
TL;DR: Make is a 48-year-old build automation tool that's still incredibly useful today. This post explains how Makefiles work, why they're awesome despite their cryptic syntax, and shows practical examples for modern development workflows - from Terraform automation to local dev environments. You can even use Amazon Q Developer CLI to generate Makefiles without becoming a Make expert! Stop hammering that up arrow key and start automating your development tasks. 🚀
Table of Contents:
Alright, I am sure everyone has heard of make, a critical tool in the world of software development that has been primarily used for build automation. But have you really used it? Like, have you seen what it can do? Well in this post, I will go over the history of make, how it works, some cool use cases (besides just building C software) and how you can benefit from it in the year 2025.
Believe it or not, make is 48 years old (at the time of writing) which makes it older than DNS, BSD Unix, and even TCP/IP. It was made by Stuart Feldman to solve a quite common problem at the time: software developers were forgetting which files needed to be recompiled after making changes to the source code. And back then, you often had limited system time to do your debugging and compilations. Leading to, well, a terrible developer experience!
While I do not have issues forgetting to compile files, I often forget what command does what to my stack and end up mercilessly slamming the up arrow key looking back in my Bash history, hoping the same command is there. Often that is not the case. So, let's see why exactly make.
Why Makefiles
But, Darko, why not just write a deploy.sh or build.sh script and be done with it?
Good catch dear reader, that was the way it was done even back in Stuart's time, but it often involved very complex scripting that at times could be an overkill for your project. Also, the fact that simple scripts would often just brute force build your applications and just recompile everything, would just take too much time. Back then, compiling was expensive and time consuming so you had to be careful. make actually solved that problem by only compiling source code files that have changed and creating an intricate system of dependencies to better orchestrate your build process.
Let's have a look at one simple C project Makefile. Oh yeah, Makefile is a file where you outline how your build, deploy, or whatever is being done. It's what make looks for when it's run:
# Define variables
CC = gcc
CFLAGS = -Wall -g
TARGET = myprogram
# Source files
SRCS = main.c utils.c
OBJS = $(SRCS:.c=.o)
# Default target (build)
all: $(TARGET)
# Link object files to create the executable
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) -o $@ $^
# Compile source files into object files
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
# Clean up generated files
clean:
rm -f $(TARGET) $(OBJS)
# Declare phony targets (targets that don't represent files)
.PHONY: all clean
... Well that looks scary! What is all that!? 🤯
Makefile breakdown
Yes yes, I know! That does look byzantine. The declarative programming language it uses definitely is an artifact of its time, and it takes some getting used to. But I will give you a crash course of what this code does:
# Define variables
CC = gcc
CFLAGS = -Wall -g
TARGET = myprogram
# Source files
SRCS = main.c utils.c
OBJS = $(SRCS:.c=.o)
First, we define all the variables! Actually, to add to the confusion, make calls these macros, but whatever. They are basically variables. And here we define certain things up front so we dont have to manually make changes down in the file. Here we tell it what compiler we are using, what compiler flags we need to set up, and the name of our program. And, as you can see, we also tell it what source files it needs to compile.
Lastly it has this cool little way of defining the OBJS variable (macro, whatever): $(SRCS:.c=.o) which simply put tells it, everything in the SRCS macro but change the .c with .o, essentially making a macro that is equivalent to: OBJS = main.o utils.o
# Default target (build)
all: $(TARGET)
This is what we call a target, basically a code block that will run and it's dependency. The all target will run if we run make all or even just make without any parameter. Because we have $(TARGET) in as it's prerequisite it will run that first. I will cover the way prerequisites work in a little bit. Speaking of $(TARGET)...
# Link object files to create the executable
$(TARGET): $(OBJS)
$(CC) $(CFLAGS) -o $@ $^
This is where the linking happens. As you can see a bunch of macros are here, but also some weird new macros. Let me expand this code into what it would look like if we replaced all the macros with the actual values:
myprogram: main.o utils.o
gcc -Wall -g -o myprogram main.o utils.o
Well that makes more sense! The keys here are the built in macros:$@ and $^. Which point to $(TARGET) and all the prerequisites, respectively. This makes it very dynamic, as it will include all the elements of the $(OBJS) macro automatically.
