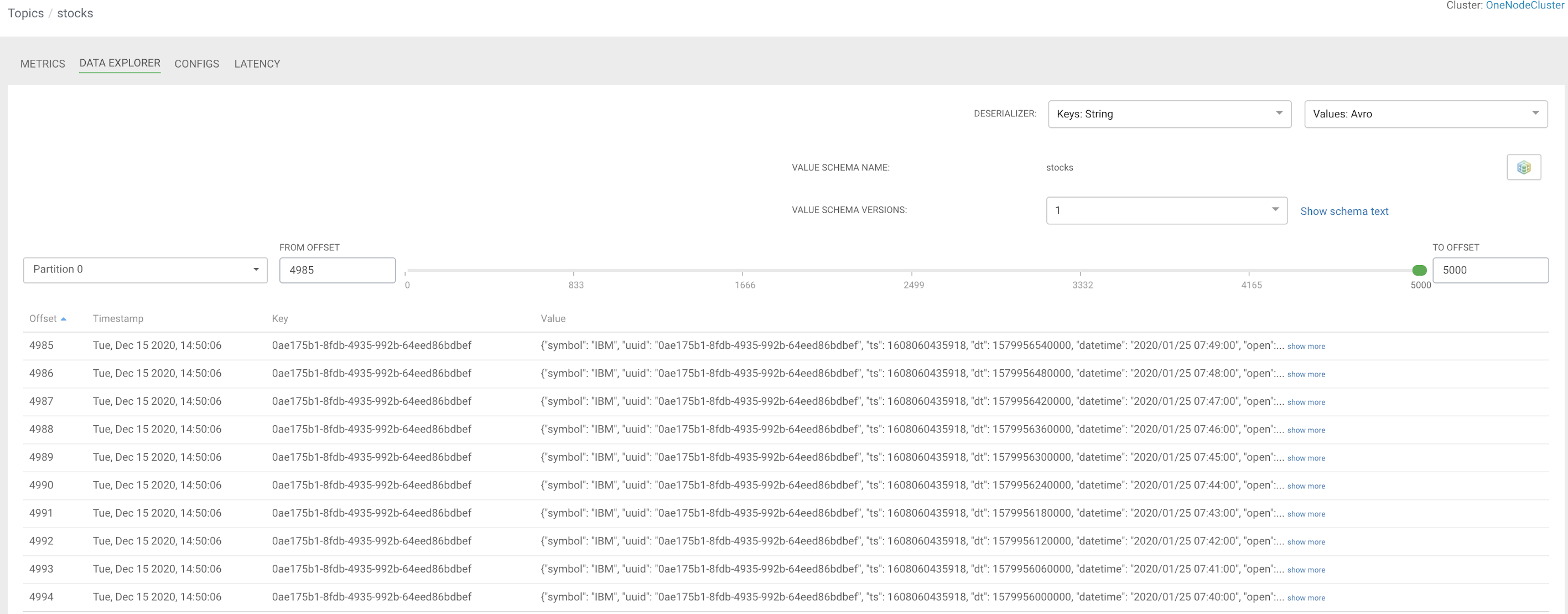
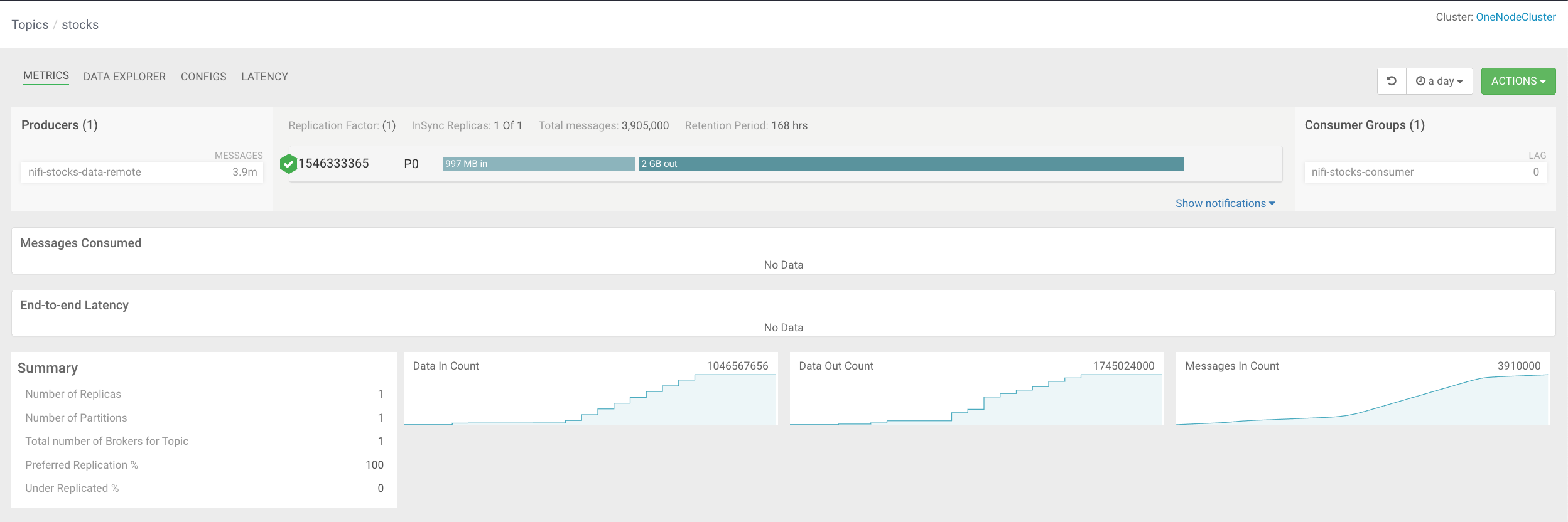
I can see my AVRO data with associated stocks schema is in the topic, ready to be consumed. I can then monitor who is consuming, how much and if there is a lag or latency.
How to Store Our Streaming Data to Our Real-Time DataMart in the Cloud
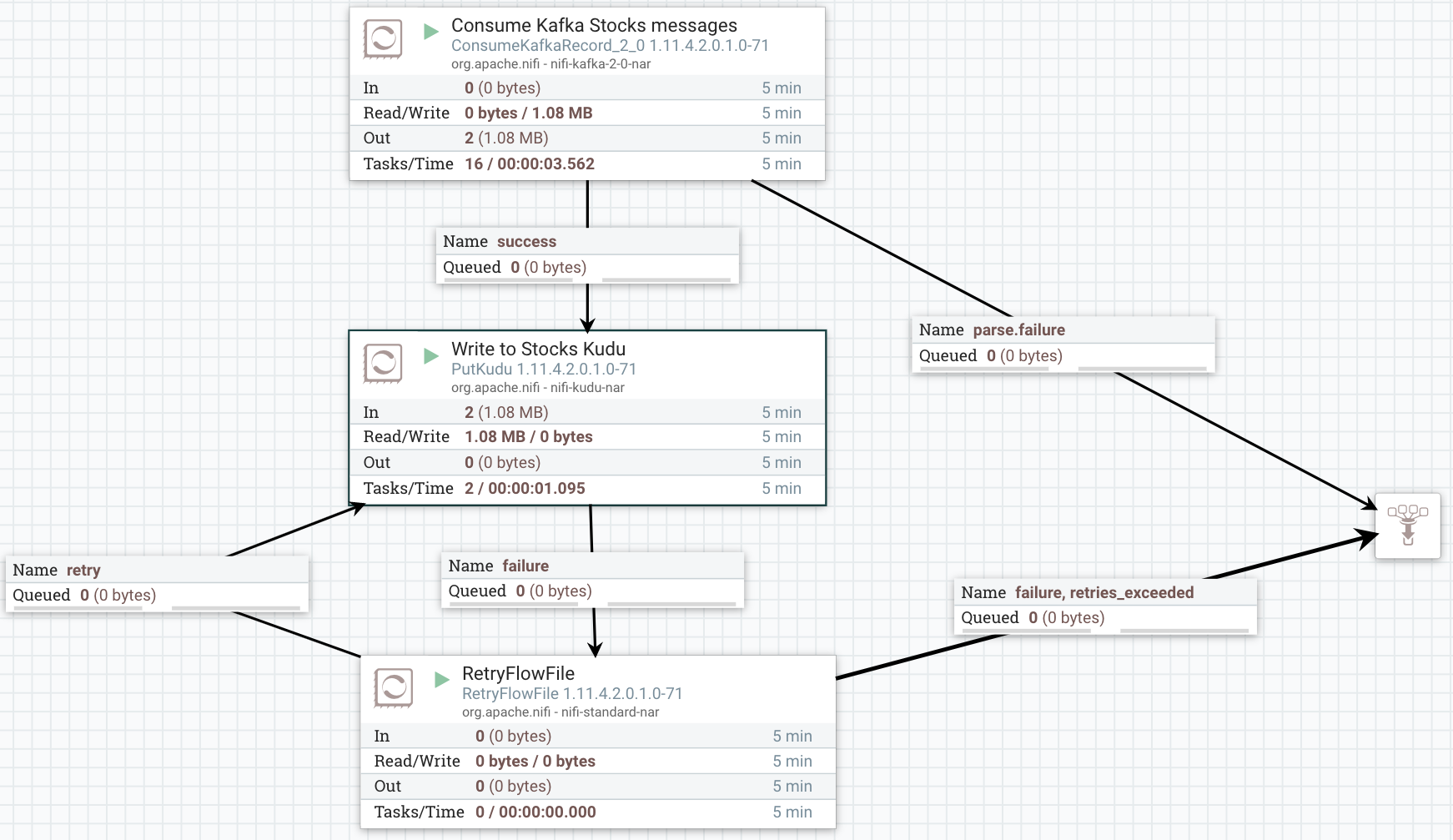
Consume stocks AVRO data with stocks schema then write to our Real-Time Data Mart in Cloudera Data Platform powered by Apache Impala and Apache Kudu. If something failed or could not connect, let's retry three times.
