Data has always been integral to BuzzFeed’s success. It allows team members to build data-driven products, evaluate how our content is performing, and ask questions to more deeply understand our audience — all to ultimately inform BuzzFeed’s overall strategy and create the best experience for our users.
Our data originates from many sources and covers a large footprint, including anonymized first-party tracking, third party analytics (Google), platform APIs (Facebook, YouTube, Instagram, etc), and internal applications (content metadata from MySQL databases). Where we have control of this data, we’ve worked hard to improve it at the point of creation. Our first-party tracking, for example, was recently redesigned and reimplemented to employ a modular schema design, ensuring consistency and flexibility across all our products.
To meet the increasing demands of these data sets, our Data Engineering group invested significantly in our data infrastructure over the last couple of years. We migrated our data into Google’s BigQuery and reworked our ingestion pipeline to import new data into the warehouse in near real-time. With this foundation in place, we are now ingesting tens of thousands of records per second, totaling nearly 2 TB of data per day. This process is fairly unopinionated; by simply specifying a schema, relevant database dumps or event stream log files get ingested into BigQuery without any transformation.
While the availability of this data in BigQuery in near real-time unlocks a multitude of ways in which it can be leveraged, we quickly realized more data also leads to more problems. In this post we’ll detail these challenges and how we ultimately worked past them to empower our organization to scale its use of data while also simplifying our data infrastructure.
Transforming the Data