# Compile source files into object files
%.o: %.c
$(CC) $(CFLAGS) -c $< -o $@
Now, this is actually where the compilation happens. And this is where we see a very powerful make feature called a pattern rule. What this rule says with this %.o: %.c is: "to build any file ending *.o** you need a file with the same name but ending in .c"* - Magical! 🤩
Lastly the actual compilation command just does a bunch of macro expands and appends the prerequisites and targets. For example in our current situation we will get this:
gcc -Wall -g -c main.c -o main.o
AND, since there are two *.c files, we also get this:
gcc -Wall -g -c utils.c -o utils.o
# Clean up generated files
clean:
rm -f $(TARGET) $(OBJS)
This is my favorite part of a Makefile - the clean target! I love this, as no matter how much you start messing up with different compiled objects, you can just run make clean and it will remove all the compiled binaries and objects. Here is where you actually get creative with, and define what clean means for you.
For our example, this command will do the following:
rm -f myprogram main.o utils.o
# Declare phony targets (targets that don't represent files)
.PHONY: all clean
This last bit is also very important. The .PHONY target is necessary in order to prevent conflicts with real files. Basically it tells make that all and clean are not actual files to be created but rather names or commands to be executed.
For example, if we did not have .PHONY declared. And there was a file called clean in your project directory. Running make clean would check if the file clean needs to be rebuilt, establish that the file exists and has no dependencies, and just do nothing ....
Remember kids, always define your .PHONY targets! 👏
Common uses
Okay, so is this thing only used by C software developers? Do I need to whip out my UNIX System V license? Not at all friends, make makes (pun so much intended) a great companion to many software development projects. Let me give you a few examples I've seen floating around.
Terraform automation
My good friend Cobus, a long time Terraform user has used make and Makefiles to further streamline the way he works with the stacks he manages. You can check out the full Makefile here, but here are some cool parts that stuck out for me:
Checking for the operating system in question and setting specific macros based off that:
UNAME:= $(shell uname)
ifeq ($(UNAME),Darwin)
OS_X := true
SHELL := /bin/bash
else
OS_DEB := true
SHELL := /bin/bash
endif
Giving the user the appropriate amount of warning before running terraform destroy:
destroy: check
@echo "Switching to the [$(value ENV)] environment ..."
@terraform workspace select $(value ENV)
@echo "## 💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥 ##"
@echo "Are you really sure you want to completely destroy [$(value ENV)] environment ?"
@echo "## 💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥💥 ##"
@read -p "Press enter to continue"
@terraform destroy \
-var-file="env_vars/$(value ENV).tfvars"
Local Development Environment automation
With a little help from Docker and make you can easily automate creation of local development environments for your software development projects. This allows you to automate certain elements of your development workflow and shift left a lot of your building efforts. While setting up databases and services in local docker containers is possible without make - make, makes it (I am not sorry for any of these puns) way way easier.
Let me show you an example Makefile I've used for some Rust development, where I needed to spin up both Postgres and Redis in a local environment. You can see the full Makefile here
But let's look at some highlights that I find very useful. For example, here we are defining a macro PG_PASSWORD using simple assignment, meaning this expression will be only run once. This is done by using := as the assignment operator, so everytime the $(PG_PASSWORD) is referenced it wont go in and run the openssl command, rather it will just get its value.
We are using this PG_PASSWORD macro in our code to dynamically define the Postgres password.
# Generate a random password (16 characters)
PG_PASSWORD := $(shell openssl rand -base64 12 | tr -d '\n')
Before we actually execute our application, we check if the .env file has been created. If it is not, we tell the user to go ahead and run make setup. But if the file exists, we source it and just cargo run 🚀
# Run with environment variables from .env
run:
@if [ ! -f .env ]; then \
echo "Environment file not found. Run 'make setup' first."; \
exit 1; \
fi
@echo "Loading environment variables and running application..."
@source .env && cargo run
There are so many more examples where make can be used. From video game development, to automatic image resizing, to data processing.