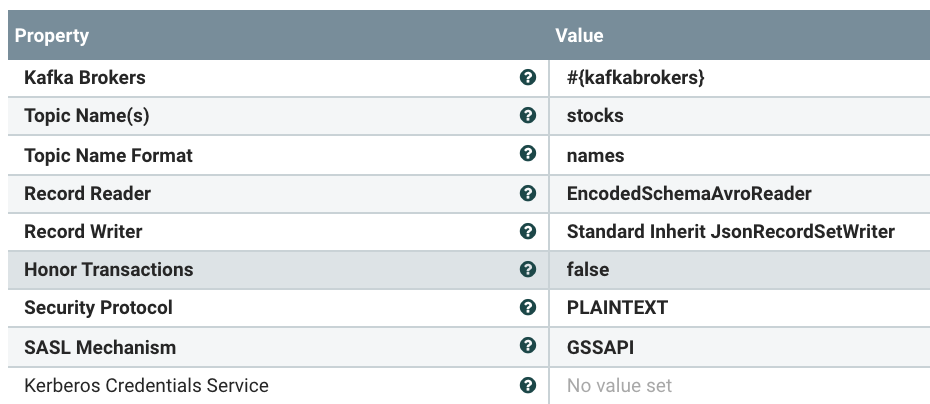
We use a parameter for our 3+ Kafka brokers with port. We could also have parameters for topic names and consumer name. We read from stocks table which uses stocks schema that is referenced in Kafka header automatically ready by NiFi. When we sent message to Kafka, nifi passed on our schema name via schema.name attribute in NiFi. As we can see it was schema attached Avro, so we use that Reader and convert to simple JSON with that schema.

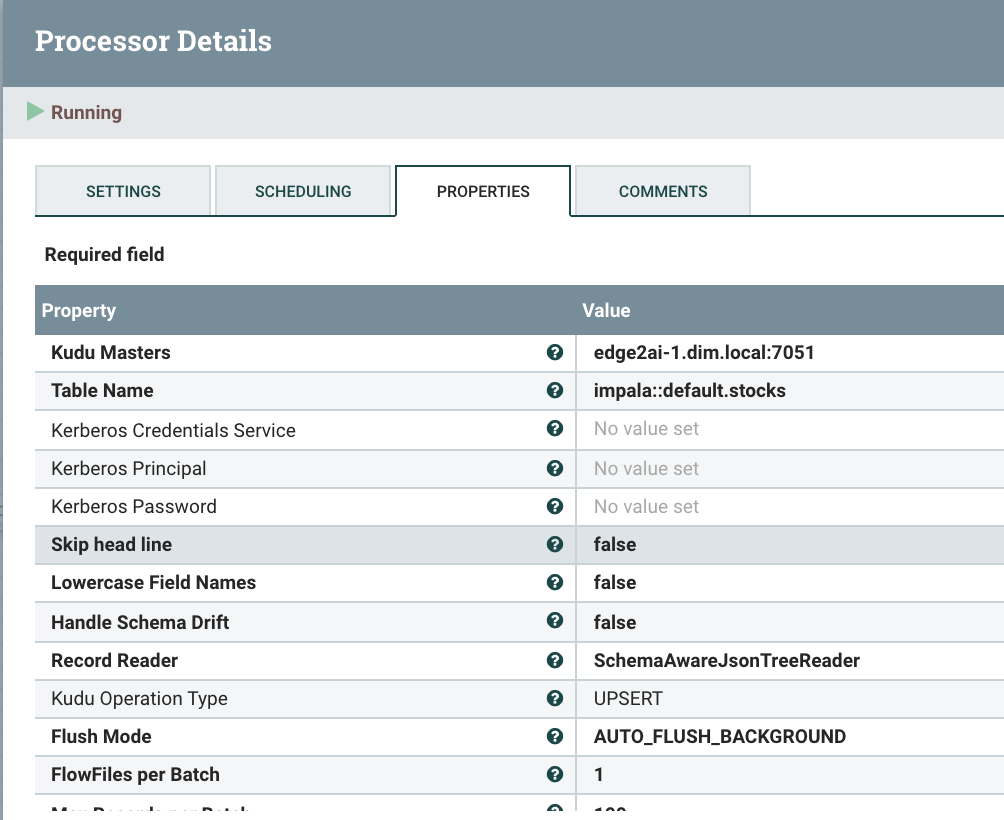
Writing to our Cloud Native Real-Time Data Mart could not be simpler, we reference the table stocks we have created and have permissions to and use the JSON reader. I like UPSERT since it handles INSERT AND UPDATE.
First we need to create our Kudu table in either Apache Hue from CDP or from the command line scripted. Example : impala-shell -i edge2ai-1.dim.local -d default -f /opt/demo/sql/kudu.sql
CREATE TABLE stocks
(
uuid STRING,
datetimeSTRING,
symbolSTRING,
openSTRING,
closeSTRING,
highSTRING,
volumeSTRING,
tsTIMESTAMP,
dtTIMESTAMP,
lowSTRING,PRIMARY KEY (uuid,
datetime) )PARTITION BY HASH PARTITIONS 4
STORED AS KUDU TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');
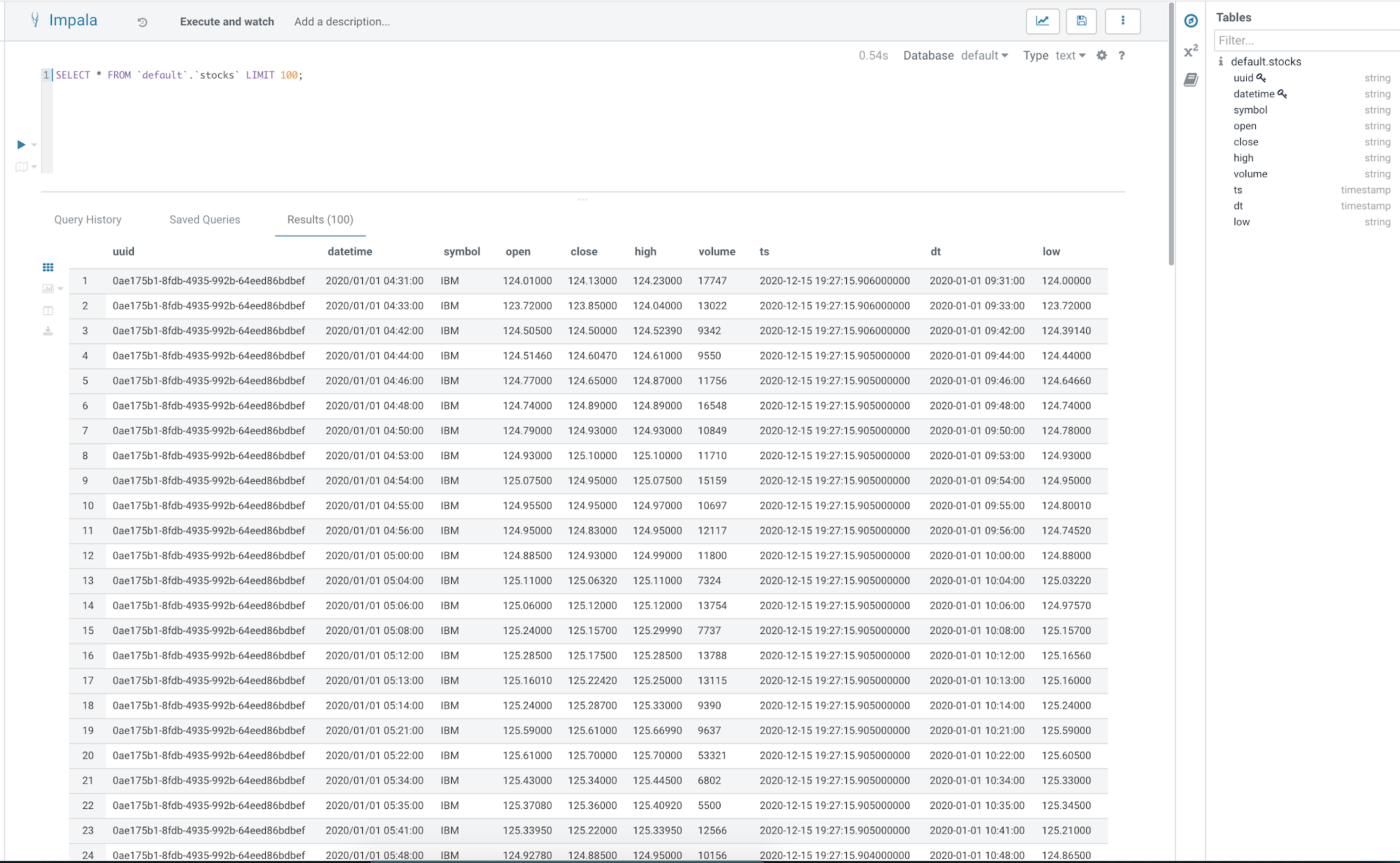
Using Apache Hue integrated in CDP, I can examine my Real-Time Data Mart table and then query my table.
