
For workplace safety, the CDC publishes a "Hierarchy of Controls" prioritizing different mechanisms for enhancing worker safety from most effective, to least effective. The principals of reducing physical risk can be mapped to reducing risk in software architecture. Even though the stakes may be lower (depending on your industry), writing reliable software is all about identifying, preventing, and mitigating foreseeable errors.
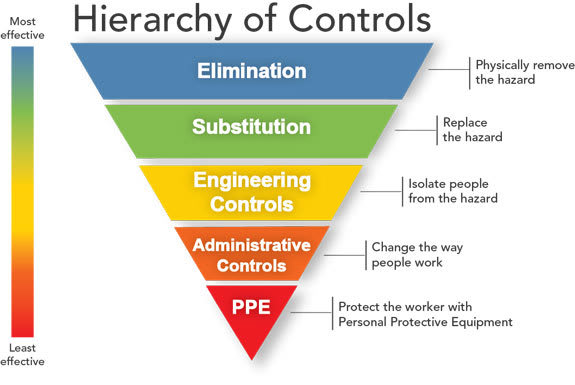
Elimination
In a workplace safety environment, if there's a ladder that can slip while getting items from a high shelf, putting the items on a lower shelf eliminates the need for the ladder. These solutions are often obvious after the fact but overlooked due to assumptions that were never questioned. The problem may be posed as "how can we make the ladder safer", but the fist thing you should ask is "do I need to use a ladder?". As a software example, a web application I've worked with used extensive caching to reduce the load of expensive SQL calls on an aging SQL server. Caching, while critical to performance, was often a source of bugs. When it came time to re-work that system, we used Elasticsearch and pre-populated it with data in the shape of what we needed to query. Without expensive joins, the need for caching that data in the application layer vanished, taking the bugs (at least for that layer) with it.
Substitution
Continuing with the example of the ladder, it may be that space limitations require items to be stored at height. By replacing the ladder with a staircase with railings, a high-risk action (climbing a ladder) is replaced with a low-risk one (climbing stairs). On the software side of things, we often deal with unreliable systems. In one example, a third party API I had to get data from experienced fairly frequent outages causing long page load times. This caused a chain of service degradation. By switching to an asynchronous importer to load data into an internal database, we were able to substitute our dependency on a unreliable system (the API) to a much more reliable one (our database).
Engineering Controls
This is where most of us start our thinking. Occasionally, a risk cannot be eliminated and substituting it would be unreasonably complex or expensive. In the example of the slipping ladder, an engineer can design a stabilization system for the ladder. Perhaps incorporating high-grip rubber or cables to secure it in place. Engineered solutions can add complexity and additional potential points of failure. Likewise, in code, we can write code to handle exceptions, automatically restart failed processes, or reject invalid operations. When coupled with a CI system, automated tests can be a very effective control. However, the more code we add, the more surface area there is for future bugs.
Administrative Controls
When an engineering solution isn't possible, the next least effective solution is to control the human element. If we can't make it so that ladder is unnecessary, and can't make the ladder safer, then we can put up warning signs and require workers to be trained before using the ladder. For developers, these types of controls are everywhere. Coding guidelines, code reviews, and manual QA testing are all administrative controls. These controls can usually be implemented with the stroke of a pen, so even if less effective, they are efficient. These work well as a short term mitigation or when the risk is low, but always consider if a more effective solution is available.
Protective Equipment and Emergency Preparedness
In workplace safety, the last resort is to try to reduce harm. For our ladder, if a worker falls despite everything, a hard hat might mean a broken ankle instead of a skull fracture and having a first aid kit nearby could save their life. We similarly have last-resort procedures in software. Some examples might be a content-delivery network set to return stale content when a service is unhealthy or performing an emergency hotfix deployment to resolve a critical error. Having these plans in place is critical, but when planning for a disaster recovery, always look at the bigger picture of how to eliminate or mitigate the risk before it happens.

Top comments (0)