Most of the tabular databases like Oracle, MySQL, Postgre, etc., give us some tools like joins to get data from multiple tables or the ability to make operations with the data retrieved creating simple or complex SQL statements. On my normal day in the product component that I work, I make complex SQL statements using PL/SQL to build operations to achieve an expected result. Recently, the company began migrating the component to a document-based database and we chose MongoDB. With this election, one of the most popular questions that I asked was: How can I make operations when retrieving data from the database as I did with the tabular databases?
After reading a lot and taking some Mongo University Courses I realized something about the MongoDB framework. This is a piece of the MongoDB universe that provides a lot of components and functionalities to make anything that we want with the data. In this paper, I will talk about how this framework works and I will introduce you to some of these functionalities that MongoDB gives us.
How does it work?
Recently a coworker and I were developing an app to track our finances from the emails sent by the banks; each email contains information about a transaction like payments, withdrawals, transfers, etc.
This information is stored in the mongo database and contains some information like the account, amount, location, and other properties of the transaction. The idea was to accept or reject a transaction and get some statistics of the accepted ones like percentage of the transaction by category, percentage of the transaction by card type (credit or debit card), or expenses vs incomes.
To get some of those statistics, we needed to make some groups and manipulate some data. I was lost at the beginning since I only knew the common things about Mongo like the CRUD operations and the projections, but after some research and courses are taken, the Aggregation Framework became the hero of the day. Let me show you some of the tools that we can use with this framework.

Image retrieved from https://www.codeproject.com/KB/database/1149682/image001.png
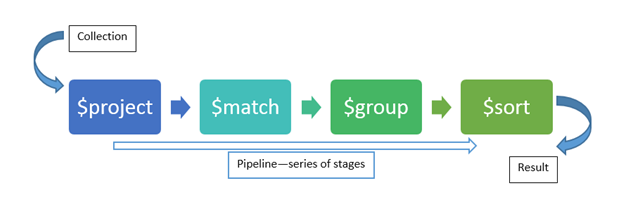
The Aggregation Framework provides multiple functionalities like $project, $match, $lookup, $sort, $limit, etc.; Tools that we will call for now stages of our pipeline.
The pipeline has a simple definition, which is a collection of stages that the database will execute to transform our data.
A stage is a functionality that we use to manipulate our data and get the expected result.
Here is something important to remember: the database will execute the stages in the same order that we write them and some stages have restrictions to get a position in the pipeline since we need to use a stage first and then use another one.
We can use this framework like so:
db.collection.aggregate([stage1, stage2, stage3 ])
We are telling the MongoDB database “Hey, with the data of this collection make the next transformation in this order and give me the result”.
So, let’s make some comparisons with a tabular database:
Imagine that we have a site to track the expenses of a user, and in the database schema, we separate the payment information from the user data in the data model, like this:

User-Payments diagram
Now imagine you need to get the payments for a user.
With a Tabular database like Oracle you will need to make an SQL statement like this one:
In the Oracle database, we will need to use the join functionality to get the data from the payments table using the relationship of the user identification.
But with MongoDB we need to use the aggregation framework and write a pipeline like this:
In this pipeline we are using two stages:
$match: This stage allows us to make some validations on the data and returns the information that matches them; like the where statement in a tabular database, or a find operation in our MongoDB database.
$lookup: This stage allows us to look at data from different collections using a field of the present documents as the relationship identifier, returning to us an array of the documents that match the local and foreign Fields criteria.
What happens if the database returns too many users and I want to put a limit?
This is simple to do. Let’s do the comparison from a tabular database with the MongoDB database:
Tabular Database (Oracle):
MongoDB pipeline:
In this pipeline, we introduce the $limit stage. This stage does the same as the limit of a tabular database, retrieving the first 5 documents (in MongoDB case) or rows (in a tabular database case).
But, what happens if I want to retrieve some data of the payments like the value and the location?
Let’s make the comparison again.
In the tabular database (Oracle):
In this case for the tabular database is simple, I just select the value and location column on the payments table.
In the MongoDB database:
In this pipeline, we use the $project stage, this stage permits us to manipulate the data retrieved like show/hide some specific fields, or make operations using other stages, like the $map stage used to retrieve only the value and location of the payments.
The $project stage is important because we can set binary values to show or hide a field. By default only the _id and the fields that are entries of the JSON arg are returned; If we need to delete the _id we need to indicate it this way:
{
_id: 0,
name: 1,
payments:{
$map: {
input: "$payments",
as: "payment",
in: {
value: '$$payment.value',
location: '$$payment.location'
}
}
}
}
Returning the following:

Project output without the _id field
In contrast, if we do not specify it:

Project output returning the _id field
Conclusions
The MongoDB aggregation framework gives use powerful functionalities like:
- Manipulation of our data with simple stages.
- Multiple powerful stages to do with our data most of the things that we need in a project. Read more about the stages.
- It is supported by all of the drivers provided by the MongoDB team.
- It allows us to deal with the data like we do with tabular databases in a simple and readable way.
Recommendations
If this framework got your attention, I would like to recommend you take the MongoDB M121 course and read the aggregation framework documentation. Don’t forget to follow the Condor Labs Engineering Medium page to get in touch with the latest papers.

{kind=link}
Top comments (0)