BigQuery, while effective at storing large data volumes (totaling over 2 Petabytes across all of BuzzFeed’s datasets), requires special considerations when querying it. All BuzzFeed BigQuery queries share a fixed pool of 2,000 slots — units of computational capacity required to execute the query. BigQuery calculates the number of slots required by each query based on its complexity and amount of data scanned. Inefficient or large queries will not only take longer to execute but can also potentially block or slow other concurrent queries due to the number of slots it requires. Table JOINs in particular can become computationally expensive because of the way that data needs to be coordinated between slots. As such, BigQuery is most performant when data is denormalized.
Since our data is imported into BigQuery in its raw form, we needed a way to optimize it into representations that capture common query patterns and transformations. (So, for example, we want to do things like aggregate individual page view events into hourly totals or create a denormalized representation of our core content metadata.) To achieve this, we’ve built a “Materialized Views” system.
On its surface, the system is fairly straightforward: given a SQL query, run it periodically and save its results in a new table that can be queried independently from its source data. On closer inspection, however, you’ll see a much more complex system that tracks dependencies, schedules and triggers full and partial rebuilds of tables, orchestrates rebuild execution to balance job priorities against the fixed BigQuery slot allocation, provides tooling for creation and validation of views, and enforces change management rules to ensure reliability for downstream consumers of the resulting tables.
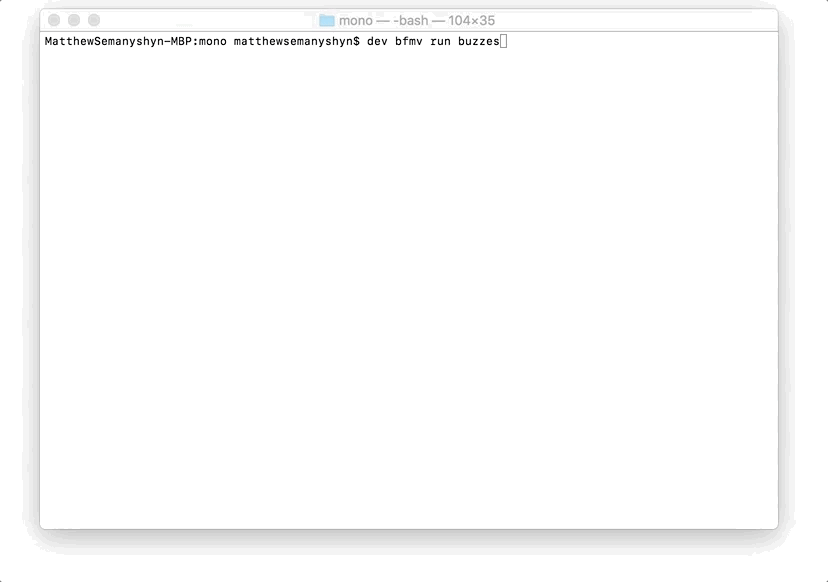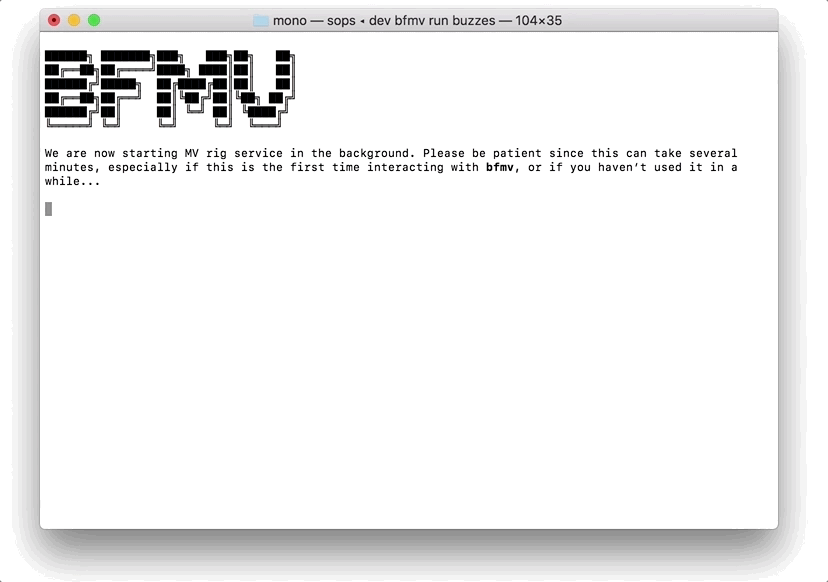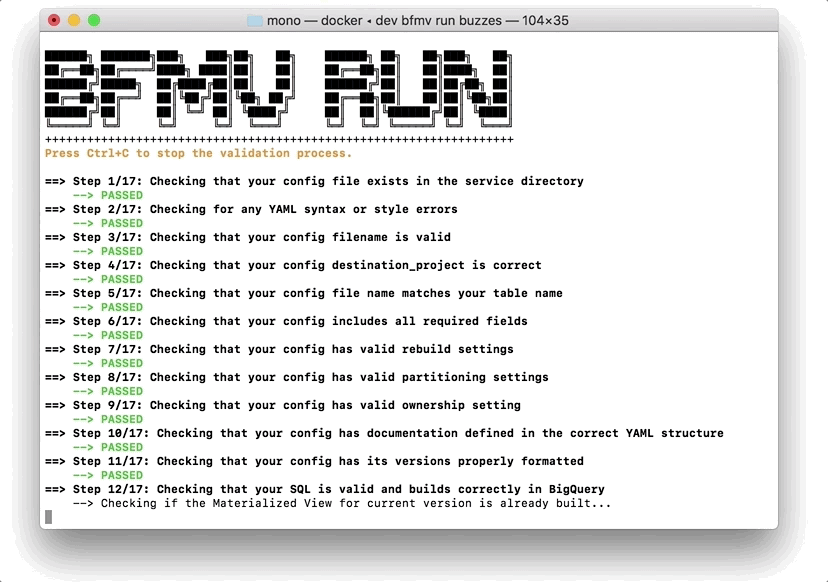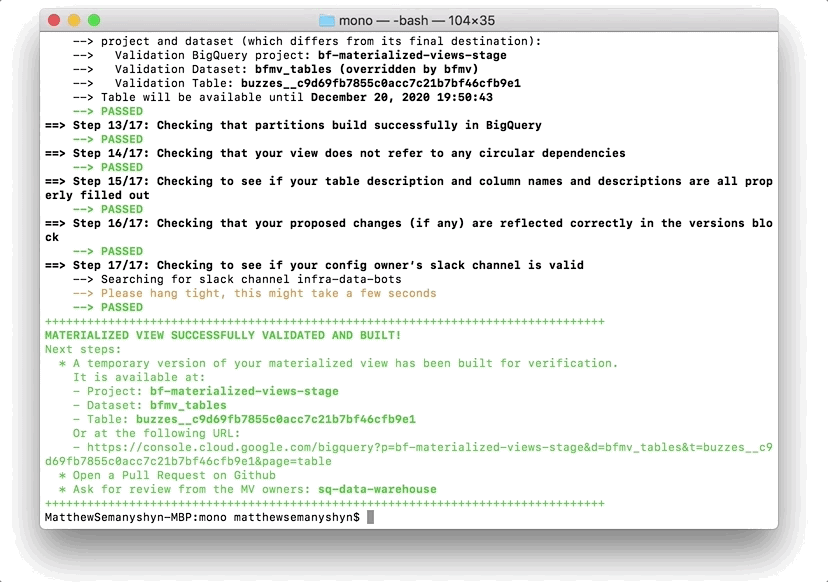
With over 200 views in production, the tables created by the Materialized Views system have become the primary data access point for data in BuzzFeed, supporting over 80% of our reporting.
