Machine Learning is applied in a variety of fields all over the world. There is no exception in the healthcare industry. Machine Learning can help forecast the existence or absence of motor problems, heart ailments, and other diseases. Such information, if predicted in advance, can provide valuable insights to clinicians, allowing them to tailor their diagnosis and treatment to each individual patient.
As a result, preventing heart disease has become more important than ever. Good data-driven systems for predicting cardiac illnesses can help to improve the overall research and preventive process, allowing more individuals to live a healthy lifestyle. This is where Machine Learning enters the picture. Machine Learning aids in the prognosis of heart illnesses, and the results are precise.
The project included data processing and analysis of a heart disease patient dataset. Then, using various techniques, several models were trained, and predictions were made. KNN, Decision Tree, Random Forest, SVM, and Logistic Regression are just a few examples.
To forecast the presence of cardiac disease in a patient, I employed a range of Machine Learning methods built in Python. This is a classification problem with a range of input features as parameters and a binary target variable for predicting whether heart disease is present or not.
STEP 1- IMPORT LIBRARIES
There are many libraries available in python. I have included:
numpy: To work with arrays
pandas: To work with csv files and data frames
matplotlib: To create charts using pyplot.
train_test_split: To split the dataset into training and testing data
STEP 2- IMPORT DATASET
Since I am using dataset which is already present on Kaggle. So, I have downloaded it Link. There are many datasets available online you can use that also. Next, I have use read_csv () to read dataset and save it to some variable (I have used “set” variable)
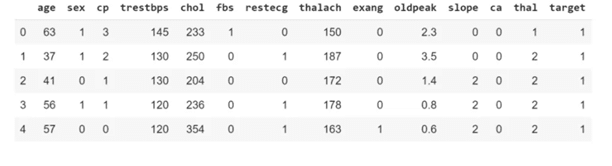
Before any analysis its good to take all information of what your whole dataset consists off to have an optimal model. So, I have used the info () method.
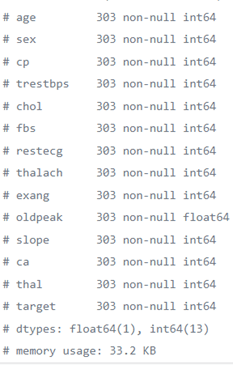
As you can see from the output above, there are a total of 13 features and 1 target variable, as well as no missing values, so there are no null values to worry about... LUCKY!!
STEP 3- UNDERSTANDING THE DATA
Correlational Matrix
Its very important to understand your data. So, to begin with, let’s start by looking at the feature correlation matrix and attempting to analyze it. rcParams is used to set the figure size .The correlation matrix was then visualized using pyplot. I've added names to the correlation matrix using xticks and yticks. .colorbar() displays the matrix's colorbar.
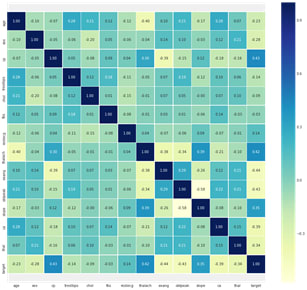
By looking that this it's clear that no single feature has a particularly strong relationship with our desired value. In addition, some traits have a negative association with the goal value, while others have a positive correlation.
Histogram
The nicest aspect about this type of plot is that it only requires one command to generate the plots and it returns a wealth of information. Simply type variable.hist() into your command.
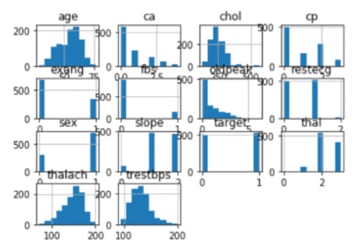
Graphical Representation of relation between Attributes:
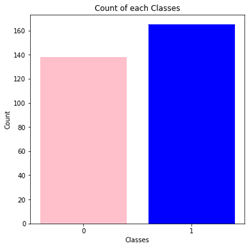
We observed that there are 207 men and 96 women data provided in the dataset.
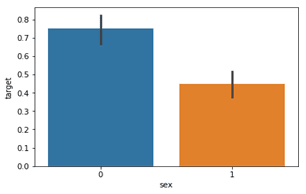
We notice that females are more likely to have heart problems than males.
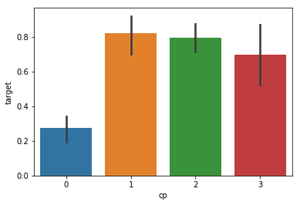
We notice ,that chest pain of '0', i.e. the ones with typical angina are much less likely to have heart problems.
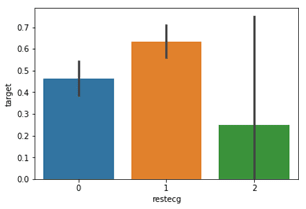
We realize that people with restecg '1' and '0' are much more likely to have a heart disease than with restecg '2'.
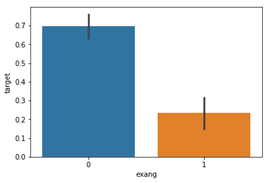
People with exang=1 i.e. Exercise induced angina are much less likely to have heart problems.
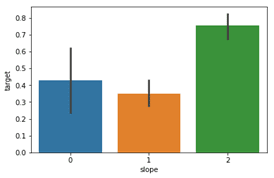
We observe that Slope '2' causes heart pain much more than Slope '0' and '1'.
STEP 4-USE MACHINE LEARNING ALGORITHMS
In this project, I picked four algorithms and experimented with their various settings before comparing the results. I divided the dataset into two parts: training data and testing data.
1.Logistic Regression
Logistic regression is a statistical analysis approach for predicting a data value based on previous data set measurements. In the field of machine learning, logistic regression has become an important technique. The method enables a machine learning application to classify incoming data using an algorithm based on historical data.
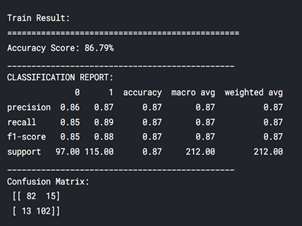


