At the last PHPDublin meetup I was asked "What do you do?" and as usual the answer boiled down to "I design and build event sourced applications". Which leads to the following question. "What is Event Sourcing?".
That's where this article came from, it is my best shot at explaining Event Sourcing and all the benefits it brings.
The Status Quo
Before we get into the nitty gritty of event sourcing, let's talk about the status quo of web development.
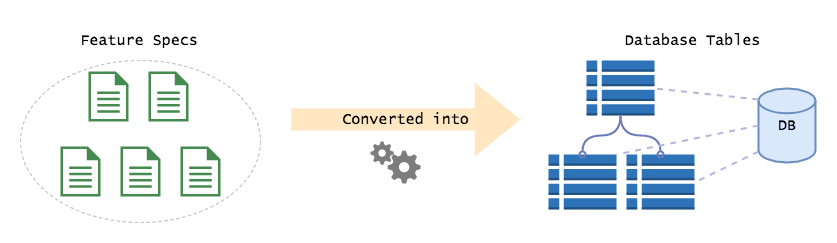
At it's heart, current web dev is database driven. When we design web apps, we immediately translate the specs into concepts from our storage mechanism. If it's MySQL we design the tables, if it's MongoDB, we design the documents. This forces us to think of everything in terms of current state, ie. "How do I store this thing so I can retrieve (and potentially change) it later?".
This approach has three fundamental problems.
1. It's not how we think
We as a species do not think or communicate in terms of state. When I meet you for a coffee and ask "What's happening?", you don't tell me the current state of the world and then expect me to figure out what's changed, that would be insane.
"Well, I have a house, a car, a refrigerator, three social media accounts, a cat, a pain in my right foot, the crippling self-doubt that I'm terrible at conversations, another cat ...etc"
See what I mean? That's crazy. In reality you'd tell me the new things that have happened since we last talked, and from that I'm able to figure out how your world looks now. In short, you tell me a story, and a story at it's simplest is a sequence of events.
2. Single data model
In the above we use the same model for both reads and writes. Typically we'd design our tables from a write perspective, then figure out how to build our queries on-top of those structures. This works for well small apps, but becomes problematic in large ones. You see, it's next to impossible to build a generic model that is optimised for both reads and writes. As the system grows, the queries will get more and more complex, eventually hitting a point where every query contains 10 joins and is 100 lines long. This soon becomes unmaintainable, brittle and expensive to change.
3. We lose business critical information
This is a big one. With a standard table driven system, you're only storing the current state of the world, you have no idea how your system got into that state in the first place. If I were to ask you "How many times has a user changed their email address" could you answer it? What about "How many people added an item to their cart, then removed it, then bought that item a month later"? That's a lot of useful business information that you're losing because of how you happen to store your data!
Event Sourcing
Event Sourcing (ES) is opposite of this. Instead of focussing on current state, you focus on the changes that have occurred over time. It is the practice of modelling your system as a sequence of events.
Let's give an example. Say we have the concept of a "Shopping Cart". We can create a cart, add items to it, remove them, and then check it out.
A cart's lifecycle could be modelled as the following sequence of events:
| Event |
|---|
| 1. Shopping Cart Created |
| 2. Item Added to Cart |
| 3. Item Added to Cart |
| 4. Item Removed from Cart |
| 5. Shopping Cart Checked-Out |
And there we go, that's the full lifecycle of an actual cart, modelled as a sequence of events. That is Event Sourcing. Simple huh!

Pretty much any process can be modelled as a sequence of events. Infact, every process IS modelled as a sequence of events. Talk to a domain expert, they won't talk about "tables" and "joins" (unless you've indoctrinated them into tech concepts), they'll describe processes as the series of events that can occur and the rules applied to them.
How do you enforce business rules?
Most business operations have constraints, a hard rule that cannot be broken. In the above, a hard rule would be "An item must be in a cart before it can be removed". You can't remove an item if it was never added to the cart, that sequence of events should never happen. So to enforce this constraint, you need to answer the question, "Does this item exists?", how do you do that without state?
Turns out this is easy, you just need to check that an "Item Added to Cart" event has happened for that item, then you know the item is in the cart and that it can be removed. Business rule enforced.
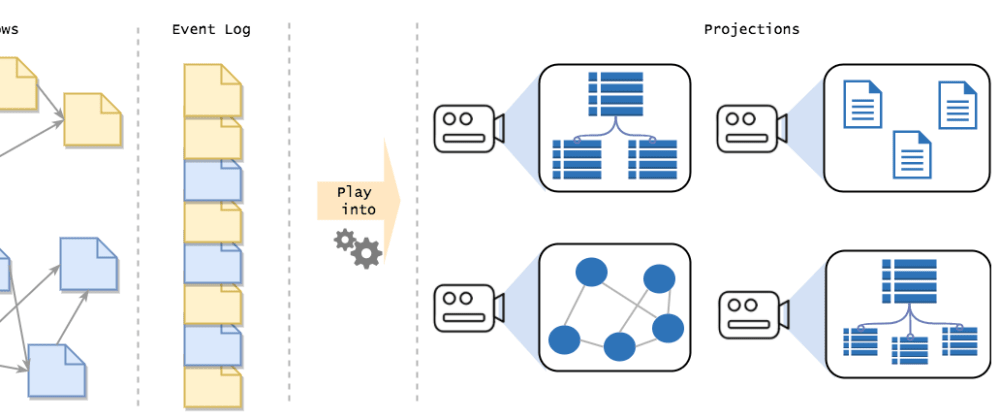
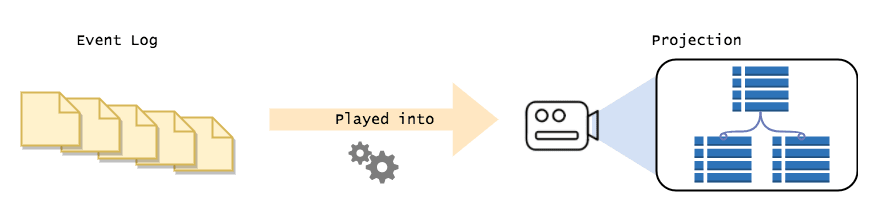
This is how you answer every question about state in an event sourced system, you replay a subset of the events to get the answer you need. The is usually called projecting the events, and the end result is a "projection".
