
In a database system, a deadlock happens when two or more transactions wait for one another to release a lock. When this happens, the only course of action for the database engine is to kill one of the transaction to unblock the others.
Here is a simple visualization of a deadlock:
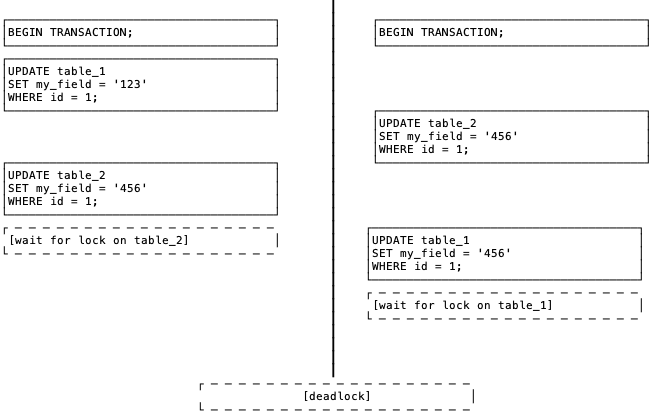
Mitigations
Here are some mitigation steps to avoid deadlocks:
-
Take locks in a consistent order. Deadlocks happen when competing transactions take locks in opposite order. In the PostgreSQL Explicit Locking documentation, the following deadlock example is given:
Session 1:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 11111;Session 2:
UPDATE accounts SET balance = balance + 100.00 WHERE acctnum = 22222; UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 11111;Session 1:
-- DEADLOCK WILL HAPPEN! UPDATE accounts SET balance = balance - 100.00 WHERE acctnum = 22222; -- DEADLOCK HAPPENED!If Session 2 had updated the accounts record
WHERE account = 11111first and thenWHERE account = 22222, which is the same order as Session 1, a deadlock would be avoided. Find long running transactions and make them faster by optimizing or breaking them up into smaller transactions. The longer transactions run, the greater the chance of a deadlock.
Move statements that obtain a lock as far down in a transation as possible, so that the locks are obtained for a shorter duration of time.
Use explicit locking to take less aggressive locks where possible. For example, in SQL Server, evaluate using
READ UNCOMMITTEDisolation level where possible.Depending upon the database system, adding an index may help prevent deadlocks. For example, in SQL Server, a clustered index scan could be blocked by a row lock from another transaction. Adding another index could prevent this.
As a last resort, you could add retry logic to the application. The application could catch a deadlock exception and then let the application gracefully retry until it succeeds. This option should be a last resort since it is working around the root cause of the problem.

Oldest comments (0)