
PostgreSQL is a widely used relational database management system. It is highly regarded for its scalability and robustness. If you're looking to harness the power of PostgreSQL and improve query processing, you should know more about query processing internals.
This guide is divided into three parts, there are some other parts not covered here it would be better to read it from the book and understand it well with the provided examples.
Part 1 provides an overview of query processing in PostgreSQL.
Part 2 delves into the process of obtaining an optimal plan for a single-table query, explaining the steps involved in cost estimation, plan tree creation, and execution.
Part 3 explores the process of obtaining an optimal plan for a multiple-table query, detailing the three join methods: nested loop, merge, and hash join, as well as the creation of the plan tree.
You will gain a deep understanding of PostgreSQL's subsystems:
Parser
Analyzer/Analyser
Rewriter
Planner
Executor
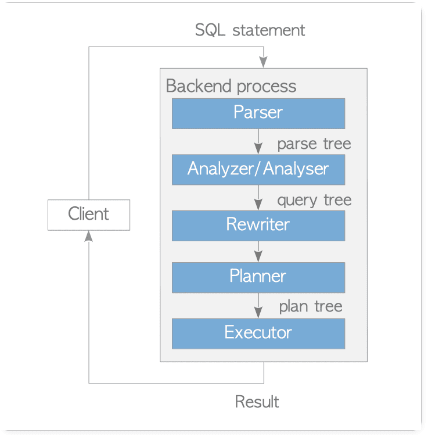
You will learn how each subsystem works together to handle queries, with detailed explanations of the Planner and Executor functions.
Cost estimation is a critical aspect of query optimization, and Part 2 provides an in-depth exploration of this topic. You will learn about the three kinds of costs used in PostgreSQL: start-up, run, and total, and how these costs are estimated for different operations. The cost of sorting is also explained in detail, including the quicksort algorithm and temporary file creation.
Join Methods
PostgreSQL supports three join operations: nested loop join, merge join and hash join. The nested loop join and the merge join in PostgreSQL have several variations.
Note that the three join methods supported by PostgreSQL can perform all join operations, not only INNER JOIN, but also LEFT/RIGHT OUTER JOIN, FULL OUTER JOIN and so on; however, for simplification, we focus on the NATURAL INNER JOIN in this chapter.
Nested Loop Join
The nested loop join method is the simplest join method. In this method, PostgreSQL scans the outer table row by row and for each row, scans the inner table to find matching rows. The nested loop join is suitable when one or both tables are small, and the join condition is selective.
Merge Join
The merge join method is more efficient than the nested loop join method for larger tables. In this method, PostgreSQL first sorts the two tables to be joined by the join key(s). Then, it merges the sorted tables to find matching rows. The merge join is suitable when both tables are sorted by the join key(s), and the join condition is selective.
Hash Join
The hash join method is the most efficient join method for large tables. In this method, PostgreSQL builds a hash table for the inner table using the join key(s). Then, it scans the outer table and probes the hash table to find matching rows. The hash join is suitable when both tables are large, and the join condition is not selective.
Conclusion
In conclusion, PostgreSQL's query processing is a complex process that involves several subsystems, including the parser, analyzer, rewriter, planner, and executor. The planner is the most complicated subsystem and is responsible for generating the optimal plan tree for a given query.
The cost-based optimization approach used by PostgreSQL is based on estimating the cost of each possible query plan and choosing the plan with the lowest estimated cost. PostgreSQL supports both single-table and multiple-table queries and uses different join methods depending on the size of the tables and the selectivity of the join condition.
By understanding the query processing internals of PostgreSQL, developers can write more efficient queries and optimize the performance of their PostgreSQL-based applications.

Top comments (0)