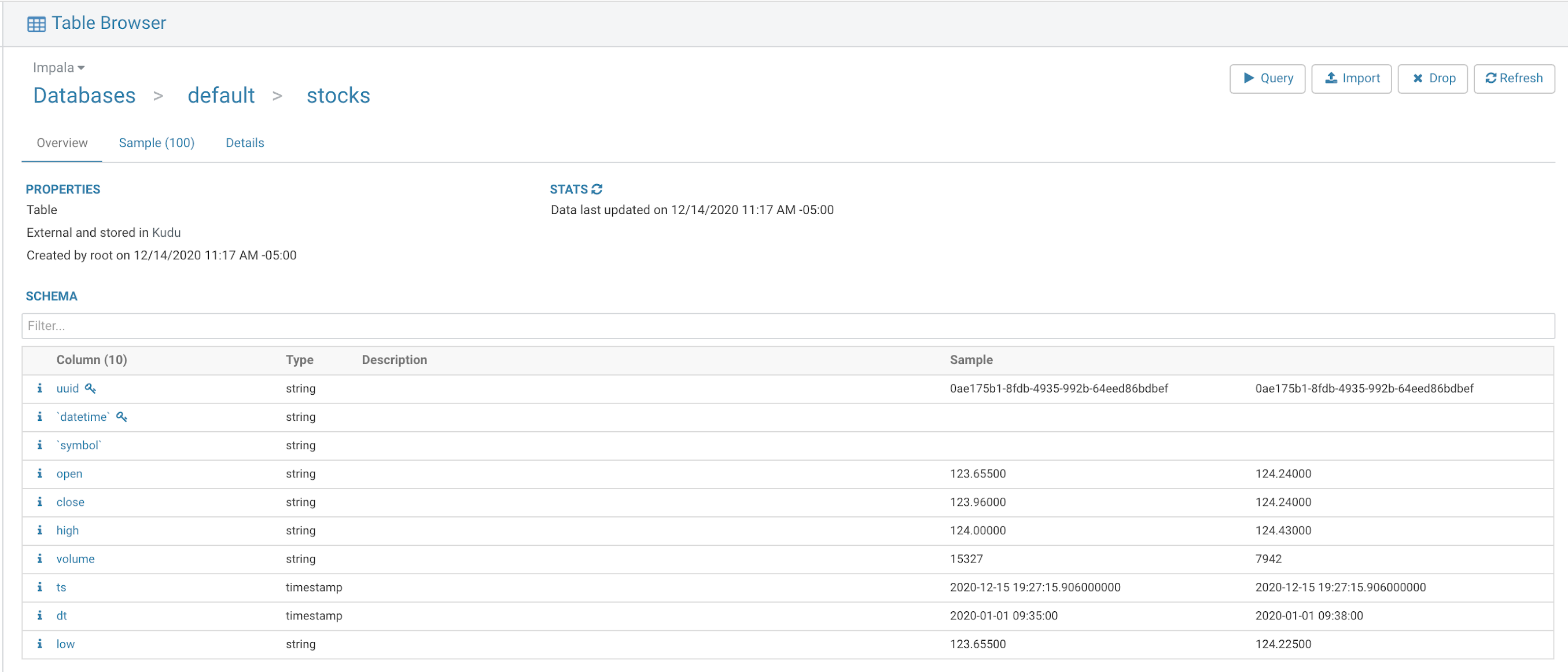
My data is now ready for reports, dashboards, applications, notebooks, web applications, mobile apps and machine learning.
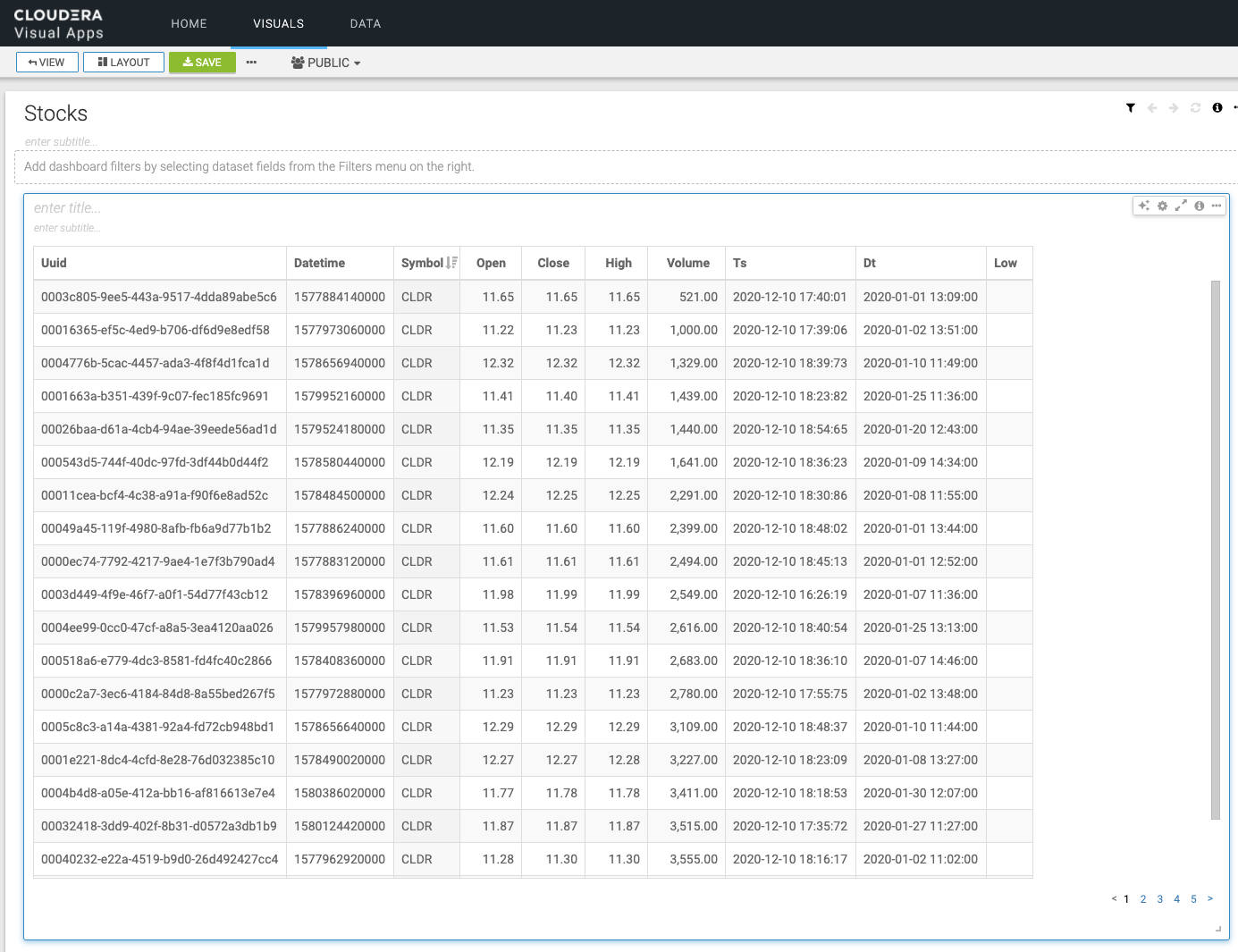
I can now spin up a Cloudera Visual Application on this table in a few seconds.
Now we can build our streaming analytics application in Flink.
How to Build a Smart Stock Streaming Analytics in X Easy Steps
I can connect to Flink SQL from the command line Flink SQL Client to start exploring my Kafka and Kudu data, create temporary tables and launch some applications (insert statements). The environment lets me see all the different catalogs available including registry (Cloudera Cloud Schema Registry), hive (Cloud Native Database table) and kudu (Cloudera Real-Time Cloud Data Mart) tables.
Run Flink SQL Client
It's a two step process, first setup a yarn session. You may need to add your Kerberos credentials.
flink-yarn-session -tm 2048 -s 2 -d
Then launch the command line SQL Client.