Makefiles 48 years later
Okay, now that you kind of understand the basics of make, you may think to yourself: "Darko, this language is ... what? Why is it so convoluted? Is it even worth my time?".
Well, friend, yes it is! Once you get used to make, you will never go back. But I fully understand the complexity of getting up and running with make if you never did so. So, let's adopt make 48 years later with the help of modern technology. Let me show you how you can use Amazon Q Developer CLI to generate Makefiles for your projects. 🥳
First off, Amazon Q Developer CLI is a command line based Generative AI assistant. But like really, an assistant! It does not only answer coding questions, it actually does stuff for you. From generating code, to writing deployment scripts, to even running commands on your local (and remote) systems! I really like it! 😍
To get started with Amazon Q Developer, you can do so for free by just getting yourself an AWS Builder ID and installing Q CLI. I'll wait ... ⌚
Oh, you're back! Excellent! Let me show you how I use this tool to create various Makefiles for my projects.
My link shortener CDK project
What I got here is a rather straightforward AWS CDK project that sets up my very own link shortener. This stack features some TypeScript, Rust, and HTML as programming languages. And it deploys AWS Lambda functions, DynamoDB Tables and CloudFront distributions. Oh, and it features multiple stacks. Making a Makefile quite a useful thing for managing it.
Here is the rough structure of my project:
.
├── bin
│ └── krtk-rs.ts # CDK app entry point
├── lambda
│ ├── create_link # Lambda function for creating short links
│ ├── get_links # Lambda function for retrieving links
│ └── visit_link # Lambda function for handling link visits
│ └── process_analytics # Lambda function for analytics processing
├── lib
│ ├── certificate-stack.ts # Stack for SSL certificate
│ └── krtk-rs-stack.ts # Main infrastructure stack
├── shared # Shared Rust code
├── website # Frontend assets
│ ├── assets
│ │ └── main.js # Frontend JavaScript
│ └── index.html # Main HTML page
└── test
└── krtk-rs.test.ts # Tests for the CDK stack (not yet implemented)
Within the root of this project I run AWS Q Developer CLI by running q chat. This starts off the command line chat interface.
Now, I always like to ask a bit about what my current project does, so that I add that structured thought to the context itself (although it already has access to my entire repo).
Tell me a bit about what my project does, and how is it built
Then I use the following prompt to have it generate me a Makefile
Help me create a Makefile that will help me automate certain actions needed in developing this stack.
Make sure to include deploy commands for individuals as well as all stacks.
Help me set up local development environments for cargo lambda as well as setting up all the necessary environment variables for them to function.
After a moment or so, it gets me the following results:
# krtk.rs Makefile
# Automates common development and deployment tasks
.PHONY: help install build bootstrap deploy deploy-cert deploy-main local-dev clean test lint env-setup
# Default target
help:
@echo "krtk.rs - Serverless URL Shortener"
@echo ""
@echo "Usage:"
@echo " make install Install all dependencies"
@echo " make build Build the project"
@echo " make bootstrap Bootstrap AWS CDK environment"
@echo " make deploy Deploy all stacks"
@echo " make deploy-cert Deploy only the certificate stack"
@echo " make deploy-main Deploy only the main stack"
@echo " make local-dev Start local development environment"
@echo " make clean Clean build artifacts"
@echo " make test Run tests"
@echo " make lint Run linters"
@echo " make env-setup Set up local environment variables"
# Installation targets
install:
@echo "Installing dependencies..."
npm install
@echo "Installing cargo-lambda..."
cargo install cargo-lambda
@echo "Dependencies installed successfully."
# Build targets
build:
@echo "Building project..."
npm run build
@echo "Building Rust Lambda functions..."
cd lambda/create_link && cargo lambda build --release
cd lambda/get_links && cargo lambda build --release
cd lambda/visit_link && cargo lambda build --release
cd lambda/process_analytics && cargo lambda build --release
@echo "Build completed successfully."
