
A really cool feature that saw the light today in Storage.Net is what I call (at least for now) Transform Sinks. The ideas of those is to transparently transform binary data when it's uploaded to a remote storage to another form, and un-transform it when downloading it again. The applications of this is endless - gzipping, encrypting, sanitizing, protecting data and so on.
I was especially interested in gzipping and encrypting, as this was required in one of my projects, therefore they were added first. I'll keep adding more in future, but they are easily extensible, so anyone is welcome to do it anyway.
Issues
There are serious issues in general with transform sinks and streaming (all the data in Storage.Net is streamed by default, so it can handle unlimited amounts). First, most cloud storage providers require knowing length of the data before it is uploaded to the storage. And that's OK in most situations, however when the data is transformed behind your back with a transform sink, it will (most probably) change the length.
For instance, gzip compression most definitely decreases amount of data (unless the file is too small, then it's other way around), encryption, depending on implementation, also changes data size slightly. Base64 encoding increases data by 30% in size, and so on.
One of the way to overcome this is simply using MemoryStream - copy incoming data, transform it, hold in the memory stream, so you know the end game characteristics, and then upload it. And that's fine for smaller files, but when they are large, or larger than the amount of RAM available on the current node, this is simply not possible.
The other issue with memory streams is that allocating large (even >8k is large) memory buffers really slows down the application and creates an immense pressure on GC.
Solution
Storage.Net actually does use in-memory transforms in this release, however it's performed in a very efficient way by using Microsoft.IO.RecyclableMemoryStream package that performs memory pooling and reclaiming for you so that you don't need to worry about software slowdows. You can read more about this technique here.
This also means that today a transform sink can upload a stream only as large as the amount of RAM available on your machine. I am, however, thinking of ways to go further than that, and there are some beta implementations available that might see the light soon.
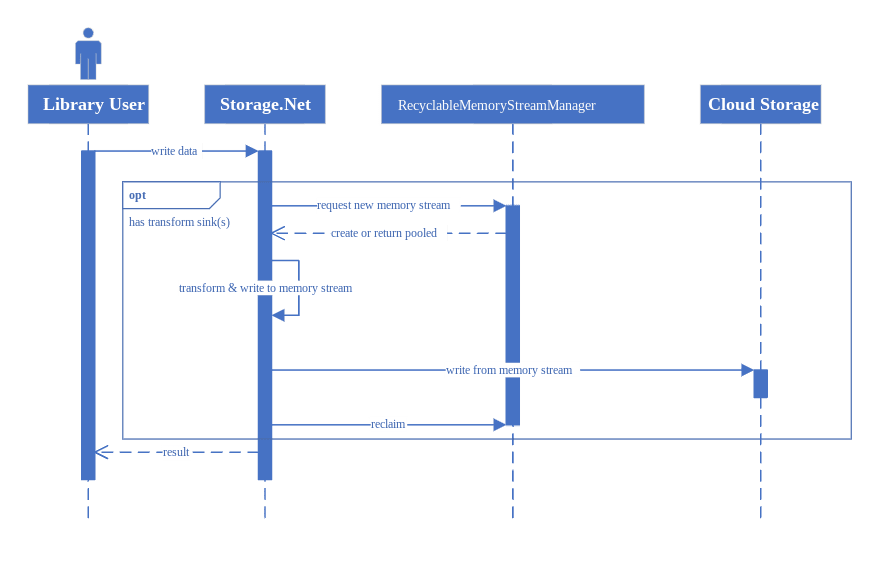
One of the ideas is to provide an ability to specify a path to a temporary disk buffer which can hold the intermediary results of these transforms, but that's for the future.
Anyway, try this out, implementing data transforms on your own is very hard, and even harder to implement an abstraction for cloud storage providers.
This article was originally published on isoline blog.

Top comments (0)