flink-sql-client embedded -e sql-env.yaml
See: https://docs.cloudera.com/csa/1.2.0/sql-client/topics/csa-sql-client-config.html
https://docs.cloudera.com/csa/1.2.0/sql-client/topics/csa-sql-security.html
Run Flink SQL
Cross Catalog Query to Stocks Kafka Topic
select * from registry.default_database.stocks;
Cross Catalog Query to Stocks Kudu/Impala Table
select * from kudu.default_database.impala::default.stocks;
Default Catalog
use catalog default_catalog;
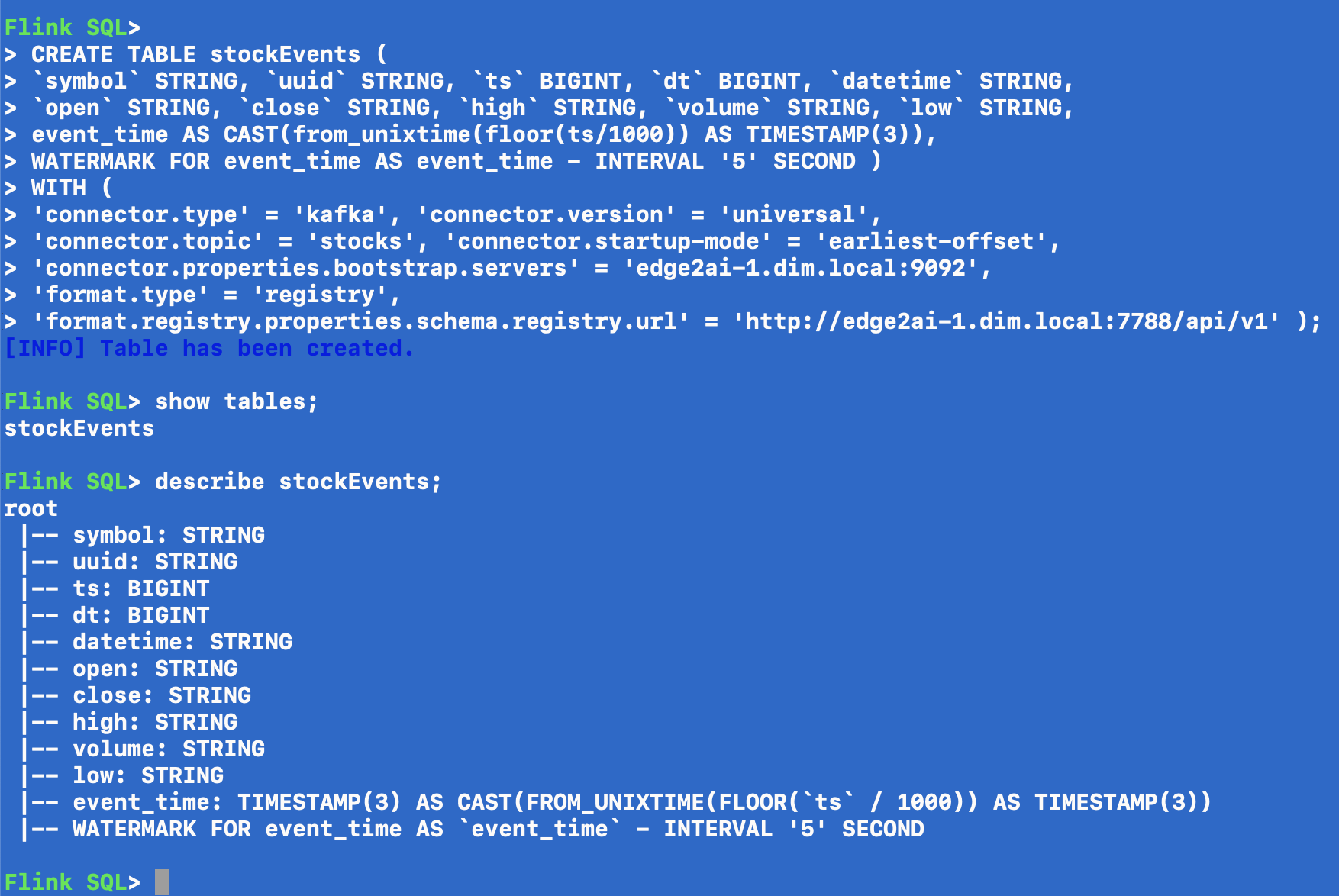
CREATE TABLE stockEvents ( symbol STRING, uuid STRING, ts BIGINT, dt BIGINT, datetime STRING, open STRING, close STRING, high STRING, volume STRING, low STRING,
event_time AS CAST(from_unixtime(floor(ts/1000)) AS TIMESTAMP(3)),
WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND )
WITH ( 'connector.type' = 'kafka', 'connector.version' = 'universal',
'connector.topic' = 'stocks',
'connector.startup-mode' = 'earliest-offset',
'connector.properties.bootstrap.servers' = 'edge2ai-1.dim.local:9092',
'format.type' = 'registry',
'format.registry.properties.schema.registry.url' = 'http://edge2ai-1.dim.local:7788/api/v1' );
show tables;
Flink SQL> describe stockEvents;
root |-- symbol: STRING |-- uuid: STRING |-- ts: BIGINT |-- dt: BIGINT |-- datetime: STRING |-- open: STRING |-- close: STRING |-- high: STRING |-- volume: STRING |-- low: STRING |-- event_time: TIMESTAMP(3) AS CAST(FROM_UNIXTIME(FLOOR(ts / 1000)) AS TIMESTAMP(3)) |-- WATERMARK FOR event_time AS event_time - INTERVAL '5' SECOND
We added a watermark and event time pulled from our timestamp.
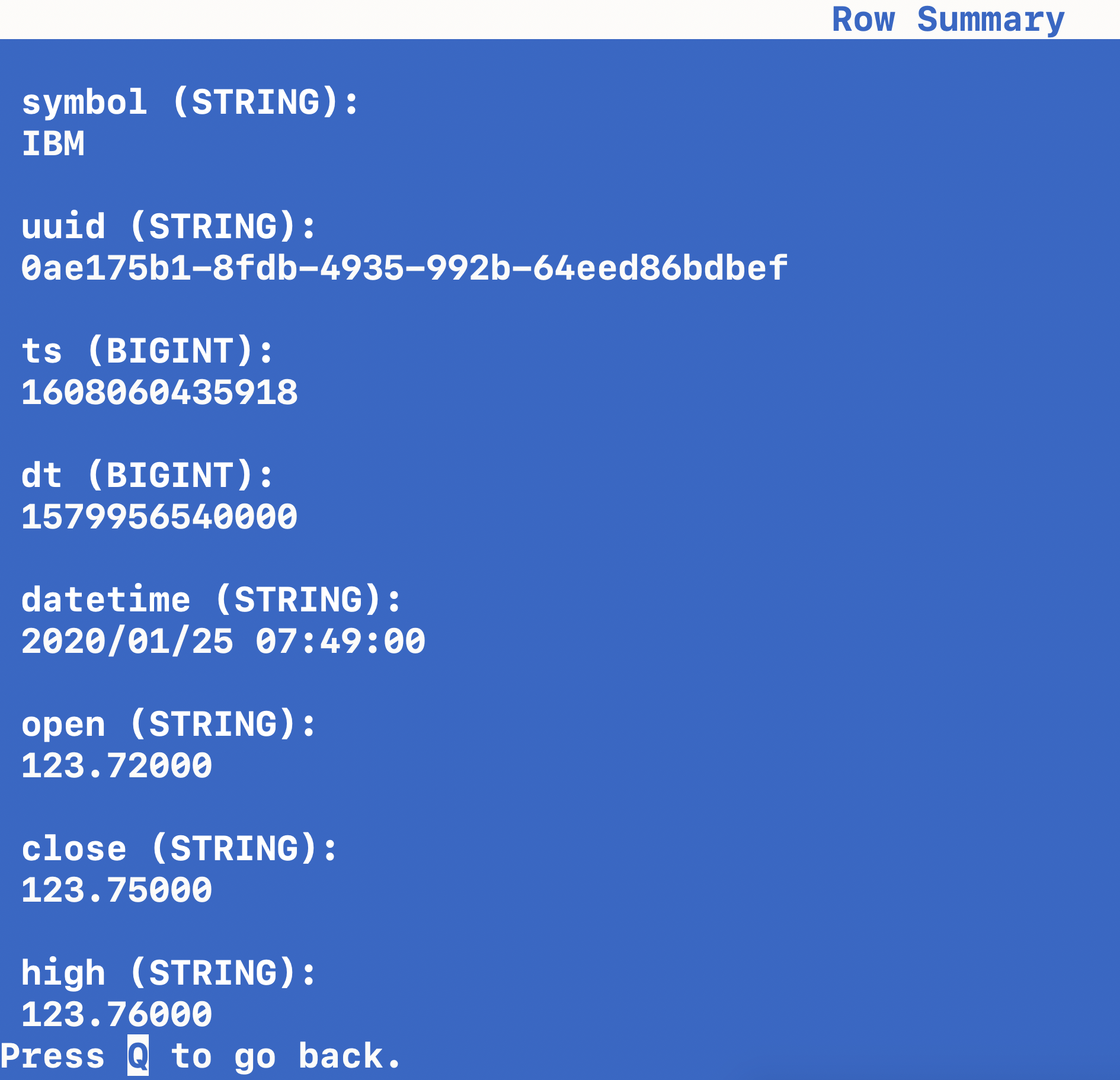
Simple Select All Query
select * from default_catalog.default_database.stockEvents;
We can do some interesting queries against this table we created.