Isn't this expensive and time consuming?
Not at all. To enforce constraints, you typically only need the tiniest subset of events. Fetching the useful history of a concept, such as a Cart, is typically a single database call. You load the events and replay them in memory, "projecting" them, to build up your dataset. This is lighting fast, as you're doing it on the local processor, rather than making a series of SQL calls (network calls are insanely slow compared to local operations, by at least two orders of magnitude!).
What about showing data to the user?
If every piece of state is derived from events, how do you fetch data that needs to be presented to the user? Do you fetch all the events and build the dataset each time?
The answer is no, you don't, that would be ridiculous.
Instead of building it on the fly, you build it in the background, storing the intermediate results in a database. That way, users can query for data, and they will get it in the exact shape they need, with minimal delay. In effect, you cache the results for later use.
Now, this is where things get really interesting. With ES, you are no longer bound by your current table structure. Need to present data in a new shape? Simply build up a new data structure designed to answer that query. This gives you complete freedom to build and implement your read models in any way you want, discarding old models when they're no longer needed.
The benefits
We've looked at a few of the benefits all ready, but lets go deeper, because believe me, this style of development offers a host of benefits that I can no longer live without.
1. Ephemeral data-structures.
Since all state is derived from events, you are no longer bound by the current "state" of your application. If you need to view data in a new way, you simply create a new projection of the data, projecting it into the shape you need. Say bye-bye to messy migration scripts, you can simply create a new projection and discard the old one. I honestly cannot live without this anymore, this alone makes ES worthwhile.
2. Easier to communicate with domain experts
As I said before, domains experts don't think in terms of state, they express business processes as a series of events. By building an event sourced system, we're modelling the system exactly as they describe it, rather than translating it into tech concepts and losing information. This makes communication a lot smoother, we are now talking in their language and this makes all the difference when writing software.
3. Expressive models
Event Sourcing forces you to model events as first class objects, rather than through implicit state changes (ie. changing a value in a table). This means your models will closely resemble the actual processes you're modelling. This brings a lot of clarity to the table and stops you getting lost in the details of your storage technology. It makes the implicit explicit.
4. Reports become painless
Generating complex business reports becomes a walk in the park in an event sourced system. You have the full history of every event that has ever happened, in chronological order, this means you can ask any question you like about that data historically.
Think of the power of this! Take the earlier example, you want to know how many users removed an item from their cart and then bought it a week later. In a standard web app this would take weeks of development, and once it's released, you have to wait for the data to populate before you could generate the report. With an ES system, it's built in from the get go, so you can generate that report right now. You could also generate the report for any previous point in the time. In other words, you have a time machine.
5. Composing services becomes trivial
In standard web dev, plugging two systems together is usually quite tricky, and it frequently leads to tight coupling. ES solves this problem by letting services communicate via events. Need to trigger a process in another service when something happens? Write an event listener that runs whenever that event is fired. This allows you to add new integrations/functionality, without having to modify existing domain code.
For example, say you want to send a welcome email when someone registers. Instead of modifying core registration code, you would simply create an event listener for the "User has Registered" event, which then triggers an email through some external service. Simple.
6. Lightning fast on standard databases
You don't need to use a fancy database to store your events, a standard MySQL table will do just fine. Databases are optimised for append only operations, which means that storing data is fast, while modifying data is slow. This is why ES works so well with current tech, events are append only.
7. Easy to change database implementations
Due to the ephemeral nature of event sourced data-structures, you now have full freedom to use any database technology you like to store state. This means you get to choose the best tool for the job. And If you find a better tool, and you can switch to it at any point, there is zero commitment. This gives you an incredible amount of freedom. Case in point, we're currently moving some of our more complex projections from MySQL to OrientDB, and so far it's been a breeze.
The issues
Like anything, ES is not a free lunch. Here are some of the surprises you will run into.
1. Eventual Consistency
An ES system is naturally eventually consistent. This means that whenever an event occurs, other systems won't hear about it immediately, there is a short delay (say ~100ms) before they receive and process the event, gaining consistency. This means that you can't guarantee that the data in your projections is immediately up-to-date. This sounds like a big deal, but it really isn't. Modern web dev apps built on ReactJS will build up state from actions as the user performs operations, so having a query side that's lagging a few milliseconds is a non issue.
TBH, this is actually a blessing in disguise. Eventually consistent systems are fault tolerant and can handle service outages. If you're building a distributed app using a micro-service or serverless architecture, it needs to be eventually consistency to be stable. See CAP theorm.
2. Event Upgrading
Events will change shape over time, and this can be a bit tricky to handle if you don't plan for it in advance. When an event changes shape, you have to write an upgrader that takes the old event and converts it into the new one. This is done on the fly when you read the events from the store. Think of them as migrations for your events. Not as difficult as it sounds, just have a strategy in place for upgrading events and you'll be fine.
3. Developers need deprogramming
The status quo in web dev is state driven development, this means developers will immediately jump to thinking in tables, rather than events. I've found it takes time to "deprogram" developers, they need to unlearn all the bad habits they've picked up. This usually manifest as events that are pure CRUD and don't mirror the domain language. The best way to combat this is to pair new developers with experienced ESers.
Conclusion
There we have it. At this stage it should be clear that I love event sourcing. It solves all the big problems our team has faced when building large scale distributed business software. It allows us to talk to the business in their language, and it gives us the freedom to change and adapt the system with ease. Throw in built in business analytics and you've got a winning combination. There is a learning curve, but once you get into Event Sourcing, you'll never want to look back, I know I don't.
If you're interested in hearing more about event sourcing, be sure to subscribe to my blog and follow me on twitter. If you'd like to talk further about Event Sourcing, please contact me at barry@tercet.io.





Top comments (72)
My current project is event sourced. I agree it is awesome for all the reasons you describe. I would also add that you can start small and progressively optimize. Small teams don't have to opt into eventual consistency, process managers, snapshots, etc. from the get-go. These can be evolved later as needs arise.