# AWS CDK targets
bootstrap:
@echo "Bootstrapping AWS CDK environment..."
cdk bootstrap
@echo "Bootstrap completed."
deploy:
@echo "Deploying all stacks..."
cdk deploy --all --require-approval never
@echo "Deployment completed."
deploy-cert:
@echo "Deploying certificate stack..."
cdk deploy CertificateStack --require-approval never
@echo "Certificate stack deployed."
deploy-main:
@echo "Deploying main application stack..."
cdk deploy KrtkRsStack --require-approval never
@echo "Main stack deployed."
# Local development
local-dev:
@echo "Starting local development environment..."
@echo "Setting up local DynamoDB..."
docker run -d -p 8000:8000 --name dynamodb-local amazon/dynamodb-local
@echo "Creating local DynamoDB table..."
aws dynamodb create-table \
--table-name local-links \
--attribute-definitions AttributeName=id,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \
--endpoint-url http://localhost:8000 || true
@echo "Starting local API Gateway..."
@echo "Local development environment is ready."
@echo "Run Lambda functions locally with: cargo lambda watch"
# Clean up
clean:
@echo "Cleaning build artifacts..."
rm -rf cdk.out
find lambda -name target -type d -exec rm -rf {} +
@echo "Stopping local DynamoDB..."
docker stop dynamodb-local || true
docker rm dynamodb-local || true
@echo "Clean completed."
# Testing
test:
@echo "Running tests..."
npm test
cd lambda/create_link && cargo test
cd lambda/get_links && cargo test
cd lambda/visit_link && cargo test
cd lambda/process_analytics && cargo test
@echo "Tests completed."
# Linting
lint:
@echo "Running linters..."
npm run lint
cd lambda/create_link && cargo clippy -- -D warnings
cd lambda/get_links && cargo clippy -- -D warnings
cd lambda/visit_link && cargo clippy -- -D warnings
cd lambda/process_analytics && cargo clippy -- -D warnings
@echo "Linting completed."
# Environment setup
env-setup:
@echo "Setting up environment variables for local development..."
@echo "export DYNAMODB_TABLE=local-links" > .env.local
@echo "export DYNAMODB_ENDPOINT=http://localhost:8000" >> .env.local
@echo "export TABLE_NAME=local-links" > .env
@echo "export AWS_REGION=us-east-1" >> .env.local
@echo "export DOMAIN_NAME=localhost" >> .env.local
@echo "Environment variables set up in .env.local"
@echo "Run 'source .env.local' to load these variables."
Wow, that is a lot! And check it out, it even decided to run dynamodb-local in order to emulate my production environment. Storing that information in a .env file so that it can be used during execution. But something is off... It's has decided not to pass the environment variable to my Lambda functions via the cargo lambda watch command. So I ask it nicely:
Make sure that the cargo lambda watch also includes a environment variable for my table name as that is required by my function
s.
Better yet do it by passing the `--env-file` parameter to the cargo lambda watch command, and pass it the path to the `.env` fi
le.
Excellent, now it has changed a part of my Makefile to also include commands to test my Lambda functions:
[...]
# Environment setup (must be run before local-dev or watch commands)
env-setup:
@echo "Setting up environment variables for local development..."
@echo "DYNAMODB_TABLE=local-links" > .env
@echo "TABLE_NAME=local-links" > .env
@echo "DYNAMODB_ENDPOINT=http://localhost:8000" >> .env
@echo "AWS_REGION=us-east-1" >> .env
@echo "DOMAIN_NAME=localhost" >> .env
@echo "Environment variables set up in .env file"
# Local development
local-dev: env-setup
@echo "Starting local development environment..."
@echo "Setting up local DynamoDB..."
docker run -d -p 8000:8000 --name dynamodb-local amazon/dynamodb-local || true
@echo "Creating local DynamoDB table..."
aws dynamodb create-table \
--table-name local-links \
--attribute-definitions AttributeName=id,AttributeType=S \
--key-schema AttributeName=id,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \
--endpoint-url http://localhost:8000 || true
@echo "Local development environment is ready."
@echo "Use 'make watch-<function-name>' to start a local Lambda function."
