1. Setting Up the Front-End for Large File Upload
1.1 Choosing the Right Approach for Large Files
When dealing with large file uploads, especially files that may exceed tens or hundreds of megabytes, the first challenge is how to split the file and send it in chunks. This prevents timeout errors and improves upload reliability. The JavaScript FileReader API and FormData are essential for managing this on the front end.
Here's an example of a simple front-end implementation using vanilla JavaScript:
<input type="file" id="fileInput" />
<button onclick="uploadFile()">Upload</button>
<script>
async function uploadFile() {
const file = document.getElementById('fileInput').files[0];
const CHUNK_SIZE = 5 * 1024 * 1024; // 5MB chunks
let start = 0;
let end = CHUNK_SIZE;
while (start < file.size) {
const chunk = file.slice(start, end);
const formData = new FormData();
formData.append('fileChunk', chunk);
formData.append('fileName', file.name);
await fetch('YOUR_LAMBDA_URL', {
method: 'POST',
body: formData,
});
start = end;
end = start + CHUNK_SIZE;
}
alert('File uploaded successfully!');
}
</script>
1.2 Why Chunking Matters
Chunking allows the file to be uploaded in smaller, manageable parts, ensuring the Lambda function doesn't hit size limits or time out during a single request. This is especially useful for larger files where sending the entire file at once would be inefficient.
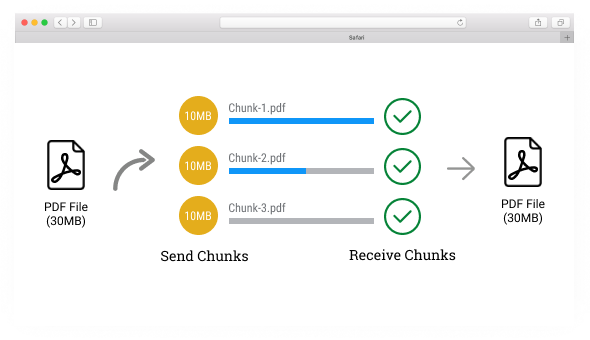
1.3 Back-End: Lambda Function to Handle File Chunks
Lambda functions in AWS are stateless and resource-constrained, meaning they cannot handle large files directly. The solution here is to allow the Lambda function to receive each chunk of the file, temporarily process it, and then pass it along to Amazon S3 in a multipart upload.
Here's a basic structure for your Lambda function written in Java 17:
import com.amazonaws.services.lambda.runtime.Context;
import com.amazonaws.services.lambda.runtime.RequestHandler;
import software.amazon.awssdk.services.s3.S3Client;
import software.amazon.awssdk.services.s3.model.CompleteMultipartUploadRequest;
import software.amazon.awssdk.services.s3.model.CreateMultipartUploadRequest;
import software.amazon.awssdk.services.s3.model.UploadPartRequest;
import software.amazon.awssdk.services.s3.model.CompleteMultipartUploadResponse;
import software.amazon.awssdk.services.s3.model.CompletedPart;
import java.io.InputStream;
import java.util.List;
import java.util.ArrayList;
public class LargeFileUploadHandler implements RequestHandler<Map<String, Object>, String> {
private final S3Client s3Client = S3Client.builder().build();
@Override
public String handleRequest(Map<String, Object> input, Context context) {
// Retrieve file chunk and metadata from input
InputStream fileChunk = (InputStream) input.get("fileChunk");
String fileName = (String) input.get("fileName");
// Prepare S3 multipart upload
CreateMultipartUploadRequest createMultipartUploadRequest = CreateMultipartUploadRequest.builder()
.bucket("YOUR_S3_BUCKET")
.key(fileName)
.build();
String uploadId = s3Client.createMultipartUpload(createMultipartUploadRequest).uploadId();
List<CompletedPart> completedParts = new ArrayList<>();
// Upload each file part
for (int partNumber = 1; hasMoreParts(); partNumber++) {
UploadPartRequest uploadPartRequest = UploadPartRequest.builder()
.bucket("YOUR_S3_BUCKET")
.key(fileName)
.uploadId(uploadId)
.partNumber(partNumber)
.build();
// Here we would process the InputStream and send to S3
CompletedPart completedPart = CompletedPart.builder()
.partNumber(partNumber)
.eTag("etag-placeholder")
.build();
completedParts.add(completedPart);
}
// Complete the upload
CompleteMultipartUploadRequest completeMultipartUploadRequest = CompleteMultipartUploadRequest.builder()
.bucket("YOUR_S3_BUCKET")
.key(fileName)
.uploadId(uploadId)
.multipartUpload(completedParts)
.build();
CompleteMultipartUploadResponse completeMultipartUploadResponse = s3Client.completeMultipartUpload(completeMultipartUploadRequest);
return "File uploaded to S3: " + completeMultipartUploadResponse.key();
}
private boolean hasMoreParts() {
// Logic to determine if more parts exist
return true;
}
}
2. Breaking Down the Lambda Function
2.1 Multipart Upload in S3
Multipart upload is an essential feature in S3 that allows you to split your upload into smaller parts. Each part can be uploaded separately, and only when all parts are uploaded can the final object be assembled in S3. This process greatly increases the efficiency and resilience of the file upload process.
2.2 S3 Client Configuration in Lambda
To interact with AWS S3 in your Lambda function, you’ll need to configure an S3 client. Using AWS SDK version 2 (compatible with Java 17), you can easily manage the multipart upload process. The UploadPartRequest is where you specify the file chunk that is being uploaded, while CompleteMultipartUploadRequest signals that the file upload is finished.
2.3 Handling Large File Parts Efficiently
When processing large files, it is critical to handle the incoming streams correctly to prevent memory overload. Using streams ensures that only a small part of the file is loaded into memory at any given time, keeping the Lambda function's memory usage within safe limits.
Once the Lambda function and front-end are set up, you can test the file upload by selecting a large file. The file will be chunked and uploaded piece by piece to the Lambda function, which will store it in an S3 bucket.
You can validate the success by checking your S3 bucket, where the uploaded file should appear in its entirety after all parts have been uploaded.
3. Conclusion
Uploading large files from a front-end application to an AWS Lambda function, which then stores the files in Amazon S3, is a powerful solution for modern web applications. By using chunked uploads and S3’s multipart upload capability, you can bypass Lambda’s resource limitations and efficiently handle large file uploads.
If you have any questions or need further clarification, feel free to leave a comment below!
Read posts more at : Techniques for Uploading Large Files in Chunks to S3 Using Lambda Functions with Java 17

Top comments (0)