Additional challenge for ES: set validation -- i.e. unique email. To say an email is unique creates a relationship between that email and every other email in the set (mutual exclusivity). Log storage is very inefficient at this type of verification, since you have to replay the entire log every time to validate it.
The party line on set validation has been to keep the set data with the other eventually-consistent read models. Then in the rare case a duplicate email address slipped in before the eventually consistent data got updated, detect the failure (could not add an email to the set), and compensate (notify an admin).
There is also a school of thought that set-based data should just be modeled as relational data, not event sourced. The main loss there is the audit log. Temporal tables could be used to get an audit log, but they are generally more of a pain to work with. That's the tricky part of being an architect: weighing the trade-offs and picking ones which are best for your product.
Agreed, the jury seems to be out on set validation. For that we're using immediately consistent read models, ie. as soon as a
UserCreatedevent is fired we update the projection. This is not an optimal solution though, we have to force allCreateUserusecases to run sequentially. We can't have two running at the same time, or we can't enforce the constraint.If you go with this solution you have to reporting in place to warn you if you're hitting the limit of sequential requests, otherwise requests will start failing.
Once we get these warnings, we're gonna move to the eventual consistent model you mentioned above, and just accept that there could be duplicates.
This isn't a problem unique to event sourcing either. Standard table driven web apps have the exact same problem when it comes to uniqueness across a set, it's just not as obvious that the issue exists. I think it's because DDD and ES forces you to model your constraints explicitly, while in standard web dev it's not as obvious that you're not actually enforcing your set wide constraints.
So I have a line of thought here. Most event sourced systems already have fully-consistent read models in addition to the log itself. Namely, the tables used to track events by aggregate or by event type. They could be reasonably reconstructed from the event log, but they are there as a convenience (an index really) and updated in a fully consistent manner with the event log.
I wonder if it is necessary then that all my read models be eventually consistent. Maybe some of them (especially set-based data) could be fully consistent write models that also get propagated to the read side (if separate databases are used for scaling reads... which is the whole reason for eventual consistency anyway). Then you could validate the set constraint at write time, and even guarantee that duplicates cannot be written (unique index will raise an error if violated while the use case is running) even if the use case checked first, but missed the duplicate due to concurrency. Then there would be no need to make the use cases sequential.
You can definitely do that, and it will work. A unique index will still force sequential operations, but only on that SQL call, rather than the entire usecase, so the likely hood of failure is much smaller.
The only issue is that you have to handle failing usecases. Say the email was written to the read model at the start of the usecase, but some business operation failed and the event was never actually stored in the log. Now you have a read model with invalid data.
If your event log and constraint projections are stored in the same SQL DB, you can solve this with a transaction around the entire usecase (we do this).
There is still the issue of potential failure. Ie. too many requests hitting the DB, but it's not one you need to deal with at the start. You'll only face this when you have massive numbers of people registering at once. We're currently adding monitoring for this, just to warn us if we're reaching that threshhold. It's unlikely we'll reach it, we're not building Facebook/Uber, but it's reassuring to know it's there.
Yes, I was assuming same database as it is the only convenient way to get full consistency. With separate databases, you pretty much have to use eventual consistency. (Well, distributed transactions exist too, but become problematic under load.)
Update. I have a new tactic on this user email issue for our next product. (Using eventual consistency.) We decided to allow a login account to belong to multiple organizations. That means that different orgs are free to create an user account with an email address that is already used. When the user logs in with that email, they will be able to see a dashboard across organizations.
We use an external auth provider that does not allow duplicate email accounts. We have an event sourced process manager that listens for user creation and email changes. We generate a deterministic UUID from the email address and use it as the stream ID to track/control the external auth integration. E.g. Replay the stream to get current state of the integration for that email. And take appropriate action and save events based on current state and the event received.
To make this more resilient, I also add causation IDs to every event that this process manager saves. And when I replay the stream, I verify that the event I just received is not found among the causation IDs of all replayed events. It didn't cost too much code to do this, and it eliminates the possibility of accidentally retriggering side effects/events that were already done before. Since this is an autonomous component, it seemed important to prevent this.
"Validation" is not an issue on its own. This is just a subset of eventual consistency issue. Generally speaking, CQRS is suffering from this, not necessarily the event-sourcing.
I disagree and don't think this is a problem specific to those patterns. I think it is a human nature problem of getting a new data hammer and then every bit of data looks like a nail. It's part of how we learn appropriate uses of the tools, but it's nice when somebody can save you the trouble of learning the hard way.
This is not what I meant. Essentially, the "validation" issue comes each time you have any bit of eventual consistency, where you have to check the system state in a potentially stale store. CQRS is more often eventually consistent and the question of validation comes as a winner in the DDD-CQRS-ES mailing list and on StackOverflow. However, event-sourced system can have a fully-consistent index on something that needs to be validated and therefore this problem can be removed.
I understand what you are saying, but I didn't want to conflate the issue with the universe of DDD/CQRS things. I just wanted to point out that sets are one of the things that log based storage does not do well. Go ahead and look at relational tables for that. Either as the source of truth for set data or -- and I like how you put it -- as an index from log storage.
If your model fits ES+CQRS then go for it. If your model isn't easily described around mutations then don't do it. You can get a lot of power described above by implementing DDD and CQRS without ES. Load an aggregate, call actions to mutate the aggregate and save. You don't lose consistency, you don't need the extra complexity and you still have a single point to generate projections from. For many small systems, ES is no required.
PS: I've design and built insurance systems using EventStore. Insurance policies do run on events. However, for other systems it would be a complex sledge hammer to crack a nut.
Hi Rob, you've clearly got experience working with EventSourced systems, though I'd disagree about stopping at CQRS. CQRS was conceived as a stepping stone to full ES, rather than a destination in and off itself. In CQRS, you now have two write models, the aggregate state and the events. Leading to the question, which one is the source of truth? How do you ensure that the aggregate state is not out of the date with the event stream and vice-versa? Event in a small system this can get confusing. I prefer embracing full ES on the command side, it's simpler and forces you to think temporally.
You do bring up an excellent point around the complexity of reading events to build projections, for small systems this can be killer. I've implemented a similar version to your suggestion; when new events are stored, you also store the aggregate state. It is treated purely as a read model, the aggregate never loads or uses this model,it just writes to it. This gives you something quick to query and to join on for small projections. It's a best of all worlds approach.
