
Introduction
Hypothetical Document Embeddings (HyDE) is a Retrieval-Augmented Generation (RAG) technique used in Large Language Models (LLMs). This blog explains why HyDE was developed and how it improves the RAG process.
Why HyDE?
While RAG works well in most cases, it has a significant limitation: it heavily depends on the vector database to return relevant data chunks based on the user’s query. If the query contains very few or no relevant keywords, the vector database may fail to retrieve the correct data. As a result, the LLM is left without the necessary context, which can lead to hallucinations where the model generates incorrect or misleading information. To address this issue, HyDE was introduced.
How Does HyDE Help?
In HyDE, the data storage process remains the same: domain-specific data is stored in a vector database. However, instead of using the user’s query directly to fetch relevant data from the database, HyDE introduces an additional step.
- The user’s query is first sent to the LLM, which generates a hypothetical response based on its prior knowledge.
- Further, the hallucinated response, along with the original query, is used to perform a search in the vector database.
- This process significantly improves the chances of retrieving relevant data, as the generated response may contain additional context or alternative phrasing that helps the vector database identify the correct chunk of information.
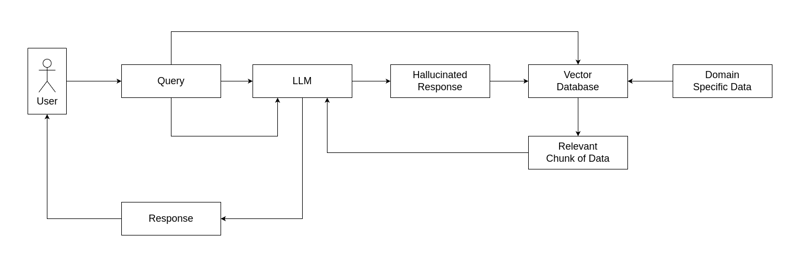
By incorporating this approach, HyDE enhances the RAG process, reducing the likelihood of hallucinations and improving the accuracy of information retrieval.
Final Words
Thank you for reading the blog. If you want to know about RAG, please check the following video. Let me know if you have any questions.

Top comments (0)