# Lambda watch commands with environment variables from .env file
watch-create-link: env-setup
@echo "Watching create_link lambda..."
cd lambda/create_link && cargo lambda watch --env-file ../../.env
watch-get-links: env-setup
@echo "Watching get_links lambda..."
cd lambda/get_links && cargo lambda watch --env-file ../../.env
watch-visit-link: env-setup
@echo "Watching visit_link lambda..."
cd lambda/visit_link && cargo lambda watch --env-file ../../.env
watch-process-analytics: env-setup
@echo "Watching process_analytics lambda..."
cd lambda/process_analytics && cargo lambda watch --env-file ../../.env
[...]
I just answered with a big ol' y in q chat and were! Ready to go! 👏 I even get a nice little guide on how to use my brand new Makefile:
I've created a comprehensive Makefile for your krtk.rs project that will help automate development tasks. I've also added a .gitignore file to ensure environment variables and build artifacts aren't committed to your repository.
## Makefile Features
The Makefile includes commands for:
1. Installation and setup:
• make install - Installs npm dependencies and cargo-lambda
• make env-setup - Creates a .env file with local development variables
2. Build and deployment:
• make build - Builds both the CDK project and Rust Lambda functions
• make bootstrap - Bootstraps your AWS CDK environment
• make deploy - Deploys all stacks
• make deploy-cert - Deploys only the certificate stack
• make deploy-main - Deploys only the main application stack
3. Local development:
• make local-dev - Sets up a local DynamoDB instance and creates the required table
• Lambda function development with environment variables:
• make watch-create-link
• make watch-get-links
• make watch-visit-link
• make watch-process-analytics
4. Testing and maintenance:
• make test - Runs tests for both CDK and Lambda functions
• make lint - Runs linters for TypeScript and Rust code
• make clean - Cleans up build artifacts and stops local services
## Environment Variables
The Makefile creates a .env file with these variables:
• DYNAMODB_TABLE=local-links
• DYNAMODB_ENDPOINT=http://localhost:8000
• AWS_REGION=us-east-1
• DOMAIN_NAME=localhost
These are passed to the Lambda functions using the --env-file parameter when running cargo lambda watch.
## Usage
To get started with local development:
bash
# Install dependencies
make install
# Set up local environment and start DynamoDB
make local-dev
# Run a specific Lambda function locally
make watch-create-link
For deployment:
bash
# Deploy all stacks
make deploy
# Or deploy individual stacks
make deploy-cert
make deploy-main
The help command (make or make help) will show all available commands and their descriptions.
Lastly, let's see it in action by running a few make commands! Namely, I want to see how the local development works!
First: make install - this just installs all the packages needed to run my stack.
Next: make local-dev - this configures my local development environment by starting a local version of DynamoDB
Now, I can execute my create-link Lambda function locally, by running: make watch-create-link. This will create a HTTP endpoint where I can interact with my Lambda function like a user would. To invoke it, I can just run the following curl command:
curl -X POST http://10.0.1.11:9000/lambda-url/create_link \
-H "Content-Type: application/json" \
-d '{"url_to_shorten": "https://rup12.net"}'
Let's see ...
Failed to shorten URL 💥 : "Error creating a link - Service Error: ResourceNotFoundException(ResourceNotFoundException { message: Some(\"Requested resource not found\"), meta: ErrorMetadata { code: Some(\"ResourceNotFoundException\"), message: Some(\"Requested resource not found\")
Hmm, well that is a future Darko problem, I guess I need to debug those Rusty Lambda functions! 🤔
Finally, to clean up my development environment, I run: make clean
Working with static websites
Next up, what I have here is a simple landing page for an open source app I've built. It features a static website running on AWS Amplify but is deployed to it using the AWS S3 Integration. So, instead of me going in the AWS Console, uploading the files to S3, going to Amplify and triggering Deploy. Why not have a Makefile do all this for me.
Let's go ask Q:
I need a Makefile for my website here that I upload to a bucket called shuk.rs in my AWS Account.
I want to use the Makefile to deploy the changes there as well as update the AWS Amplify website using the start-deployment aws CLI command.
I will need an app-id for this to work. So get that value as well. Use the AWS CLI profile called `personal`.