I'm sorry but I don't agree. CQRS, as defined by Martin Fowler (originally by Greg Young but his job now is to sell Event Store, so accept his bias) is a separation of the read and write models, nothing more. You do not have two write models, you have one write (source of truth) and one read. The write model can be document or relational model (whatever fits best). It doesn't need to be an event system at all. There is no event stream to keep "in check with".
When you update the aggregate, you can have synchronous and asynchronous pub/sub that update the read side projections. A command, after all is just an object with the changes. The aggregate then consumes the command however your framework decides. That could be to put it into an event stream, straight into an eventing database, or into the loaded aggregate, which in turn knows how to mutate itself before saving.
There are plenty of .NET libraries that show a perfectly good CQRS system that does not need events. For example Brightr brightercommand.github.io/Brighter/
Link to Fowler: martinfowler.com/bliki/CQRS.html
I see your point now, I made the assumption that we were talking about a CQRS event driven system, as opposed to a CQRS system where the query side reads the aggregate state and then updates itself based on that.
I suppose our point of difference is that I prefer modelling through events rather than structure, whereas you feel this is overkill for simple systems.
For me, even in seemingly simple* systems, events allow me to see the actual process, instead of a structural model that implicitly contains that process. I can still model it in a mutable tree structure, but why bother, when the events do it better and more explicitly?
*Caveat, if the simple system is a supporting domain, then ES and even CQRS are probably overkill, I'm not a fanatic (well, only a little bit) :)
No, sorry, you don't understand. Query loads a projection, which is built from the aggregate. You shouldn't load the whole aggregate to query; if you do it's not really CQRS. You denormalise your whole data model; storing projections to minimise impedance mismatch and to maximise query. Quite often that means rdbms for command side and docdb for query. Your infrastructure updates the projections in the docDb a/synchronously using publisher/subscriber model on the aggregate root.
Secondly, it's not about simplicity, it's about the right data model for the right problem. CQRS+ES is just another tool to fit certain problems. I've seen ridiculously complex calculator APIs written in C that run pretty much in memory, dumping usage stats out to postgres. Highly available and enterprise but not simple and not CQRS worthy either.
Don't fixate on one architecture. If you do, you'll find yourself trying to force everything into that form; even when it doesn't fit.
Commands model the process, not the events. The events are the data as stored. Commands create events. You don't model your domain around events but around commands. If you asked a client to write down user stories to work out your aggregates then your end up with commands first (what they are trying to do) then the events to hold the data comes next. Group commands together and you get aggregates.
How the commands then persist the data isn't important. Whether you hydrate your aggregate through events and handlers or through a document/rdbms load is up to the best fit model. Event Store, for example, assumes that your events are immutable. Fine for some applications but not all.
I hope that makes sense.
Hi Rob, thank you for that. I hadn't thought of modelling a CQRS system like that, it's a really nice solution that solves a lot of problems. There's a lot of food for thought above and I appreciate you taking the time to lay it all out for me, and those reading.
The problem that I have is the statement that events, and I then assume that you mean commands also, are not necessarily immutable. Events happen in past tense. They are by definition immutable. A command is issued, whether or not anything happens because of it is irrelevant. The command was issued. Immutable.
Super interesting writeup, this is the first time i hear of Event Sourcing and it would be really interesting to see a sample project that uses this, like an actual cart as in your example. Do you know of any?
Hi Mikael,
I don't have any examples to hand, though there are plenty of them online. The thing about ES, is that everyone has a different way of applying it and structuring their code, so there isn't an example I can point to and say "this is how you should do it".
I may write up an example project in future, if I do, I post a link here.
Hi Barry,
Your writting of the Oreilly Event Sourcing Cookbook is progressing fine ? :-)
Learning how to think event sourcing, what pitfalls to avoid, the smart tricks to keep, etc..
That'd be very valuable.
Event sourcing to the noob sounds like sex to the graduate, it is too much fun not to try it :-)
Stephane
Thanks for the reply!
I checked out geteventstore.com/ and got a good grasp of it, It seems very similar to worker queues that I'm currently working with (Via kr.github.io/beanstalkd/).
Though, no one seems to recommend building a full CRUD app using ES.
Oh yeah, there are times were CRUD is a better fit than ES. If the solution is simple, once off and not the core to your business, building a CRUD app is fine. So CRUD is a workable implementation for a todo list app that's only used by a handful of people internally in the business
If it's anything more complex than that (and most things are), or it's something that is crucial to the success of your business, ES is a better fit. It forces you to understand your domain and it's language, rather than throwing an extra column into a table to hack the a solution in.
To give another example, if you need a blog for your business, for some basic marketing, CRUD is usually fine. If your business is about blogs, understanding how they work and how people use them, then ES is a better fit.
Hope that helps.
Here are some for the axon framework (a Java ES framework): axonframework.org/samples/
Nice
Actually, I just remembered, a friend of mine, @lyonscf , has written a really solid ES example of a Shopping Cart.
github.com/boundedcontext/bounded-...
It's in PHP and written using a framework we co-authored. Look at "Aggregate.php" in a Aggregate/Cart to see the events being applied, and the invariants (synonym for constraint) being checked/enforced. Hope you find it helpful!
This is exactly what I was hoping for and more, thanks! I'll look through it and test it out.
I found this example at Microsoft docs.microsoft.com/en-us/azure/arc..., but sadly no code. Maybe it is of use for you nevertheless. ;)
I find Event Sourcing really interesting, but there are a lot of questions that come into my mind as a newbie in this world. :)
Using this approach requires you (the developer) to model your database using tables to store "events" instead of "entities". Suppose you want to maintain a long list of customer data and retrieve the full list of customers, is it not too slow scanning the entire event table to rebuild the current status of all the available customers?
I know you can do snapshots, but does this approach require you to take snapshots too much often in order to keep everything fast?
Hey Marco,
Glad to answer. In Event Sourcing, you wouldn't have tables per model, you would have one table that stores all the events for your system, this would is called the event log.
