

"Every day, three times per second, we produce the equivalent of the amount of data that the Library of Congress has in its entire print collection, right? But most of it is like cat videos on YouTube or 13-year-olds exchanging text messages about the next Twilight movie."
– Nate Silver, founder and editor in chief of FiveThirtyEight.
So, what do we understand by this? Data, in contemporary times, is produced on a huge scale. The only thing limiting its growth is the storage of it. The sources of data have evolved, the ways have evolved, thanks to IoT and other technologies. This data is beautiful, we can do all kinds of operations on it and fetch insights from it. But the fundamental question is – Is all of this data useful? Do I need to process all of this data? Can I process all of this data? And most importantly, how do I process all of this data?
Let’s understand this with an example – Email Classification.
We receive a lot of emails regularly, all of these with varying importance. The least important ones are spam emails, in fact, they are unwanted and undesirable. A lot of efforts are made to prevent them from landing in our inbox. Let’s pick up one example from our inbox and contemplate on it for a moment. Each email, apart from the sender and recipient address, contains the subject – which is considered an important factor in deciding if you will open the mail or not – and the body, along with the attached documents. Look at the body of this mail, look at each of these words carefully! What is it that makes us decide if it is spam mail or not? Some special words in the spam mail create a sense of urgency and a few of these in a particular sequence make us decide that it is spam mail. So, let’s break down the body into a list (vector) of words and then understand the pattern in it and the usage of “the special words” in this email.
To achieve this goal, you construct a mathematical representation of each email as a bag-of-words vector. This is a binary vector, where each position corresponds to a specific word from an alphabet. For this email, each entry in the bag-of-words vector is the number of times a corresponding word appears in an email (0 if it does not appear at all). Assume you have constructed a bag-of-words from each email, and as a result, you have a sample of bag-of-words vectors
Hang on for a while and think again. Are all of the words in the email important for the identification of these special words? And what else is needed here?
However, not all words (dimensions) of your list (vectors) are informative for the spam/not spam classification. For instance, words “lottery”, “credit”, “pay” would be better variables/features for spam classification than “dog”, “cat”, “tree”. If each column were to be a word from this vector, sure, we have reduced a lot of dimensions from this data, but we apply more specialized techniques, which we shall be covering in the subsequent sections, for the dimensionality reduction.
We’ve spoken a lot about dimensionality reduction BUT what is “Dimensionality Reduction”?
Dimensionality reduction is simply, the process of reducing the dimension of your feature set. Your feature set could be a dataset with a hundred columns (i.e., features) or it could be an array of points that make up a large sphere in the three-dimensional space. Dimensionality reduction is bringing the number of columns down to say, twenty or converting the sphere to a circle in the two-dimensional space.
What problems do they pose? – The Curse of Dimensionality
Data, that is in higher dimensions generally pose a lot of problems than the data in the lower dimensions, this is what is called the curse of dimensionality. Think of image recognition problem of high-resolution images 1280 × 720 = 921,600 pixels i.e. 921600 dimensions. That is huge! Now you see why the “CURSE”?
As the number of features increases, the number of samples also increases proportionally. The more features we have, the greater number of samples we will need to have all combinations of feature values well represented in our sample.
As the number of features increases, the model becomes more complex. The more the number of features, the more the chances of overfitting. A machine learning model that is trained on a large number of features, gets increasingly dependent on the data it was trained on and in turn overfitted, resulting in poor performance on real data, beating the purpose.
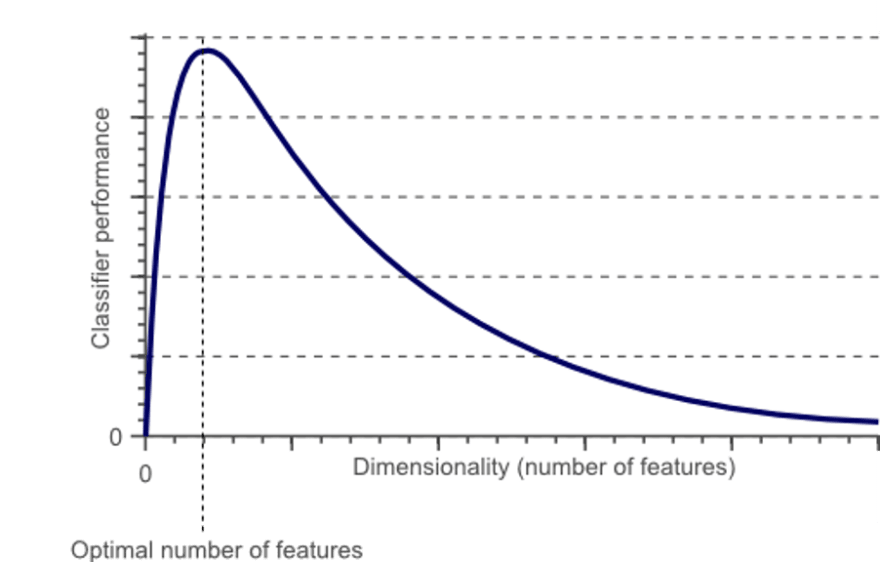
Avoiding overfitting is a major motivation for performing dimensionality reduction. The fewer features our training data has, the lesser assumptions our model makes, and the simpler it will be. But that is not all and dimensionality reduction has a lot more advantages to offer, like
- Fewer misleading data means model accuracy improves.
- Fewer dimensions mean less computing. Less data means that algorithms train faster.
- Fewer data means less storage space required.
- Fewer dimensions allow usage of algorithms unfit for a large number of dimensions
- Removes redundant features and noise.
Methods: Feature Selection and Feature Engineering
Dimensionality reduction could be done by both feature selection methods as well as feature engineering methods.
Feature selection is the process of identifying and selecting relevant features for your sample. Feature engineering is manually generating new features from existing features, by applying some transformation or performing some operation on them.
Feature selection can be done either manually or programmatically. For example, consider you are trying to build a model which predicts people’s weights and you have collected a large corpus of data that describes each person quite thoroughly. If you had a column that described the color of each person’s clothing, would that be much help in predicting their weight? I think we can safely agree it won’t be. This is something we can drop without further ado. What about a column that described their heights? That’s a definite yes. We can make these simple manual feature selections and reduce the dimensionality when the relevance or irrelevance of certain features are obvious or common knowledge. And when it’s not glaringly obvious, there are a lot of tools we could employ to aid our feature selection.
I hope this was helpful and was able to put things down in a simple way. Please feel free to reach to me on Twitter @AashishLChaubey in case you need more clarity or have any suggestions.

Top comments (0)