Here is the example of the AWS CLI deploy command for amplify:
aws amplify start-deployment --app-id <app_id> \
--branch-name <branch_name> \
--source-url s3://amzn-s3-demo-website-bucket/prefix \
--source-url-type BUCKET_PREFIX`
I made sure to give it the example of the command I want it to run during the deployment. This ensures it gets it right, especially if this is a rather new feature. And I got this command from the documentation page.
Check this out, it actually used the AWS CLI locally to find my app-id for me. What it actually did was first search in us-east-1 and once it could not find it, it tried us-west-2 which worked.
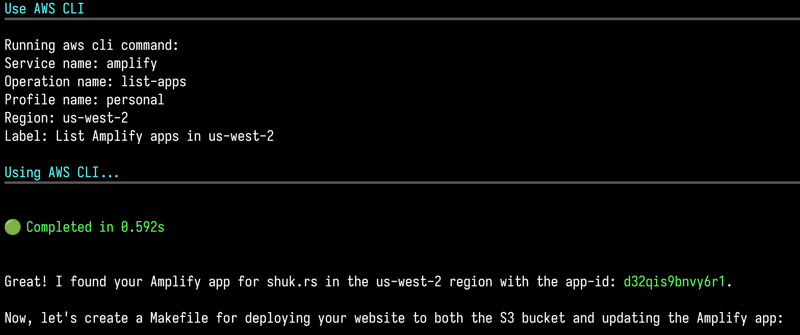
Look at what it built here!
# Makefile for shuk.rs website deployment
# This Makefile handles deployment to both S3 bucket and AWS Amplify
# Configuration
BUCKET_NAME = shuk.rs
REGION = us-west-2
AMPLIFY_APP_ID = d32qis9bnvy6r1
AMPLIFY_BRANCH = staging
AWS_PROFILE = personal
# List of files to deploy
WEBSITE_FILES = index.html install.sh shuk.gif favicon.png
.PHONY: deploy deploy-s3 deploy-amplify clean help
# Default target
help:
@echo "Available targets:"
@echo " deploy - Deploy website to S3 bucket and update Amplify app"
@echo " deploy-s3 - Deploy website to S3 bucket only"
@echo " deploy-amplify - Update Amplify app only"
@echo " clean - Remove any temporary files"
@echo " help - Show this help message"
# Deploy to both S3 and Amplify
deploy: deploy-s3 deploy-amplify
# Deploy to S3 bucket
deploy-s3:
@echo "Deploying website files to S3 bucket $(BUCKET_NAME)..."
@for file in $(WEBSITE_FILES); do \
content_type=$$(case $$file in \
*.html) echo "text/html";; \
*.sh) echo "text/plain";; \
*.gif) echo "image/gif";; \
*.png) echo "image/png";; \
*) echo "application/octet-stream";; \
esac); \
echo "Uploading $$file with content-type: $$content_type"; \
aws s3 cp $$file s3://$(BUCKET_NAME)/ --content-type "$$content_type" --profile $(AWS_PROFILE) --region $(REGION); \
done
@echo "S3 deployment complete!"
# Update Amplify app
deploy-amplify:
@echo "Starting deployment for Amplify app $(AMPLIFY_APP_ID) on branch $(AMPLIFY_BRANCH)..."
@aws amplify start-deployment \
--app-id $(AMPLIFY_APP_ID) \
--branch-name $(AMPLIFY_BRANCH) \
--source-url s3://$(BUCKET_NAME)/ \
--source-url-type BUCKET_PREFIX \
--profile $(AWS_PROFILE) \
--region $(REGION)
@echo "Amplify deployment initiated!"
# Clean any temporary files
clean:
@echo "Cleaning up temporary files..."
@find . -name "*.tmp" -delete
@echo "Clean complete!"
Okay, I cannot have the app-id hardcoded there. So do you remember the little := operator I mentioned at the start? YES! It can actually take an expression and turn it into a command! Lovely! Let's ask it to dynamically get us the app-id during execution.
Can you make it so that you dynamically update the app-id instead of hardcoding it into the make file? The rest can stay hardcoded
And just like that! We have the correct AMPLIFY_APP_ID, which will automatically get us our app-id.