If you're using mysql, you'd typically encode the event itself as JSON and just store. You'd also have columns for storing the aggregate (root entity) and the aggregate id (root entity id), so you can easily fetch the subset you need when validating business operations.
Now, this is not optimal for your proposed usecase "retrieve the full list of customers". This is where projections come in. You would create a read model (projection) that is built from all the "customer" events. Everytime a "customer" event is fired, this read model is listening and updates itself.
Hope that answers your question.
Thanks for your really clear answers, Barry.
It seems that for any "trouble" you might encounter applying an ES-based model, there is a workaround to balance disadvantages with benefits.
I will deepen the subject to know more, since the greater obstacle (for me) is more a matter of "mind shifting" than technical shortage. :)
Thanks again!
Would I be right in assuming that if you want to do a query on anything that isn't the aggregate id you'd have to project the entire set for the type in question first?
That's exactly how you'd do it. There are lots of strategies for this, it depends on your usecase.
So the aggregate is not the data in the projection ? What is this aggregate and its aggregate id then ?
From your description, it sounds like your system was event driven (maybe a downstream event processor? fed from a message bus?), but not event-sourced. In an event sourced system, you don't lose events. It would be equivalent to losing a row in a database -- disaster recovery plans kick in.
Integration between systems is more the realm of Event-Driven Architecture. There it is totally possible to miss events or have them delivered out of order, and that is a large part of the challenge with those integrations. Events are a common concept between EDA and ES, but their uses are different.
I currently have an event sourced system which is fully consistent (between event log and read models). Mainly because I did not have time to implement the necessary extra bits to handle eventual consistency. I will add them later as needs arise. Just to say that consistency level is a choice.
I thought fully consistent was "more" or "sooner" consistent than eventually consistent. If you already have fully consistent, why and how to achieve eventually consistent?
By fully consistent, I mean that the event log and the read models are updated in the same transaction. Either all changes happen or not. There's no possibility of inconsistency between them.
Why go eventually consistent? To scale reads. In most systems data is read orders of magnitude more frequently than it is written. In more traditional databases, it is common to see replication employed to make read-only copies of data to handle high read loads. These are eventually consistent (the linked doc says up to 5 minutes!), although not usually called that by name.
How to go eventually consistent with event sourcing? I already have code in place to translate events into SQL statements (required for full consistency). What's still missing to go eventually consistent: 1) Moving event listeners to no longer be co-located with the write-side API. I.e. Hosting them in a different always-running service. 2) Adding checkpointing so each listener can keep track of the last event it saw, in case of restarts. 3) (Optional) A pub/sub mechanism to be notified when new events come in. Alternatively, just poll.
Then I just spin up as many copies of the read model service (and a corresponding database) as I need to handle my read load, and put them behind a load balancer. The read load on the event store is relatively low since each event is read just once per service. As a bonus because events are immutable, you can employ aggressive caching to avoid hitting the database after the first read of each event.
There exists a product -- Event Store -- which does a lot of this already. However there is no good way to opt into full consistency with relational storage. For our new product/team, full consistency between event log and read models saved some time to market. And I have a path for growing into eventual consistency as the need arises. We may switch to Event Store at some point.
Now that's a carefully crafted answer. Rich and accessible content even. I'll keep it in my text memo. Thanks a lot Kasey !
I could not have said that better myself, totally spot on.
Great post! I would like to hear your take about the following issue:
Suppose a user creates a post. The user probably expects to be redirected to this post after creation. But with eventual constistency you can't just send the user to the post page, because you won't know if it already has been created. And sending the post as a response of the POST request would infringe the CQRS model, wouldn't it?
According to Daniel Whittaker there are 4 options to solve this issue:
(1) Block user interactions, wait a certain time and try to load the post
(2) Just display a confirmation screen
(3) Fake the post in the UI
(4) asynchronously push data to the client via e.g. web sockets
So basically I would do something like this:
create postcommandcreate postcommand and validates payloadpost createdeventpost createdevent and pushes created post to the client via web socketsI would love to hear your opinion on how to handle the UI with eventual consistency.
I assume the "logging of the creation event" is immediate and you return to the user when the "event has been saved". Another different thing is if it has been projected or not.
Let's assume that "saving the event" is 10ms and "projecting the post" is 1-second long because you want to post-process the text with fancy codes, links, images and smilies to something very visual.
The first thing to notice is that the user WILL have to wait that 1-second long whatever is the method we use IF we want him to see his post just after posting. (Unless we do something smart! No spoiler, see below, just imagine we need that 1-second delay yes-or-yes at this moment).
In general in ES there are 3 moments in which you can project, which yield in 5 typical real-world scenarios:
1) Force projection just after writing the event, and before returning the control to the user. This maps to your case 1, and is that case in which someone in previous comments say that "I project consistently after writing for simplicity".
2) Do an asynchronous projection: This is when we find eventual consistency in place: We have something in the write-side that we still don't have in the read-side. I've seen this implemented in 3 ways:
2.a) Queues (I really like the idea that Barry said: Use the event as the trigger only, but make the projector to go to the real source-of-truth to find the data). This is often complex to implement specially if you are in an startup with only a few guys doing all the things and with low traffic. Hey! (some of you will think!) Low traffic? How does this affect to difficulty? If you are a startupper and you don't have traffic, you don't have sales, you don't earn money and you'd better employ your time configuring facebook ads than setting up a RabbitMq. Don't you?
2.b) Crons (hey! Don't scare yet!! There's a use case when it fits!): If you really have a very low need of "real time sync" and you can cope with some minutes delay, for example an startup that receives 10 or 20 orders per day, and it does not matter if the order is "sent to John" at 9:56 or 9:59 then go for it... This is (nearly) the biggest time-gap between the write- and the read-side I've seen so far, but makes it very very easy to implement for startuppers that want to have the full story of their new fresh business from the get-go of their new business but can't program anything too complex... Just "project" every 5 minutes and boom! done!
2.c) For even simpler cases, just place a "button" in an admin panel saying "Sync now". Say you want to report sales? Click "update data for sales report" and then make the report. Of course this (requiring a human) is not something very automatic, but works very well for some projections for micro-startups with even fewer people, still getting the full ES power. No queues, no crons. Just a button. Ugly? Probably. Practical? For given use cases, yes. This is actually the biggest time-gap I've seen in the reality. It can sometimes be hours or days. But it does not break anything. Full history, fast reads, fast writes... The only slow moment is when you click to update. The rest goes perfect.
