
ACID Transactions are a must when you have strict data consistency requirements in your application. The costs of running transactions on distributed systems can rapidly create bottlenecks at scale. In this article, we will give you an overview of some of the challenges faced by NoSQL and NewSQL databases. Then, we'll deep dive into how Couchbase implemented a scalable distributed transaction model with no central coordination and no single point of failure. Additionally, I will also give a short overview of how the support for transactions in N1QL looks like on Couchbase 7.0.
Some minor details were omitted for the sake of simplicity.
Relational vs NewSQL vs NoSQL Transactions
Before I start explaining how Couchbase implemented support for transactions, I need to first explain the inherent characteristics of atomicity in relational and NoSQL databases (using semi-structured data models like JSON):
Atomicity in RDBMS
Let's say you need to save a new user in the database. Naturally, as it has many other tables associated with it, inserting a user will also require inserts on many other tables:

Because the relational model forces you to store everything on “boxes” and split your data into small pieces, adding a new user should always run inside of a transactional context. Otherwise, if one of your inserts fail, your user will end up half-saved. Notice how an RDBMS relies heavily on transactions, as applications are far more complex than when the relational model was originally designed back in the seventies.
Luckily, as these databases are designed to run on a single node, you can use a central transaction coordinator to commit the data at once without any performance impact.
Atomicity in NewSQL
On the NewSQL side (distributed relational), things are a little bit more complicated. As most of these databases reuse the relational model, your entity’s data (or aggregate root) tends to be spread throughout multiple nodes.

In the image above, if we need to load the user into memory, we would need to first get the user from Server 1, then load the association between users and roles on Server 2 and finally load the target role from Server 3. This simple operation requires data to travel at least twice over the network, which will ultimately limit your read performance. In a real-world scenario, a user has many more tables associated with it. This is why distributed relational is not yet practical when you need to read/write as fast as possible.
You can try to minimize the issues above by limiting the size of your cluster, by relying heavily on indexes to track all relationships, or by some sharding techniques to keep all related data in the same node (which is difficult to implement in practice). The last two approaches, even when well implemented, will consume significant resources from the database to be managed properly.
ACID transactions in NewSQL databases require more coordination than in NoSQL, as the data related to an entity is split into multiple tables which might live in different nodes. The relational model, as we use today, requires transactions for the majority of the writes, updates, and cascading deletes. The extra coordination that the NewSQL architecture requires comes at a cost of reduced throughput for applications requiring low latency operations.
Atomicity in Document Databases
The use of semi-structured data like JSON can drastically reduce the number of “cross-node joins”, therefore delivering better read/write performance without the need to rely too much on indexing. This was one of the key insights of the Dynamo Paper (first published ~13 years ago) which was the catalyst to create the NoSQL databases as we know them today.
Another interesting characteristic of a semi-structured data model is that it is less transactional, as you could fit the whole user data in a single document:

As you can see in the image above, the user preferences and roles can easily fit inside a “User Document”, so there is no need for a transaction to insert or update a user as the operation is atomic. We insert the document or the whole operation fails. The same is valid for many other common use cases: shopping carts, products, tree structures, and aggregate roots in general.
In the majority of the applications using document databases, 90% of the transactional operations will fall in this single document category. But… what about the other 10%? Well, for those we will need multi-document transaction support, which has been added in Couchbase since version 6.5 and is the main focus of this article.
Here is a presentation about transactions that was delivered at Couchbase Connect 2020. Matt Ingenthron gives you an explanation of when and why you might need multi-document transactions:

Multi-Document Distributed ACID Transactions in Couchbase
Now that you understand how transactions behave in different data models, it is time to deep dive into how we have implemented it at Couchbase and what led to our design choices. First, let’s go through the syntax:
transactions.run((ctx) -> {
// get the account documents for userA and UserB
TransactionJsonDocument userA = ctx.getOrError(collection, "userA");
JsonObject userAContent = userA.contentAsObject();
int userABalance = userAContent.getInt("account_balance");
TransactionJsonDocument userB = ctx.getOrError(collection, "Beth");
JsonObject userBContent = userB.contentAsObject();
int userBBalance = userBContent.getInt("account_balance");
// if userB has sufficient funds, make the transfer
if (userBBalance > transferAmount) {
userAContent.put("account_balance", userABalance + transferAmount);
ctx.replace(userA, userAContent);
userBContent.put("account_balance", userBBalance - transferAmount);
ctx.replace(userB, userBContent);
}
else throw new InsufficientFunds();
});
The Java example above is the classic example of how to transfer money between two clients. Notice that we decided to use a lambda function to express the transaction. Proper error handling can be challenging in this scenario and wrapping your transaction with an anonymous function allows the Couchbase Java SDK to do that work for you (i.e retry if something fails).
When we first launched support for transactions we were trying to avoid verbosity. This was how one competitor's transaction syntax used to look:

Lately, it seems like handling transactions inside lambda functions is becoming the norm for NoSQL databases.
For those who were expecting it to be similar to the relational syntax for transactions (e.g. BEGIN/COMMIT/ROLLBACK SQL commands), keep reading: you can also run transactions through N1QL! Now, let’s try to understand what is happening under the hood.
Couchbase Architecture Review
For those unfamiliar with Couchbase’s architecture, I need to quickly explain 4 important concepts before going any further:
- Couchbase is highly scalable, you can easily go from 1 to 100 nodes in a single cluster with minimal effort (The max size of a cluster is 1024 nodes)
- JSON Documents have a “Meta” space called xAttr where you can store metadata about your document.
Inside each Bucket (similar to a schema in RDBMS), Couchbase automatically distributed the data into 1024 shards called vBuckets. The sharding is totally transparent to the developer, and we also take care of the sharding strategy. Our sharding algorithm (CRC32) essentially guarantees that documents will be evenly distributed between these vBuckets and no resharding is ever needed. The vBuckets are evenly distributed between the nodes of your cluster(e.g. if you have a cluster of 4 nodes, each node contains 256 vBuckets).

The client’s SDK stores a copy of the cluster map, which is a hashmap of vBuckets and the node responsible for them. By hashing the document’s key, the SDK can find in which vBucket the document should be located. And thanks to the cluster map it can talk directly to the node responsible for the document during save/delete/update operations.