# Makefile for shuk.rs website deployment
# This Makefile handles deployment to both S3 bucket and AWS Amplify
# Configuration
BUCKET_NAME = shuk.rs
REGION = us-west-2
AMPLIFY_BRANCH = staging
AWS_PROFILE = personal
# List of files to deploy
WEBSITE_FILES = index.html install.sh shuk.gif favicon.png
# Dynamically get the Amplify app-id for shuk.rs
AMPLIFY_APP_ID := $(shell aws amplify list-apps --region $(REGION) --profile $(AWS_PROFILE) --query "apps[?name=='shuk.rs'].appId" --output text)
.PHONY: deploy deploy-s3 deploy-amplify clean help check-app-id
[...]
Lastly, I'll make some changes to the index.html and deploy the changes using make deploy
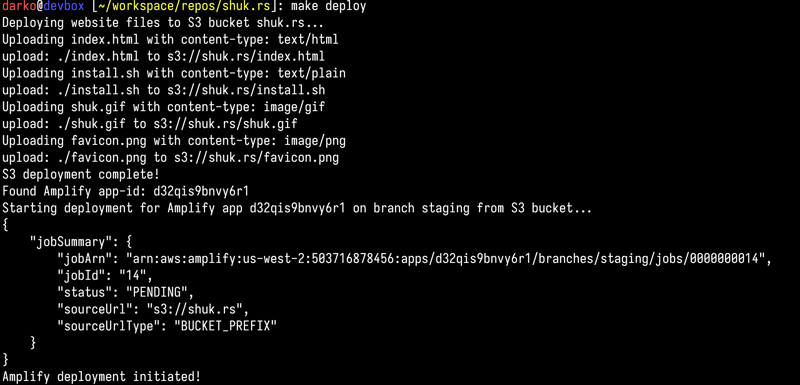
Boom 💥 It's deployed! Thank you make ❤️
Wrap up
Alright friends, I think we have explored plenty about make and how it can help us in our day-to-day developer lives. We've seen that despite being 48 years old, this tool is still incredibly relevant and useful in our modern tech stack. From its origins solving compilation problems at Bell Labs to streamlining our Terraform deployments and website updates, make proves that good tools stand the test of time.
Yes, the syntax can be a bit byzantine at first (those weird macros and pattern rules 🤯), but once you get past that initial learning curve, you'll discover a powerful way to automate repetitive tasks and standardize your workflows. No more mercilessly slamming the up arrow key hoping to find that one command you ran three days ago!
And as we've seen with our examples using AWS Q Developer CLI, you don't even need to be a make expert to start using it. Modern AI tools can help generate sophisticated Makefiles tailored to your projects, whether it's a complex CDK deployment or a simple static website update.
So go ahead, create that Makefile for your project today! Your future self will thank you when you can just type make deploy instead of remembering that 15-parameter AWS CLI command. After nearly five decades, make continues to, well, make our lives easier (sorry not sorry for the pun 😆).
Remember kids, always define your .PHONY targets! 👏

Top comments (16)
Makefiles are especially useful in Golang.
I had one person tell me the exact same thing! Although I would say it's so versatile that it works well with just about anything!
Fun AND profit!?! Sign me up!
Oh yeahhh!!! 🥳
would rather use Taskfiles, simple go.exe file for us Windows users :)
I was told to check out Task! I am yet to do that!
how about just?
github.com/casey/just
Yeah, a few folks mentioned 'just' and also 'task'! So my next step is to try those! 🥳
I'm sold! ;) Thanks for the intro and your explanations how to use make files in a better way.
Added it also to the next issue of the weeklyfoo newsletter.
Thank you Adam! ❤️
ai slop to do product placement for aws. great
Are you calling my writing AI slop? 😭
yes, tell me I am wrong, it's just an empty husk of a post to do product placement. same as the posts that one of the other people who commented here does, another colleague of yours. disgusting practices
In looking at your comment history - You appear to just be a troll who loves to crap on other peoples articles. I would love to see what kind of articles YOU would write, Vincenzo.
no I'm not, I comment with constructive feedback on posts that deserve it
Pls visit my GitHub profile at:
github.com/Debottam1234567890
look at my scam detectors and dream insights projects
hope u have a good time!!