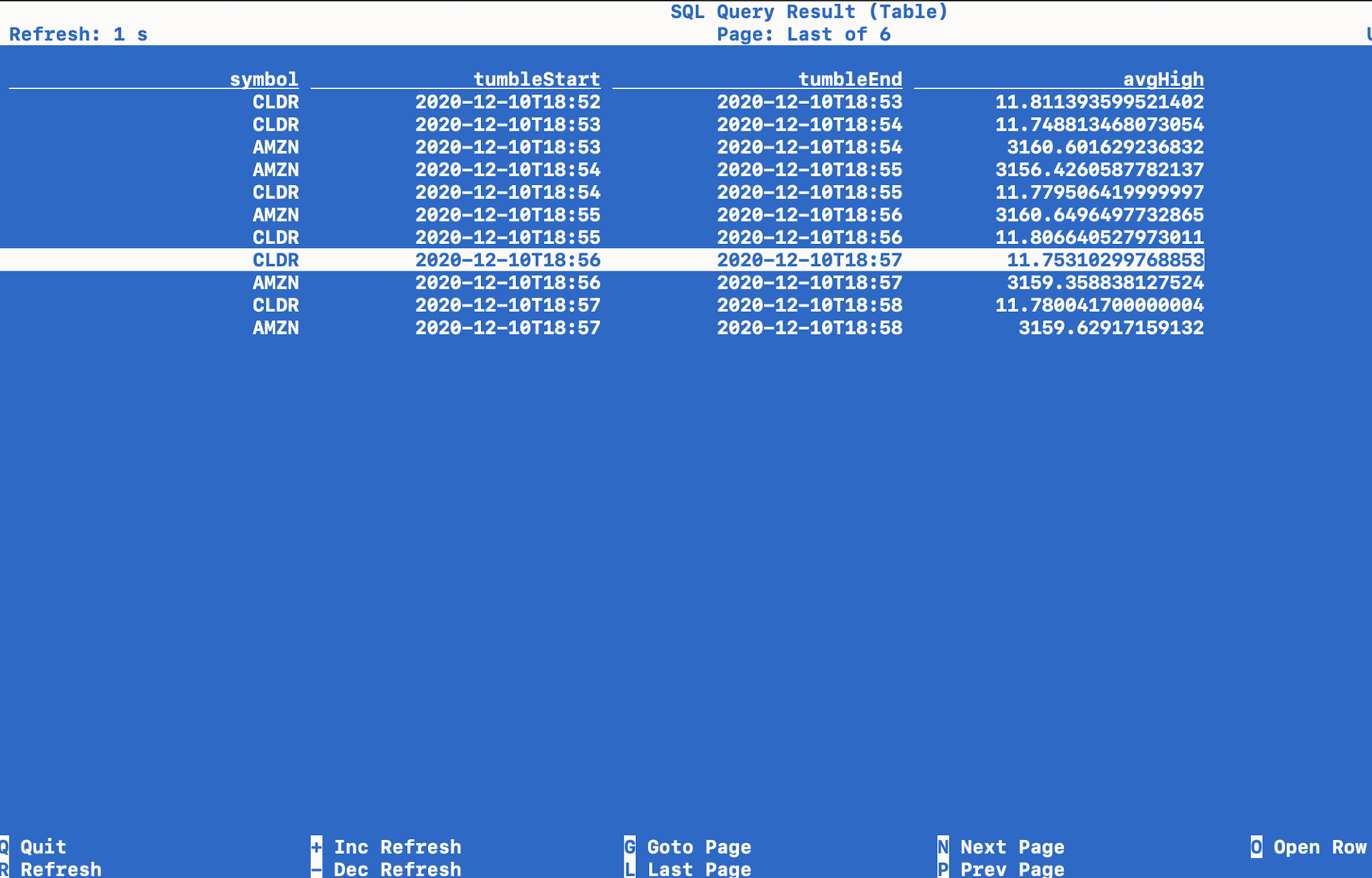
Tumbling Window
SELECT symbol,
TUMBLE_START (event_time, INTERVAL '1' MINUTE) as tumbleStart,
TUMBLE_END(event_time, INTERVAL '1' MINUTE) as tumbleEnd,
AVG(CAST(high as DOUBLE)) as avgHigh
FROM stockEvents
WHERE symbol is not null
GROUP BY TUMBLE(event_time, INTERVAL '1' MINUTE), symbol;
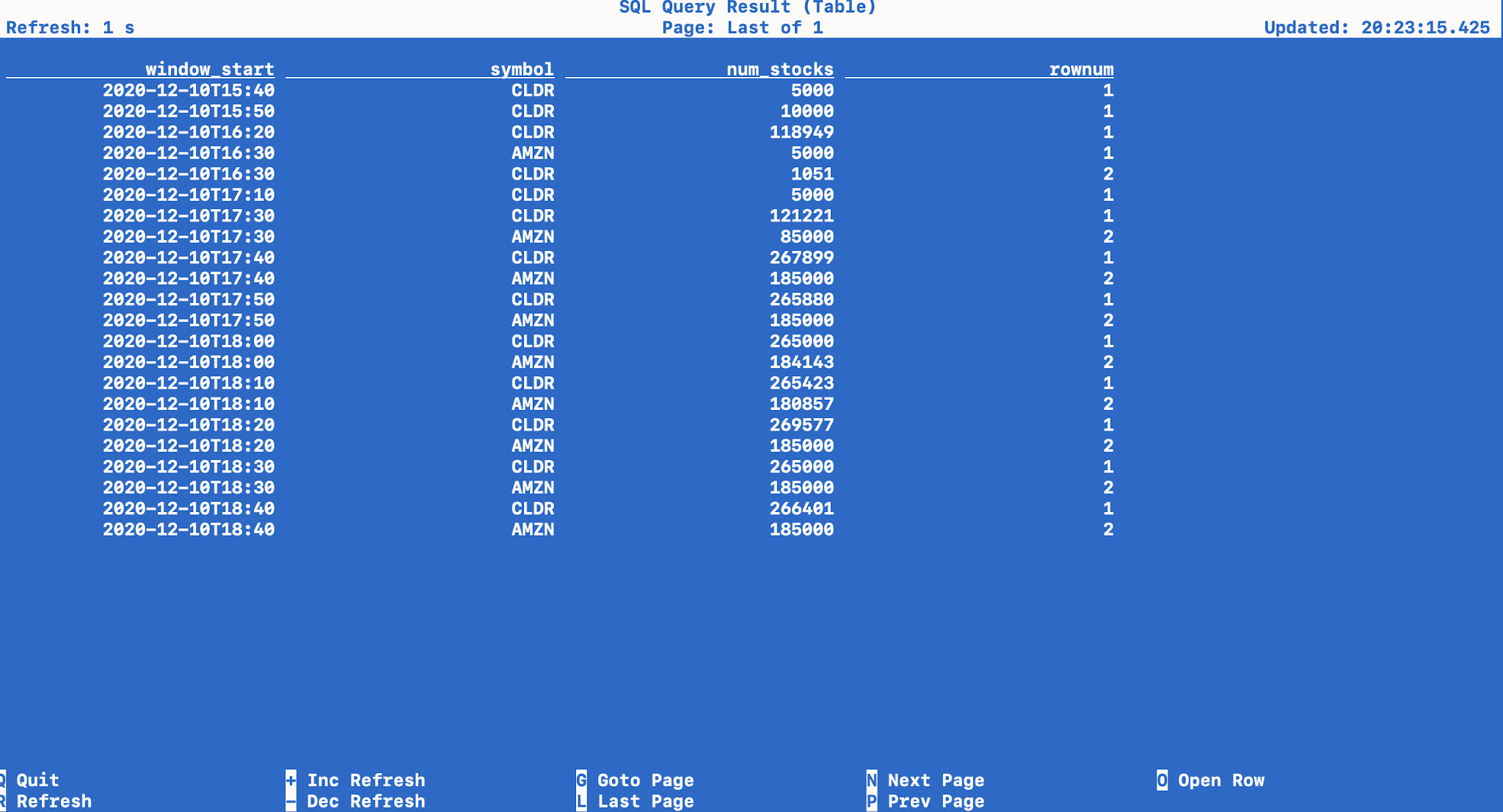
Top 3
SELECT *
FROM
( SELECT * , ROW_NUMBER() OVER
( PARTITION BY window_start ORDER BY num_stocks desc ) AS rownum
FROM (
SELECT TUMBLE_START(event_time, INTERVAL '10' MINUTE) AS window_start,
symbol,
COUNT(*) AS num_stocks
FROM stockEvents
GROUP BY symbol,
TUMBLE(event_time, INTERVAL '10' MINUTE) ) )
WHERE rownum <=3;