3) On the read! => This is some one that I find very interesting and many times forgotten: You can just "force" re-sync of the projectors "just before reading". This way you have the freshest data available at the expense of having to "wait" if you have "new data" to read.
In your case, the "simplest version" that I see for the case you propose is to do the following:
Okey... so far so good... the user "waited" 1 second (as we expected) and he has the info on the screen, while the "write process" has been immediately released after saving the event.
It works. And it delays ONLY for the FIRST time someone reads that post (ie: the writer unless he closes the browser before redirection in which case the delay will be assumed by the first user that reads it).
As it works, you can "live with that" and focus on other things until you
clear some time for improvements...
There are 2 improvements which can be done, one is not likely to be useful here, but inspires for other use cases, the other really boosts this to a nice solution getting the max power of ES:
Improvement 1) Use of the idempotency property of the projectors
I like very very much the idea of thinking that projectors are idempotent. I mean: You can call a projector many times with nearly zero overload: It'll simply see "there are no new events for this Id, loop over zero elements, exit immediately". The only cost is to "see if there are new events" and this could be negligible in some cases.
What does idempotency translate into? We can "trigger" the projector in many places. For example: From a queue AND when reading.
This way you don't have delays when reading "something that the queue already updated" but just in the case the queue got broken or slow, you reduce eventual consistency making the read "as fresh as possible".
For the post example you are asking about this only would benefit the case of the human writing the post closing the browser before the redirection. The queue would project the posted article and the first time that someone reads, would have it instantly ready instead of having to wait 1 second. But if the queue failed, it'd still be available.
Maybe posting an article is not the best use case to illustrate this improvement, but you get the idea for other use cases: Just you can "trigger" the projector from many places at your will.
Improvement 2) Empower your ES system with multiple projections => Definitively this is a power we should watch much closer...
Every single person advocating for ES says "it's very easy to create more projectors when we need them, projecting to other places".
This is a potential case. Say the "post-processing of the article" takes 1 second as we recurse over the text finding keywords, creating links, substituting things... Let's call this FancyProjector.
But we could have "another" projection that is "faster" for example putting the "flat text" without processing. This projection would nearly be immediate. Let's call this FastProjector.
What can we do?
We can route the "asynchronous" channel (for example a cron or a queue) to the FancyProjector.
And we can route our "force update just before read" channel to the FastProjector.
What happens?
This way, the human posting can have a "nearly immediate sensation" of the UX.
Even more, you still can improve this by placing some websocket so when the content is actually processed by the FancyProjector, the page "substitutes" the "ugly version" for the "nice version"...
So the user sees that "he immediately can start reading his post" and when he goes reading the first or second sentence, some fancy smilies appear there.
But this last one is secondary to what I tried to convey in this response: What I try to express is that "the power of having multiple projections" allow us an unflagging flexibility never seen before.
Conclusion
Of course this is a very personal opinion based on my experiences over the last years, I could be wrong... but all those 5 projection moments are "the moments" we have used in different companies (many of them small startups that don't want to setup queues or so for simplicity) and each of them have a place for each of the needs.
The magick, to me, is to realize of those 3 core ideas of my answer:
Many possible trigger points for the same projector. Even more, I don't need to "choose which" because I can trigger from various points in the same app-release. And I can switch the trigger points as I scale (I may run with crons for 6 months and then implement the queue and just it all works reducing the time-gap, but the projection code is the very same)
Many possible projections for the same data, in function of the use. The classical examples always say "maybe a marketing person wants to see this and an operations person wants to see that" but I call for the idea of "the same person" willing several projections and that "some projections can simply be a fast version of another one".
Any company willing to benefit from the worth of the ES, even the most simple and small micro-startup with nearly no time to do things while they are still working for third parties can (and I encourage to do this) just "store events" and make "very very very simple, ugly, silly and dumb read projections" and work in better ones the next week, or the next month, but still conserve all the history and work bulding from that.
Hope to help.
PD: I take advantage of answering to congratulate Barry for the article.
Really great comment with very valuable information. You have a really deep knowledge about ES. Thank you!
Great article, Barry. Thank you.
I've been looking at ES for a while now. We tend to do DDD in PHP and actually have our aggregates release events to act as our audit log and for event-driven messaging between bounded contexts. However, your article raised a couple of questions for me.
First, re. projections you said:
How do you do this in your PHP applications? The only two options I can think of are:
Do you do either of these or do you do something else (maybe involving a message bus of some kind)?
Second, you said:
What do you mean by "data set"? Do you mean an instance of a PHP class (i.e. take a set of events for a given aggregate, pass them all to the
apply(Event $e)(or similar) method on that aggregate's class and then work with that object) or do you mean something else?Hi Harrison,
Good questions, glad to answer.
On the first one, we have a background PHP process that listens for events and then passes them to the appropriate projection whenever they are received. When an aggregate is stored, it's events are pushed to a queue (Beanstalkd for local env, SQS for staging/production). The queue's PHP client waits for new messages, so it doesn't have to constantly poll. It will timeout eventually, but then you just reconnect and try again.
We use Supervisord to keep the process alive and ensure there's only one instance running.
For queues, we're planning to switch to Kafka in the near future, as it allows each projection to listen to the event queue, and keep track of it's own position, allowing them to update independently.
You could easily make these projections immediately consistent, and I'd actually recommend that for the start, while it's a single monolith, easier to manage.
On the second, that's exactly what I mean, you get the aggregate to replay it's events, building up it's internal data set, you then use this dataset to ensure you're aggregate is making valid state transitions. Eg. Can't login a user is they were never registered in the first place.
Hope the above is useful.
Thanks for your detailed reply, Barry. A few follow-up questions (my apologies for the lack of basic understanding they betray!) ↓
Do you also store those events in a local database? If so, how do you ensure that events are persisted and received by the queue? I could imagine it's problematic if events end up in your database but not in the queue, and it could show the user an error in the UI after the events were persisted locally but before they got onto the queue (leading the user to believe their operation failed despite that being only half true)?