The design choices above allow Couchbase to have a masterless architecture (also referred to as master/master) instead of the traditional master/slave used in other NoSQL databases. There are a number of advantages of this kind of architecture, but the ones relevant for us now are the following:
- The SDK saves “one network hop” during insert/update/delete operations as it knows where a given document is located (In the master/slave architecture you have to ask the master where the document is).
- The database itself has no central coordinator, therefore, no single point of failure. In practice, the client acts indirectly as a lightweight coordinator, as it knows exactly which node in the cluster to talk to.
Distributed Transactions without a Central Coordinator
On Couchbase’s architecture, each client is responsible for the coordination of its own transactions. Naturally, everything is done under-the-hood on the SDK level. To put it simply, if you have 100 instances of your application running transactions, then you have potentially ~100 coordinators. These coordinators add next-to-no overhead to your application, and you will soon understand why.
If we reuse the money transfer example shown in our code example and assume that the 2 documents involved in this transaction live in two different nodes, from a 1,000-foot view the transaction follows these steps:
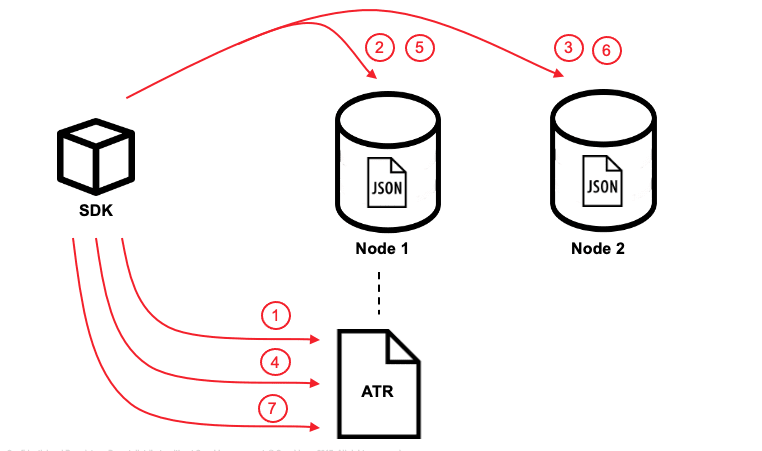
- Each vBucket has a single document responsible for the transaction log called Active Transaction Record (ATR). The ATR can be easily identified by the _txn:atr- id prefix. Before the first document mutation ( ctx.replace(userA, userAContent) in this case) a new entry is added in the ATR in the same vBucket with the transaction id and the “Pending” status. Just one ATR is used per transaction.
- The transaction Id and the content of the first mutation, ctx.replace(userA, userAContent), is staged in the xAttrs of the first document (“userA”).
- The transaction Id and the content of the second mutation, ctx.replace(userB, userBContent), is staged in the xAttrs of the second document “userB”.
- The transaction is marked as “Committed” in the ATR. We also leverage this call to update the list of document ids involved in the transaction.
- Document “userA” is unstaged (removed from xAttrs and replaces the document body)
- Document “userB” is unstaged (removed from xAttrs and replaces the document body)
- The transaction is marked as “Completed” and removed from the ATR
Note that this implementation is not limited by scopes, collections, or shards (vBuckets). In fact, you can even execute transactions across multiple buckets. As long as you have enough permissions, any document inside your cluster can be part of a transaction.
At this point, I assume that you have many questions about all the potential failure scenarios. Let’s try to cover the most important topics here. Feel free to leave comments and I will try to update the article accordingly.
Handling Isolation - Monotonic Atomic View
Jepsen has a brilliant graph that explains the most important consistency models for databases:

Couchbase has support for the Read Committed/Monotonic Atomic View” consistency models. But how good is that? Well, Read Committed is the default choice in Postgres, MySQL, MariaDB and many other databases out there; if you never changed that option, that's what you are using right now.
Read Committed guarantees that your application can’t read uncommitted data, which is what you likely expect from your database, but the interesting part here is how the commit process actually happens. In relational databases, quite often, there is a coordination between the new versions of the rows changed in a transaction to take over their previous ones all at the same time. This is commonly referred to as write-point commit. In order for that to happen, Multiversion Concurrency Control(MVCC) is required. This is problematic because of all the baggage that comes with it, not to mention how expensive it gets (in terms of performance) to be implemented in a distributed database where fast reads/writes are key.
Another disadvantage of write-point commits is that you might spend valuable time synchronizing your commit but … no other thread reads it right after, wasting all effort spent with synchronization. That is when Monotonic Atomic View(MAV) comes into play. It was first described in the Highly Available Transactions: Virtues and Limitations paper and had a great influence on our design.
With MAV we can provide an atomic commit at the read-point instead, which leads to a significant improvement in performance. Let’s see how it works in practice:
Repeatable Reads and Monotonic Atomic Views
In our transaction example, there is a fraction of time after Step 4 where we have set the transaction in the ATR as “Committed” but we haven’t unstaged the data of the documents involved in the transaction yet. So what happens if another client tries to read the data during this interval?