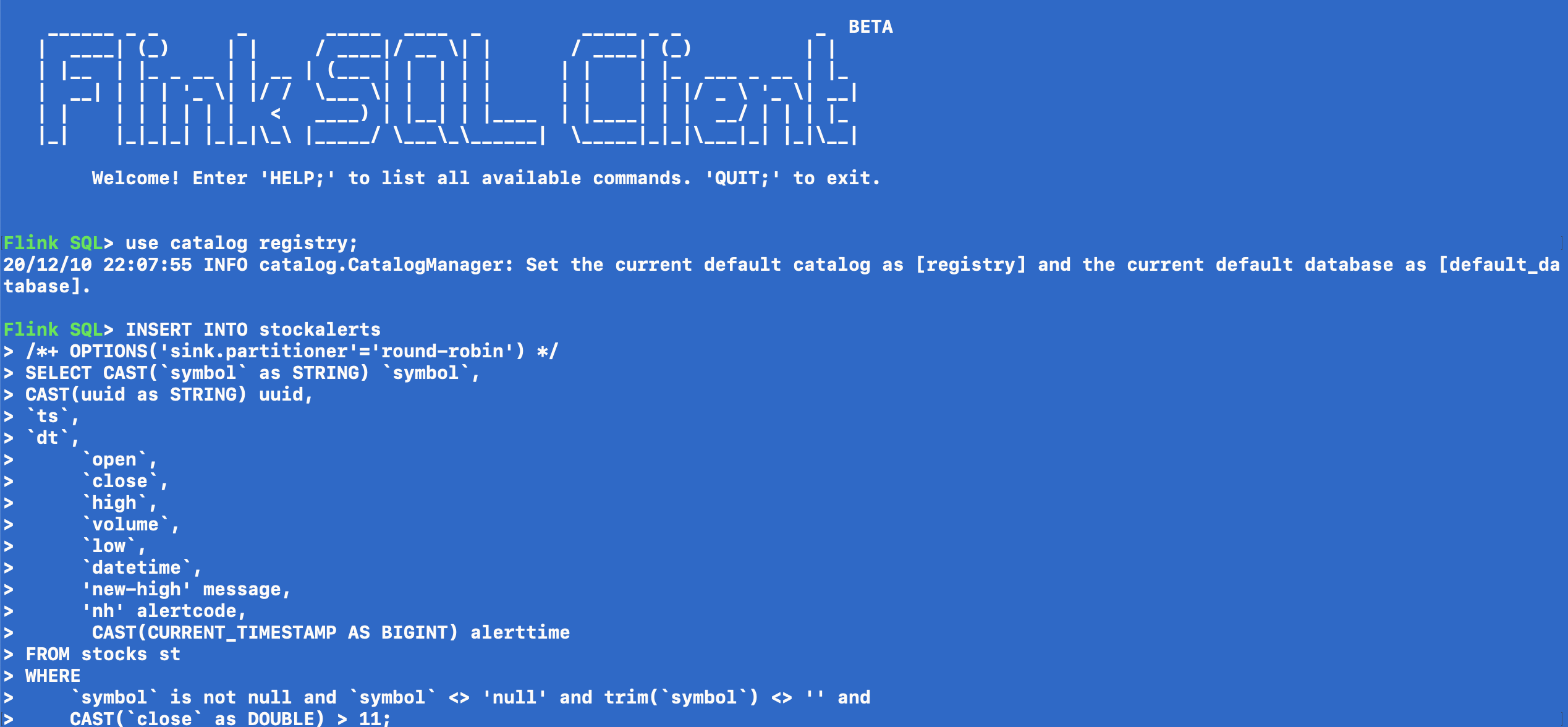
Stock Alerts
INSERT INTO stockalerts
/*+ OPTIONS('sink.partitioner'='round-robin') */
SELECT CAST(symbol as STRING) symbol,
CAST(uuid as STRING) uuid, ts, dt, open, close, high, volume, low,
datetime, 'new-high' message, 'nh' alertcode, CAST(CURRENT_TIMESTAMP AS BIGINT) alerttime FROM stocks st
WHERE symbol is not null
AND symbol <> 'null'
AND trim(symbol) <> ''
AND CAST(close as DOUBLE) > 11;
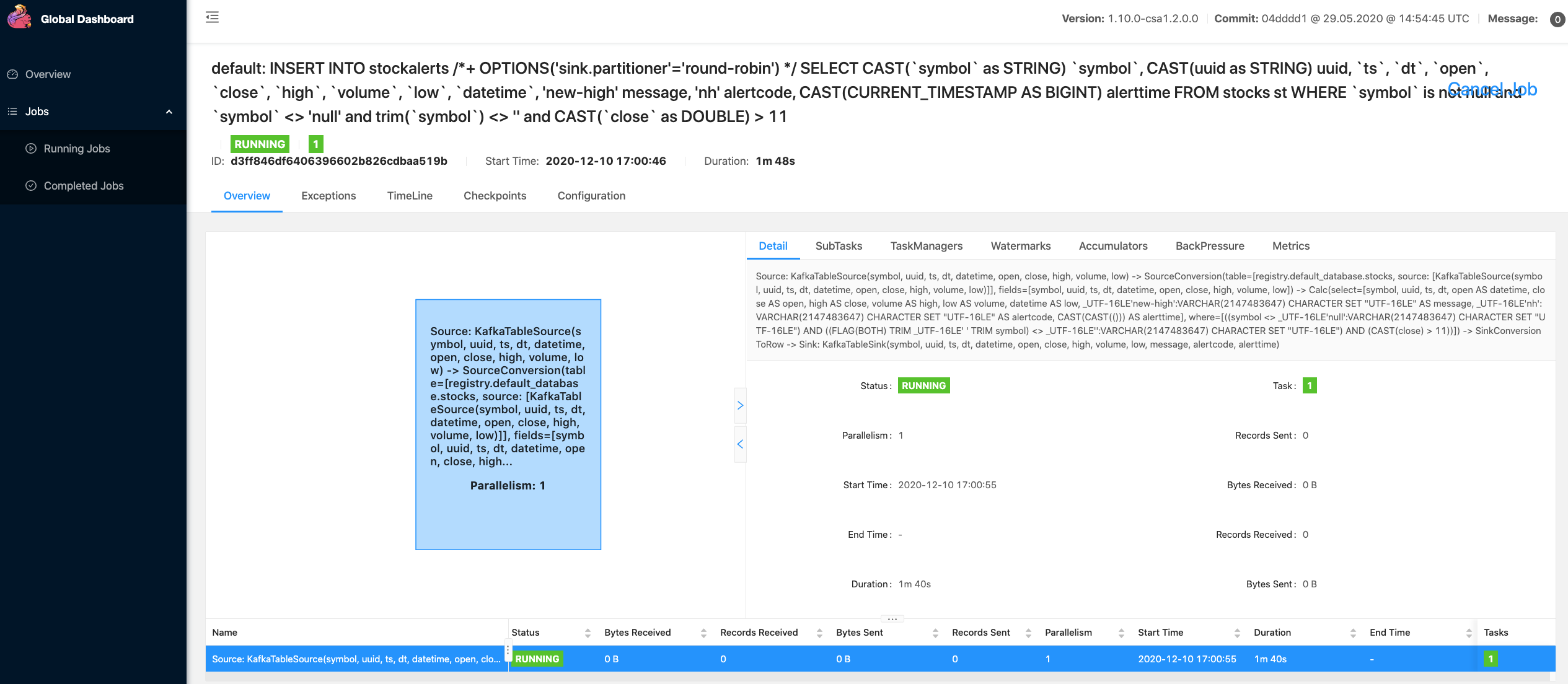
Monitoring Flink Jobs
Using the CSA Flink Global Dashboard, I can see all my Flink jobs runninging including SQL Client jobs, disconnected Flink SQL inserts and deployed Flink applications.
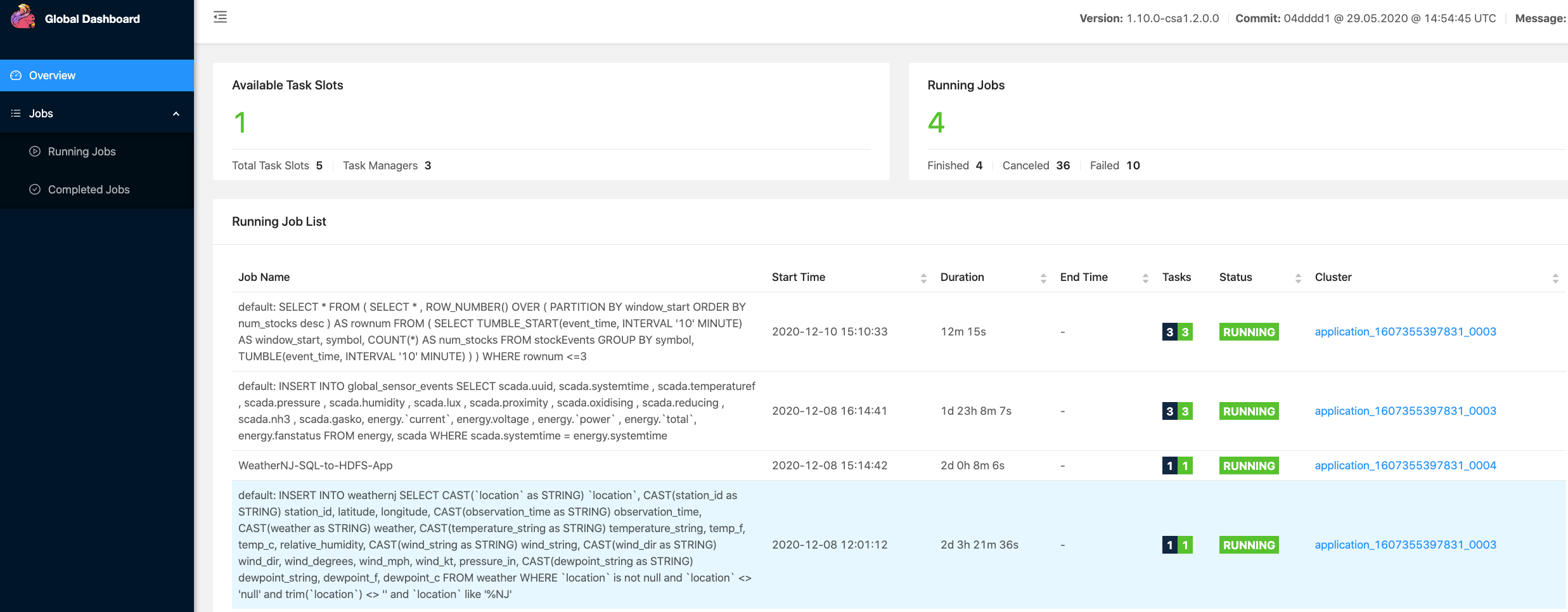