Could you speak a bit more about this? Is the process taking events from your local database and pushing them onto a queue, or do you mean it's receiving from your queue and routing them to projections?
If it's the former, is this something similar to Laravel's queue worker?
If the latter, why does that need to be a process that 'listens' — couldn't you just have your queues invoke the application for each event?
Hey Harrison,
Glad to answer, let's give this shot.
Yes, this is a two phase operation. First the events are written to the database (or whatever storage you use for events), then they're pushed to the queue.
Now, you raise a valid point, what happens if the event is pushed to datastore, but not the queue, or vice versa (equally possible)? This is a long standing problem in any event driven system, and there are a couple of solutions.
In our implementation, writing to the datastore is transactional, once that completes the messages are sent to the queue. The messages are used to tell other systems that something has happened, they're just there to broadcast that a change has occurred, other system will read this message, then query the datastore to see what's actually happened. In other words, the "projectors" don't trust the events on the queue, they just use them as triggers for them to read events from the source of truth, the DB.
This still has the problem of "What if messages don't appear on the queue", but it becomes a problem that sorts itself out once another event appears on the queue, it'll trigger the projectors and they'll update normally.
BTW, we've never had this kind of failure. It's possible, but very unlikely. And even if it did happen, the system will handle it.
Yeah, you pretty got this in your exploration of an answer. It's receiving these events from a queue. In our current implementation, we have a single queue per service. Each service has a process that pulls events of the queue, in the same way as Laravel's queue workers. When an event is received, it queries the event log for the latest events. It then takes the new events, and play them into each projector.
If you'd like to discuss this further, drop me a DM on Twitter, we could arrange a skype call or something. Always glad to discuss.
Thanks. I've sent you a DM.
I would argue that using conventional tables to store events is a good choice. Yes, it seems like it, and you wrote "append only". But indices are there too. We do have a conventional event log (not for an event-sourced system) with indices to query it and it takes hell a lot of time to query anything from there and we often get timeouts writing to it. MS SQL here, well tunes, on powerful machines. So, it is just a matter of time, until you hit this.
For event-sourced system the requirement for your store is at least to have streams. Yes, you can use tables as streams but this is it. You can probably use views but they are virtual. I mean you need real streams, like EventStore has. You can partition your events using projections, with linked events you get references to original events in new streams. This means you can do advanced indexing without paying costs to have conventional RDBMS index, which is optimised for a different purpose.
Also I would argue that having one table for all events is a good choice. Yes, it might make projections easier, having a stream per aggregate makes much more sense. Recovering aggregate from events is much easier then. Running projections to a read model would require to have a per-aggregate-type projection, which in EventStore is elegantly solved by category projections.
Hi Alexey,
Thank you for the excellent feedback. You raise some important points.
As you said, MySQL will work well for now (it solves the problem for the near future, 2+years), after that we've been told that MySQL will start to struggle with the log, exactly as you described. Eventstore is a solid option, we're looking into it and other technologies better suited to massive event streams.
As for the one table for all events, we've had no issues with it. Now, this doesn't mean there's one event log for ALL events, just for the events produced by a service. We're currently indexing by aggregate ID and aggregate Type, so we can easily select the subset we want. We may move to a per aggregate event store, but I'm not happy with this, as it makes it harder to change aggregate boundaries. We have metrics in place to monitor performance, so once it starts becoming problematic we'll be warned and can prepare a solution.
For projection replaying, rather than connecting to the log, we plan for the projections to connect to a copy of the log, optimised for projection reads. We're thinking of using Kafka for this. It will keep the event log indefinitely (if we want it to) and it will at least ensure ordering. This will give us more life out of our MySQL log and also speed up projection rebuilding.
Event migrations and what to do if the event stream gets corrupted is a topic of a full book. I bought and read it and it was worth reading: leanpub.com/esversioning "Versioning in an Event Sourced System" by Greg Young.
I do store the log of events (as Barry pointed out) in MySQL in JSON fields and make some "auto-computed" fields on that JSON to make indexing... When the JSON evolves over time... this is what we do:
Imagine we have this event:
and now we want this (assuming we have at some place a correct conversion table for the airport codes:
And for some reason we don't want to "translate on the fly" and want to have a "coherent data source" with only one single version, here is what we do:
1) We write both an upgrader AND a downgrader
2) We (in staging) get a good snapshot of production
3) We upgrade from Table_1 into Table_2
4) We then downgrade from Table_2 into Table_3
5) We dump tables 1 and 3 and make a diff. If that works it means we did not "forget any critical field".
When we know it works then in production we first upgrade all events, and "mark" the pointer of the "old source" to keep track of "what events where originally from there".
I mean if we had 70 events in the old table and "upgrade" events 1 to 70, then the 71 is written to the new table with the new format. We "mark" somewhere that "the old original table" had "1-70".
Then we start writing to the new table with the new version but still "downgrade" the new events into the old table (this means we have two collections). Our new "source of truth" is the new version but the old one still allows "old projectors to work".
This switching has to be done "in real-time with zero downtime" so many times we have a release that has a flag that allow us to tell "write here or there" and it is changed only once without re-deploying.
This way we "decouple" the coder's needs and we can focus on "writing" and we'll correct "reading" maybe next week. The we progressively upgrade the projectors to read the new version (as both are in place, this allows to work without stress), this can be a matter of several sprints / weeks.
When no projectors are left on the old version and all read from the new version, we first kill the downgrader.
At some moment we do a complete backup (just in case) of the old collection from 1-70 (we don't need the downgraded ones as they were not the source of truth in the old table).
Once the backup is done you can "double-check" asynchronoysly (I mean, maybe the next week) downgrading the 1-70 from the new table to a temporal table and diff with the backup, just to double-check the upgrade was perfect also in production and no bit is lost.
If that's okey, the (unneeded) backup can go to any long-time-storage like AWS Glacier.
If for any reason this double-check failed because there's a new case that was not present the day you did it in pre-production and there's a bug in the upgrader, you still can do this:
1) Create a corrected upgrader.
2) Create a new table and upgrade 1-70 from the backup
3) Copy 71-xxx from the current source of truth to the new table.