As you can see, my training accuracy is 86.79% and testing accuracy 86.81%
2.K-nearest neighbors
This classifier searches for the classes of a data point's K closest neighbors and assigns a class to that data point based on the majority class. The number of neighbors, on the other hand, can be modified. I varied the number of neighbors from one to twenty and calculated the test score in each case.
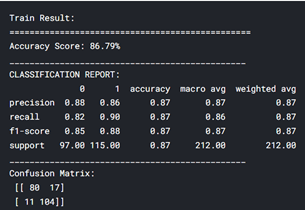
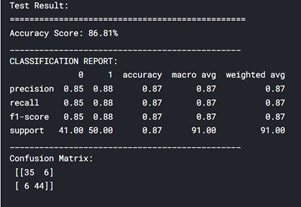
As you can see, my training accuracy is 86.79% and testing accuracy is 86.81% same as of logistic regression.
3.Support Vector machine
By altering the distance between the data points and the hyperplane, this classifier seeks to construct a hyperplane that can divide the classes as much as feasible. The hyperplane is determined depending on several kernels.
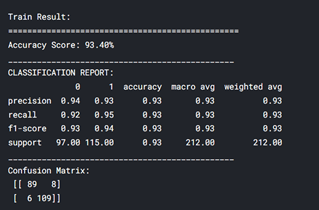
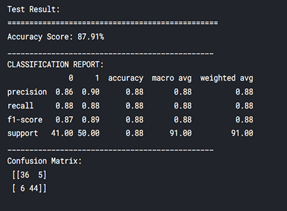
As you can see my training accuracy is 93.40% and testing accuracy is 87.91%
STEP 5-CONCLUSION
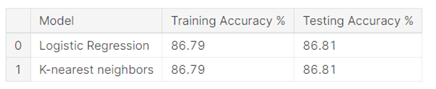
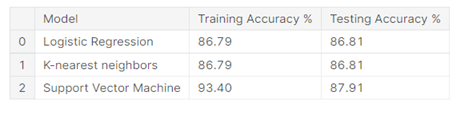
The project involved analysis of the heart disease patient dataset with proper data processing. Then, 3 models were trained and tested with maximum scores as follows:
Form the comparison study; it is observed that the Support Vector Machine model turned out to be best classifier for heart disease prediction.
Thank you for reading!! Feel free to share your thoughts and ideas.😄✨

HACK THIS FALL 2.0
Hi FOLKS!!!✨🎊
I'm ecstatic to share the news that I've been accepted as a "Hackathon Evangelist" for Hack This Fall 2.0!✨🎉
I'm so pumped to make a difference and contribute meaningfully to the hacker community with my amazing ML hacks!!! If you also want to make #InnovateForGood then do register now for Hack This Fall 2.0 today itself.🎇
Do register at: Link
Use this special code “HTFHE066” to earn amazing and super exclusive goodies just for you.🤩🤩🤩





Top comments (1)
HACK THIS FALL🤩🤩
Do register at: hackthisfall.tech/
Use this special code “HTFHE066” to earn amazing and super exclusive goodies just for you on the above link.🤩🤩🤩