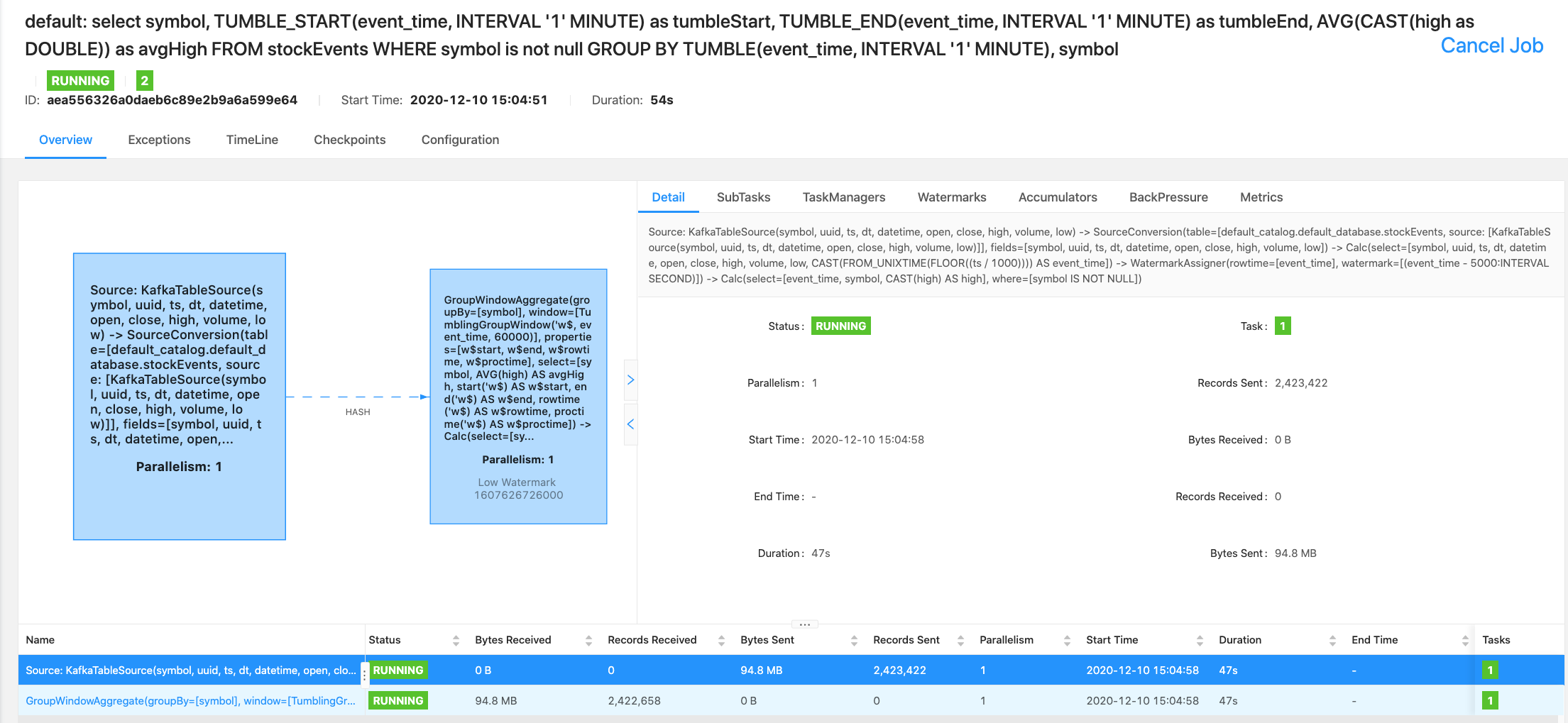

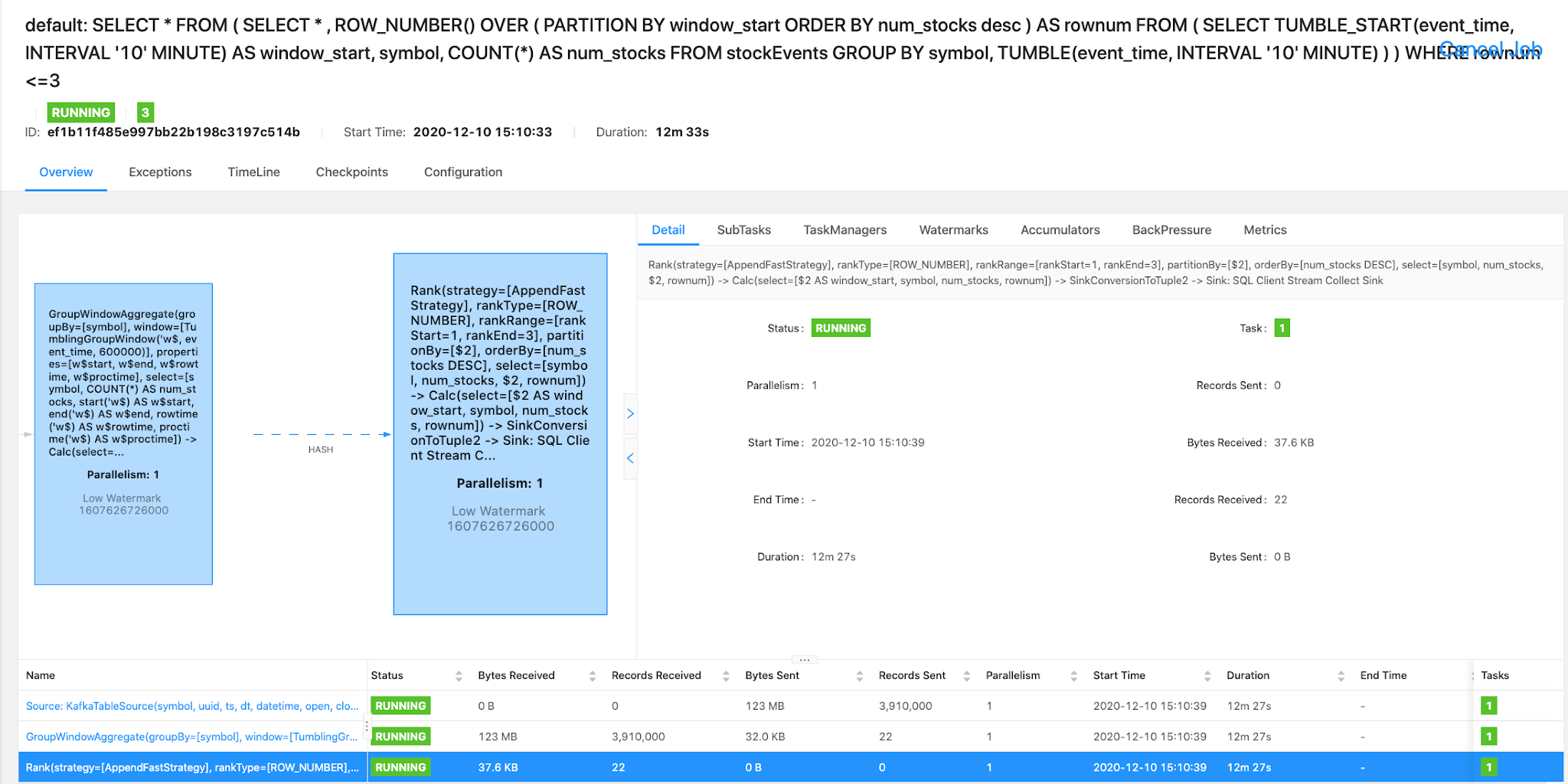


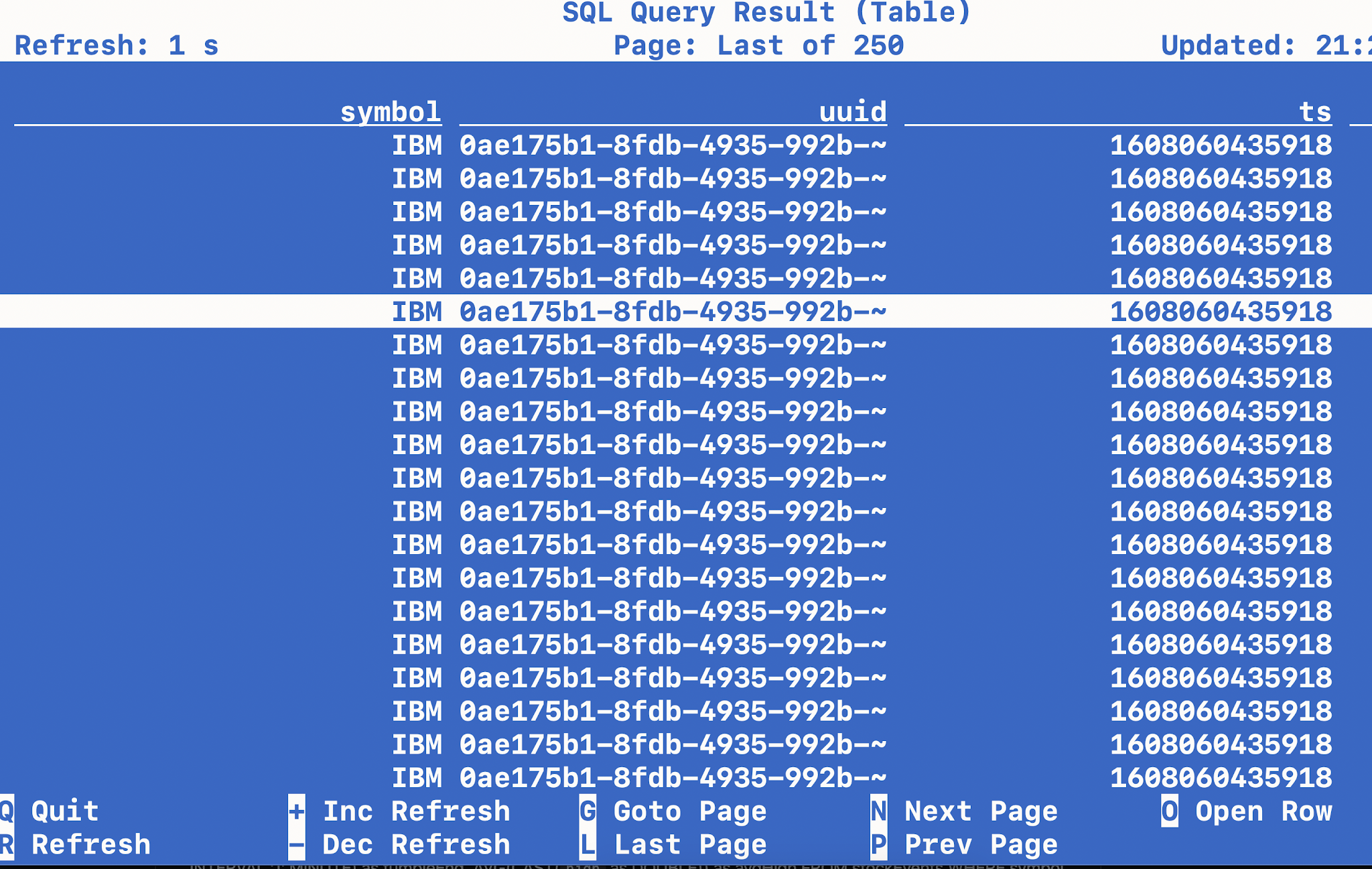
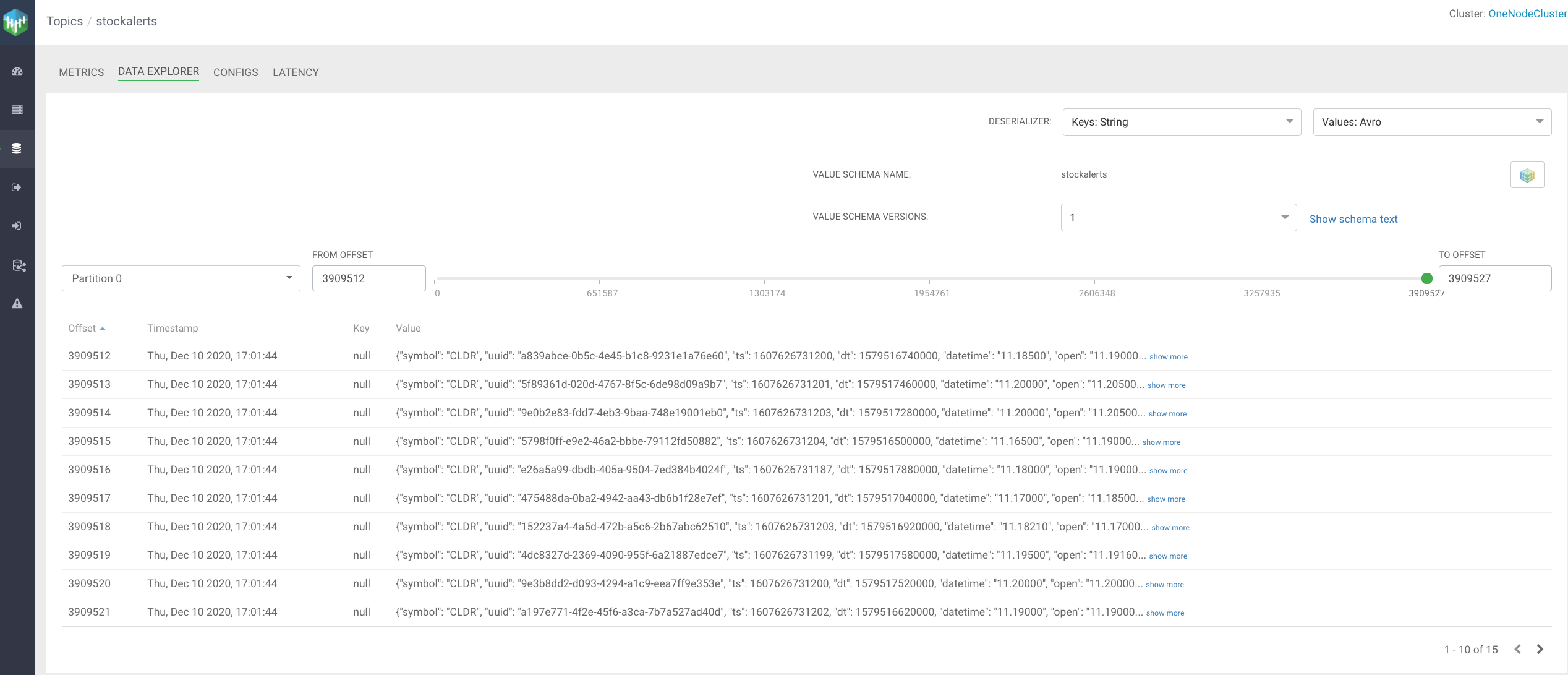
We can also see the data populated in the stockalerts topic. We can run a Flink SQL, Spark 3, NiFi or other applications against this data to handle alerts. That may be the next application, I may send those alerts to iphone messages, Slack messages, a database table and a websockets app.
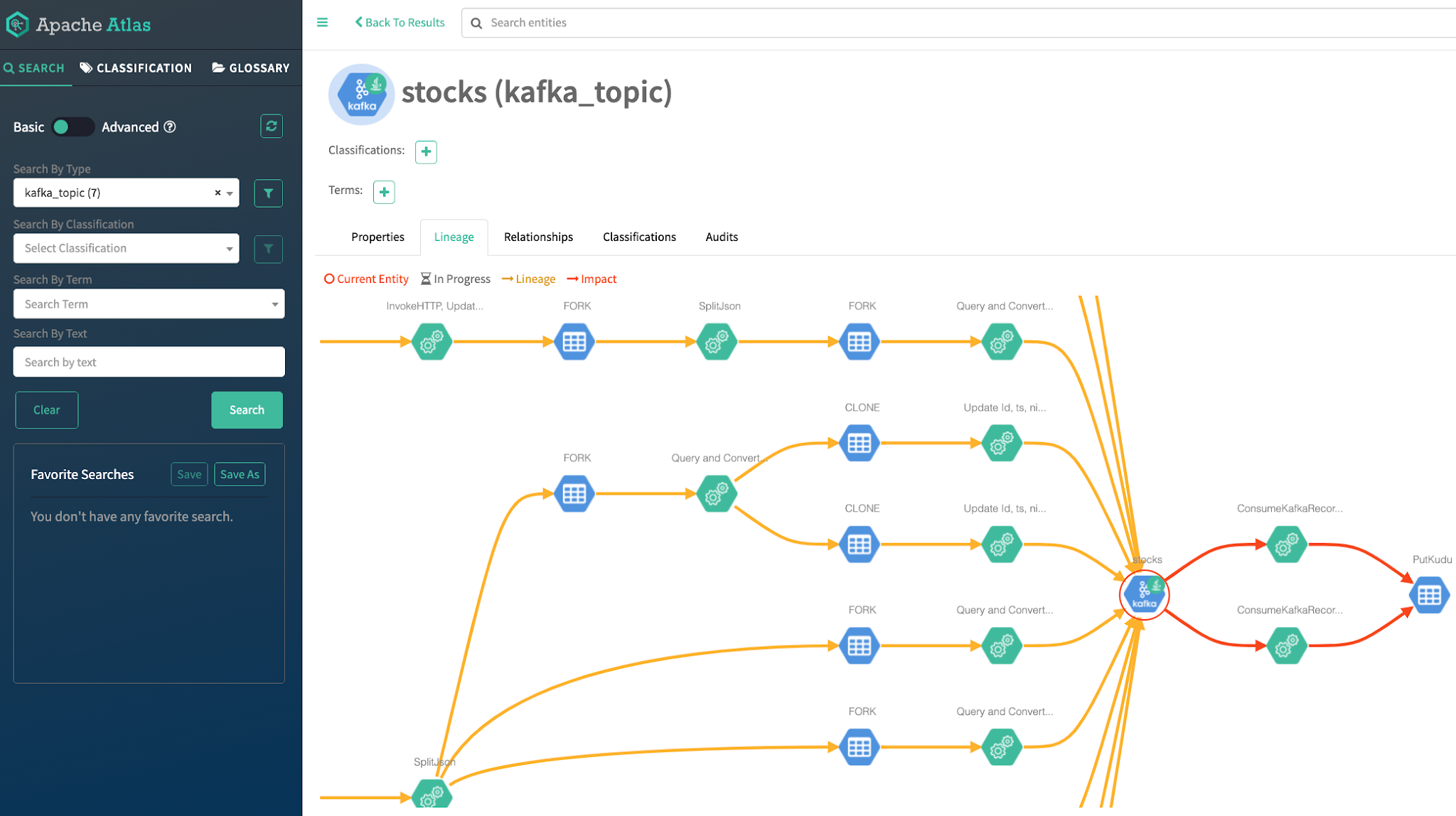
Data Lineage and Governance
We all know that NiFi has deep data lineage that can be pushed or pulled via REST, Reporting Tasks or CLI to use in audits, metrics and tracking. If I want to all the governance data for my entire streaming pipeline I will use Apache Atlas that is prewired as part of SDX in my Cloud Data Platform.
References
- https://github.com/cloudera/flink-tutorials/tree/master/flink-sql-tutorial
- https://github.com/tspannhw/FlinkSQLWithCatalogsDemo
- https://github.com/tspannhw/ClouderaFlinkSQLForPartners/blob/main/README.md
- https://github.com/tspannhw/ApacheConAtHome2020/tree/main/scripts
- https://github.com/tspannhw/SmartWeather
- https://ci.apache.org/projects/flink/flink-docs-stable/dev/table/sqlClient.html
- https://www.datainmotion.dev/2020/11/flank-smart-weather-applications-with.html
- https://www.datainmotion.dev/2020/11/flank-smart-weather-websocket.html


Top comments (0)