4) Switch all the writing to here.
5) Kill all the projections and reset the projection ledgers and re-project all (to avoid anything projected coming from the corrupted upgrade).
(Steps 1 to 3 seem an overkill, it'd seem better to just update events 1-70 in the log, but it's an obsession to me to never UPDATE the Logs. In fact I find a good practice to limit the MySQL user to SELECT and INSERT and hard-forbidding the UPDATE and DELETE on those tables, so even a bug could not corrupt them, so I'm used to always think of those tables as WORM-media).
In fact all the solution might seem an overkill. But I think it's longer "explained" than coded...
The upgrader code normally is SELECT all rows, for each row, hydrate the old event, create a new event from the old event (I use factories for that), store the new event as it was just created now. Rather easy.
There's many litearture on the upgrader. My addition is to "double-check" with the downgrader, to ensure we did not loose any bit of information by accident.
I tend to store any "unneeded data" in the new version into a "metadata" block that many of my projectors just ignore. But the "full history" is there just in case I re-need it again :D
In addition we use "semantic versioning" for the events:
Again... The book is very very very recommended. It all goes about exactly answering to your question.
I'm not sure not sure what you mean, so it's hard to answer.
In terms of migrations, EventSourced apps use migrations for the database backed projections, in the same way regular apps do. If the schema changes shape, you create a migration. So as your systems evolves, you'll get more and more migrations, like any standard web app.
Hope that helps, if it's not on the right track, let me know and I'll do my best to answer.
Good write-up Barry. We did that sort of things in healthcare.. patient get registered, the patient is admitted, diagnosed, discharged etc events. HL7 in healthcare is built on event model and I love it.
Most enterprise systems built with a concept that of events are generated after data is written to the relational data model. The reason being they have been using these events primarily for system integration ( messaging ).
On other hands, event sourcing builds a data model based on event series and payload structure.
Do you agree?
I definitely do. The status quo in enterprise is to write to a relational model, then broadcast events based on those changes. In effect, the events are projections of the relational data, which in my mind is putting the cart before the horse. This is a flavour of CQRS, and is considered a stepping stone in migrating to an Event Sourced system, rather than the end result.
Greg Young talks about it during this talk.
I didn't know HL7 was message based, I'll have to read up on it more, thanks for that!
Having the history is very nice. That is very true.
I use the traditional way: Python/Django/PostgreSQL.
Some tables (not all) have a history-trigger. This logs modification of this table to a history-table.
Thank you for exampling Event Sourcing.
I love enforced data structures and constraints.
Up to now I am not convinced yet.
Hi Barry,
Typos ?
for well small apps
Infact,
The is usually
benefits all ready
to be eventually consistency
Thanks a lot for sharing that with us !
I shall look for some examples or books on how to get my hands dirty.
Cheers,
Stephane
Hi Barry.
I have quite controversial feelings about your article, it seems to be a bit opinionated, but that's a different matter.
I have two questions:
you write : "It allows us to talk to the business in their language". I think this statement is badly lacking an example. How exactly does it help? My experience tells me that it's learning the domain that help to develop a language to speak with the business, not the technology we use.
This one is super-practical.. What do you use as Event Store? I would like to have super-fast writes (obviously) plus at least the easy and fast ability to replay: all events, events in a certain stream, events for a certain object
Hi Victor,
It is definitely opinionated, the goal of the above piece was to sell people on the idea of event sourcing, so they could see the value. My further articles get into more objective discussions of event sourcing and the issues you can encounter, e.g. dev.to/barryosull/immediate-vs-eve... and dev.to/barryosull/event-granularit....
As for your questions:
I think the article explains what I mean quite well. By speaking in terms of events you are actually modelling the domain language. Technology never enters the conversation, only the language used to describe important business state changes, i.e. events. That's how the business owners think about the domain and ES allows you to express that in a way that both developers and domain experts can conceptualise. ES isn't a technology, it's a technique, and one that is used in many mature domains (i.e. law and accounting).
This one is easier to answer. I use MySQL as the event store, as RDBMSs are optimised for append only operations (so super fast writes). I index by the aggregate ID as well, so that it's easy to fetch an aggreate's event stream, and also to lock and ensure only one aggregate instance is updated at a time (aggregates need to be immediately consistent). For projections I would suggest Kafka, it's great for creating and aggregating streams of events, making it easy to spin up projections on the fly (eventually consistent). You could also use Redis streams, but I don't have experience using that technology so I can't give advice, if the idea appeals though here's a list of the pros and cons: logz.io/blog/kafka-vs-redis/
Thanks for a quick reply, Barry!
I also was thinking about RDBMS as event store. MySQL has great performance, and with it's support for JSON datatype it becomes even easier to store arbitrary data. With metadata stored in regular columns (like created_at TIMESTAMP, event_type VARCHAR, aggregate_id INT) you also get lots of abilities to SELECT only required events in proper order. With indexes on metadata columns, SELECTs become fast (although it goes at a price of slightly degraded WRITE performance). Having atomicity in place is another big benefit of RDBMS.
As of business language: I literally think it's a matter of communication skills and domain knowledge spread within the team. At least it's much more about that that about technology in use. I've been talking to business leaving tech questions aside for years (and, well, that means, years before I first heard about ES)
@Barry O Sullivan,
thanks for this wonderful post, I have been reading about event sourcing a lot, and have few doubts can you please me here?
I have a simple CRUD based blogging system with versioning. User see version v1 of a post. He does a put call a new version is created in DB with version v2. If somebody else comes to update the post with version V1, I reject the call saying their version is not latest. and they are forced to refresh their browser.
Here are the problem that i see while doing it with event sourcing
we will have to build a pipe from server to browser because nothing is immediately known. For example if I am updating latest version of the post will only be apparent when I have processed all the events related to this post occurring before current time.
This brings in extra complexity of feedback loop to user. If their operation was successful or not? wait for how long?
Can you please share your thoughts on this? Maybe I am missing the whole point??
Nice job! Really great article.
For those interested in event sourcing I think it's also worth looking at the article by Fowler: martinfowler.com/eaaDev/EventSourc...
Thanks for sharing!