A Quick Summary of Microsoft's Common Objects in Context Image Database
It's been said that data scientists spend 60% of their time cleaning data, and 19% of their time building data sets, this leaves only 21% of a data scientist's time to allocate toward other tasks, such as:
- building models
- iteratively improving those models
- going to meetings that should have been emails
Many of the most exciting parts about machine learning (and Data Science in general) are stuck behind a lot of fairly boring and mundane tasks.

In 2015, a paper was released that describes "over 70,000 worker hours" spent building an enormous data set of labeled photographs. The goal of this data set was to provide training data for machine learning models to help with "scene understanding". At the time, there already existed multiple image data sets (which I'll summarize shortly), that focused on both high variety of objects, as well as many instances per object-type. One major downfall that Microsoft wanted to address, however, is that many of those objects and scenes were isolated in the image in such a way that they would almost never be seen in the context of a normal day. Here's an example from the paper.

The 4-cluster of images on the left are similar to what was the "industry standard" at the time for object detection, while the middle cluster shows iconic scenes: a yard, a living room, a street taken from SUN database: Large-scale scene recognition from abbey to zoo. The problem is that many of these images are too idealized, as if they were taken by a professional photographer for a catalog or a real estate listing. What the researchers from Microsoft were more interested in, though, is the non-iconic imagry displayed in the cluster toward the right side. For computer vision to be effective, we need training data that closely matches the types of tasks we want to predict on in the future. Since that data-set didn't exist, a few bright minds at Microsoft decided to build it.
Now that you know their motivations, I'll talk about their methods, but first, let's go into a bit more depth on the state of large computer vision datasets at the time this paper was released.
| Data Set Name & Link | # of Images | # of Labeled Categories | Year Released | Pros | Cons |
|---|---|---|---|---|---|
| ImageNet | 14,197,122 | 1000 | 2009 | Huge number of categories & images | Subjects are mostly isolated, out of normal context |
| Sun Database | 131,067 | 397 | 2010 | High 'image complexity' with multiple subjects per photo | Fewer overall instances for any one category |
| PASCAL VOC Dataset | 500,000 | 20 | 2012 | Fairly high instances per category | Low 'image complexity', and relatively few categories |
| MS COCO | 2,500,000 | 91 | 2015 | Good 'image complexity', high # of instances per category | The # of categories could be higher, but overall not a lot of downsides at the time it was released. |
Side note: Most of the images in this blog post are copied straight from the academic paper linked above. If you want to know the details of their methodology, I encourage to read the paper itself. It is well written and fairly short, only about 9 pages of text (including the appendix), and lots of insightful pictures and graphs. Here is their informationally dense comparison of the 4 large image datasets. My favorite graph here is the scatterplot in the lower left. Note the log scale on both X & Y axes.
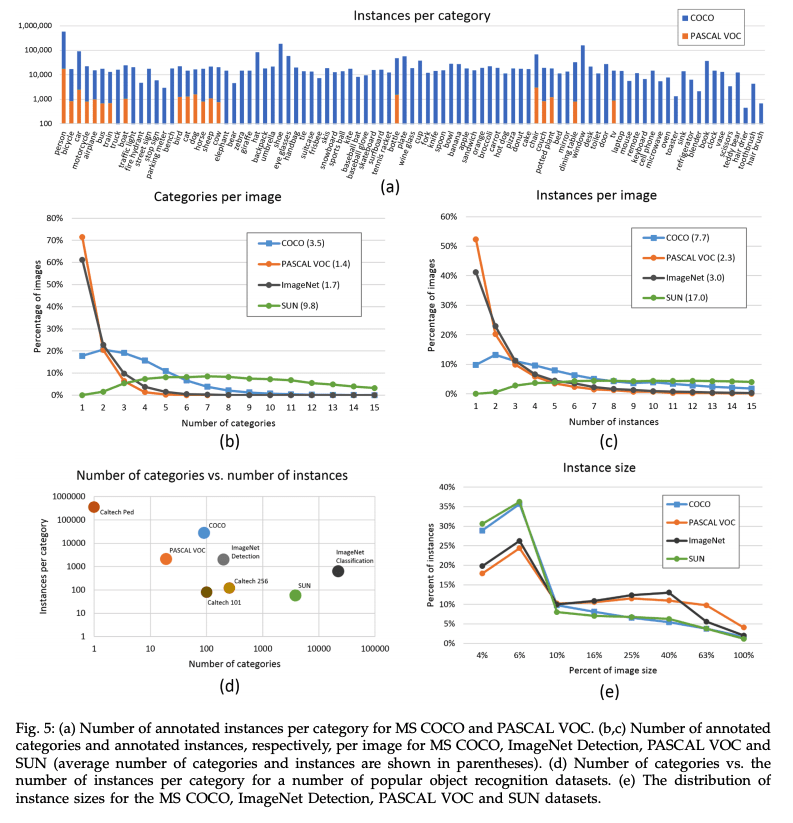
I hope you enjoyed nerding out over these graphs as much as I did. Now that we're all in a good head-space, let's dive into the immense planning and effort that went into creating MS COCO. For brevity, I will do this in an outline.
How It Was Done
1) Realize in what way the current data sets were lacking, and inspire someone to commit the resources to address those shortages
- Low image complexity
- Labels are bounding boxes only, not pixelated shading
2) Find pictures of multiple objects / scenes in an "everyday" context, instead of staged scenes
- Flickr contains photos uploaded by amateur photographers with searchable metadata and keywords
- Searches for multiple objects at the same time instead of just a single word / topic
- cat wine glass is better than just cat or wine glass
3) Annotate Images by hand: Amazon's Mechanical Turk (AMT) is a platform to crowdsource work, but care must be taken to maintain high standards
A) Label Categories -- Is there a ____________ anywhere in this picture?
- repeated 8 times per question with different AMT workers, to increase Recall. The chance that all 8 workers "get it wrong" is very low.
B) Instance Spotting -- There is already a ____________ in this picture, place a marker over every discrete instance of it that you see.
- also repeated 8 times per question with different AMT workers.
C) Instance Segmentation -- Shade the photo where each individual ____________ takes place (on average, any single photo has 7.7 instances that need to be shaded)
- Design an interface that will allow workers to shade the specific pixels where an object is in the image.
- Segmenting 2,500,000 object instances is an extremely time consuming task requiring over 22 worker hours per 1,000 segmentations. (around 80 sec per instance)
- For this reason, only a single worker will segment each instance, but high training and quality control is required.
Before we look at the outcomes, I want to remind you of Werlindo's Saturation Phenomenon:
1) Exhibit A is super novel and cool and ppl love it
2) Everyone copies the effect of Exhibit A to the point that it's overused and perceived as tacky
3) Someone who wasn't around / aware of Exhibit A sees it for the first time, and thinks "that looks tacky" not realizing they are looking at something kindof amazing that revolutionized an experience.
I first heard of this with regard to 'Bullet Time' from The Matrix

vs the 'low budget' version.

I bring this up, because even though we've seen a lot of cool image recognition and shading demos over the last few years, to the point of thinking they are normal, none of this would be possible without the rather boring task of building a massive, intricately labeled, natural scene image data set.
Thanks, Microsoft COCO.

I was going to add even more images to this blog showing the output of this project, but instead, you should probably just play around with the dataset yourself. There are even pre-trained models that work "out of the box" to leverage all of this hard work, with almost no added input from you.

Top comments (0)