Standardizing the Data
Given the varied nature of BuzzFeed’s data, understanding what data is available and how it relates can be difficult.

To lower the barrier of entry for working with this data, we’ve introduced the “BuzzFeed Data Model” (BFDM for short). Built by leveraging the Materialized Views system, BFDM provides a standardized and consistent set of tables designed to support a majority of common business use cases. It considers the entire landscape of our raw data and how the various sources relate to one another to provide:
Consistency in data granularity
Regardless of the source, BFDM provides metrics precomputed at hourly, daily, and lifetime granularities (where applicable).Consistency in terminology and naming
By standardizing naming conventions across BFDM, it is easier to find relevant tables, understand what data is available within, and query across them.Clearer relationships
Tables are broken out into one of three types: entities, relationships, and metrics. By understanding a set of common fields available on each, any sets of data can easily be JOINed together.Centralization of business logic
(ie Content categorization, relationships, and grouping rules)Data enrichment, clean-up, and error remediation

This set of tables makes it easier for teams to work with data, simplifies and optimizes queries, and provides a “sanctioned” source of truth for BuzzFeed’s core metrics. Team members are able to seamlessly query different tables without needing to acknowledge a long list of “gotchas” about the data.
Creating a Single Source of Truth
Through the years, various differing (and sometimes redundant) approaches were introduced to BuzzFeed’s data infrastructure:
- Spark jobs aggregated raw page view events into hourly aggregates to be imported into our data warehouse (Redshift prior to BigQuery)
- Looker Persistent Derived Tables transformed data for its own use
- A Redis-backed API served transformed and aggregated data to some internal dashboards
- A Cassandra-backed API served real-time time-series page view aggregates to other dashboards
Not only has each of these legacy pieces increasingly become an operational burden, but they have also allowed for potential inconsistencies.
While our move to BigQuery introduced one more potential source for inconsistency, it also has provided the key components to allow us to decommission each of the legacy systems in favor of one consolidated approach. Remember, we now can import data into BigQuery in near real-time to be transformed by the Materialized Views system into our standardized source of truth, the BuzzFeed Data Model. With this, the same BFDM tables can be used for ad-hoc queries or within BI tools like Looker. By introducing one more system — an API that runs lightweight queries against BFDM — our internal dashboards can be powered by them as well, guaranteeing consistency across all points of data access. (Not to mention reduced technical debt from each of our decommissioned systems!)
Looking to the future
These various efforts have left BuzzFeed on a strong footing to continue leaning into its data-driven culture. However, to continue to succeed into the future, our data-powered approach must be understood, valued, and supported throughout the organization — teams need to use our infrastructure effectively, properly instrument their products with tracking, and help BFDM evolve.
To help achieve this, the Data Group built out Data Governance processes, resources, and organizational structures:

- Comprised of a set of “Data Stewards” representing each engineering team at BuzzFeed, a “Data Governance Council” disseminates established best practices in a scalable manner, opens up channels of communication to evolve these best practices in a way that properly represents each team’s practical needs, and facilitates knowledge sharing and collaboration across the engineering organization on data initiatives.
- A data review process to be completed at the start of any new user-facing initiative helps ensure that the data needs of the project are considered as a first-rate product requirement.
- A data resource center highlights best practices and centralizes documentation for use across the organization.
This work has been a collective effort across BuzzFeed Tech and enables us to explore many new and exciting data-driven initiatives! If you’d like to join us, BuzzFeed Tech is hiring! To browse openings, check out buzzfeed.com/jobs.
You can also follow us on Twitter @buzzfeedexp !

Top comments (0)