Internally, if by any chance the SDK finds a document that has staged content in it, it will also read the ATR to get the transaction state. If the state is “Committed”, it will return the staged version instead. Boom! No need to synchronize writes if you can simply solve it WHEN it happens on read time.
Durability in a Distributed Database
One of the most important jobs of a database is to ensure that what is written stays written. Even in the event of a node failure, no data should be lost. This is achieved in Couchbase through two features: Bucket Replicas and Durability in the SDK.
During your bucket creation you can configure how many replicas (backups) of each document you want (two is the most common choice). This option allows you to lose N number of nodes without implying any potential data loss.
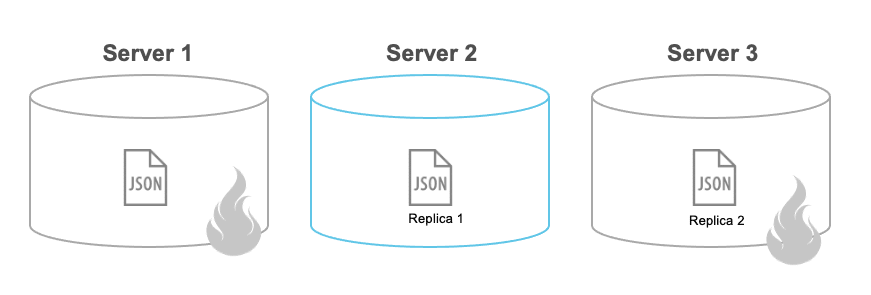
Couchbase is configured by default to always take the fastest approach, so as soon as your data arrives on the server, an acknowledgment will be sent back to the client saying that your write was successful and all data replication will be handled under the hood. However, if your server fails before it gets the chance to replicate the data (we are talking about microseconds to a few milliseconds as the replication is made memory-to-memory) you might naturally lose your change. This might be fine for some low-value data, but .. hey! This totally violates the “durability” in ACID. That is why we allow you to specify your durability requirements:

The MAJORITY (default option in the transaction’s library) in the code above means that the mutation must be replicated to (that is, held in the memory allocated to the bucket on) a majority of the Data Service nodes. The other options are: majorityAndPersistActive, and persistToMajority. Please refer to the official documentation on durability requirements to better understand how it works. This feature can also be used outside of a transaction in case you need to pessimistically guarantee that a document has been saved.
What happens if something fails during a transaction?
You can configure how long your transaction should last before it is rolled back. The default value is 15 seconds. Within this timeframe, if there are concurrency or node issues, we will use a combination of wait and retry until the transaction reaches this time.
If the client managing the transaction suddenly disconnects, it might leave some staged content on the document’s metadata. However, other clients trying to modify the same document can recognize that the staged content can be overwritten as it is part of a transaction that already expired.
Additionally, the transaction library will periodically run cleanups to remove non-active transactions from the ATRs to keep it as small as possible.
Distributed SQL Transactions with N1QL
N1QL is a query language that implements the SQL++ spec, it is compatible with SQL92 but designed for structured and flexible JSON documents. Learn more in this interactive N1QL tutorial.
The distributed transaction solution that we discussed so far is great for application-level transactions. But, sometimes we need to run ad hoc data changes. Or, due to the number of documents involved in the operation, manipulating them in the application memory becomes an expensive operation (e.g. adding 10 credits to all users’ accounts). In Couchbase Server 7.0, you can run transactions through N1QL with virtually the same SQL syntax as most relational databases:
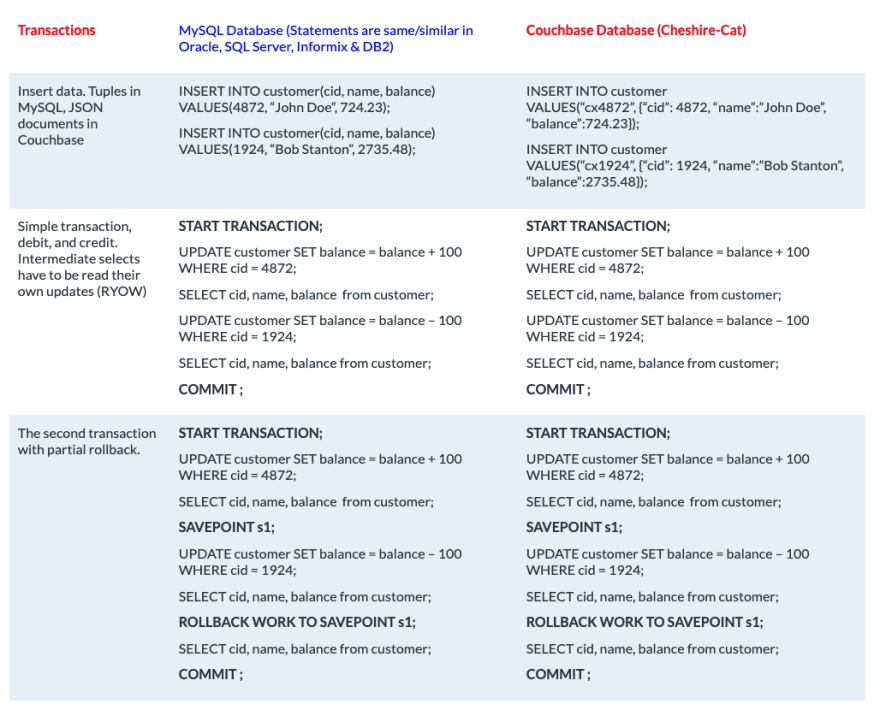
N1QL transactions have already been properly introduced at Couchbase Transactions with N1QL and Use cases and Best Practices for Distributed Transactions through N1QL, so I won’t deep dive on this topic. From a thousand-foot view, the transaction is managed by the query service. Since Couchbase is modular, you can increase your transaction throughput by scaling up or out your nodes running the query service.
You can use both the N1QL and lambda transactions together, but using the transaction library only is preferred whenever possible
Conclusion: The Best NoSQL for Transactions
Couchbase already has had support for atomic single document operations and Optimistic and Pessimistic Locking for a long time. Last year, we introduced fast transactional support regardless of buckets, collections, scopes, or shards. With Couchbase 7.0 you can even use the same traditional relational transaction syntax. The combination of all these features makes Couchbase the best NoSQL for transactions at scale.
Low Cost - Pay for what you use
The total transaction overhead is simply the number of document mutations + 3 (ATR marked as Pending, Committed, and Completed). For instance, running the money transfer example in a transactional context will cost you up to 5 additional calls to the database.
The transaction library is a layer on top of the SDK, we added support for transactions with zero impact on performance (something that other players can’t easily claim). This could only be achieved thanks to our solid architecture.
No Central Transaction Manager or Central Coordinator
Given Couchbase’s masterless architecture and the fact that clients are in charge of managing their own transactions, our implementation has no central coordination and no single point of failure. Even during a node failure, transactions that are not touching documents in the faulty server can still be completed successfully. In fact, with an appropriate max transaction time, even if you touch documents in a node that is failing, Couchbase’s Node Failover can be fast enough to isolate the faulty server and promote a new node before your transaction expires
No Internal Global Clock and no MVCC
Some transaction implementations require the concept of a global clock, which can be expensive to maintain without dedicated hardware in a distributed environment. In some cases, it can even bring the database down if the clock skew is higher than ~250 milliseconds.
With Multiversion Concurrency Control (MVCC) and global clocks, you can technically achieve higher levels of consistency. On the flip side, it will most likely impact the overall performance of the database. Couchbase supports the Read Committed consistency model, which is the same one that relational databases support by default.
Flexibility
You can use the durability options inside and outside of a transactional context, use optimistic and pessimistic locking to avoid potential concurrency issues, and use transactions in the SDK and/or via N1QL. There is a lot of flexibility for you to build any kind of application on top of Couchbase and fine-tune the performance according to your business needs.
What is next?
Here are a few links for you to learn more about what we just discussed and to get started with Couchbase:

Top comments (0)