This article was originally posted on Cohere's Website with the title Real World Code Incident Report! How We Used the OODA Loop to Triage a Amazon RDS Cascade Failure for a Heroku-hosted Rails App
Notabli reached out to us the day after Christmas because their API was falling over. Their Friendly Engineer, Ty Rauber was working hard with their Head of Product, Jackson Latka, to bring it back up. They wanted a second pair of programmer-eyes, and I was bored. Isn't that what everyone uses the Holidays for? Triaging production issues for fun?
Triaging a Cascade Failure - OODA Loop 1 - Maybe it's the N+1 Query?
We hopped into a Zoom room together with their Product Lead, Jackson Latka and began the debugging process. When debugging, I try to consciously follow the OODA loop: Observe, Orient, Decide and Act.
First, Observe! Jackson granted me rights to manage their Amazon Relational Database Service (RDS), Heroku for hosting, Papertrail for logging and Scout for application monitoring. Huge shout-out to Jackson for the trust he granted, it's the main reason this worked so well. Teams move at the speed of trust, after all!
Second, Orient! I began exploring the architecture with Ty. Notabli's API is a Ruby on Rails application hosted on Heroku. It uses Sidekiq to perform background jobs, many of which are computationally intensive as they process video and images. Further, the main endpoint is a stream of Moments, which is resolved by a number of data fetching operations, one of which is an N + 1 Query, the other of which is a massive cross-table inner join.
Third, Decide! Being (primarily) a programmer, I immediately decided to attempt to resolve the problem via code.
Fourth, Act! Because they use the jsonapi-resources gem, a library I'm personally unfamiliar with, it was difficult to find a seam to begin resolving the query problems. Ty and I blundered through, poking and prodding; but after 15 minutes, we decided this was a dead-end for now.
On reflection, I realized I had violated one of my principles of effective downtime recovery: Attempt to solve downtime first at the infrastructure level before making changes that would require a redeploy of the application. I don't follow this as hard and fast, but it's served me well over the decades.
OODA Loop 2 - Maybe it's the disk?
We went back to observing the AWS dashboard and what did I find? The first major outage had happened when the system ran of storage space!
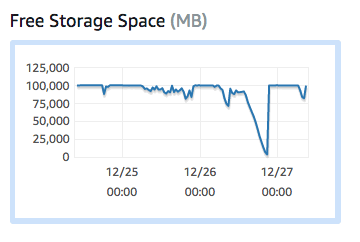
After briefly kicking myself for not noticing that sooner; I dug in a bit further and discovered that right before failure, the server was running at the maximum IOPS it could provide! IOPS, for those whose eyes glaze over when they see a Wikipedia article, is the throughput of read and write disk operations.
Diving in deeper we realized it was the write operations that were using up all the IOPS. I resumed kicking myself for wasting ~30 minutes on mitigating a read related issue; and proposed a two-step bandaid:
- We upgrade the disk, as AWS grants IOPS based on disk-size; this should bring the application back up and allow it to handle the increased traffic.
- Once the system is stable, we look for why there are so many writes and determine if any of them can be removed from the system.
This, thankfully, worked. The application came back up! It maintained a reasonable degree of performance, and there was a reproducible way to bring the application back up in the event the database fell over again.
Unfortunately, because all their work is done on a volunteer basis; we ran out of time to perform step 2!
To help fund the time we're going to spend fixing it, we're offering our friends and followers the opportunity to join us free or with donation on January 15th, 2019 at 10AM PT/1PM ET for a two hour Real World Code Livestream: Preventing Excessive Concurrent Write Induced Cascade Failures in a Heroku Hosted, Amazon RDS Backed Ruby on Rails App. We're not sure if we'll fully diagnose and debug why the write cascade happens in a single session, so we may have a second session on January 29th at the same time!

Top comments (0)