
Intro :
The rise of artificial intelligence in recent years has been driven by a phenomenon of digitalization that is omnipresent in all professional environments. This digital transformation has been initiated by most companies, large and small, and one of the main axes of transformation is the digitization of data. It is for this purpose that a computer vision service has been developed : Optical Character Recognition (OCR), commonly known as OCR.
The origin of OCR dates back to the 1950s, when David Shepard founded Intelligent Machines Research Corporation (IMRC), the world’s first supplier of OCR systems operated by private companies for converting printed messages into machine language for computer processing.
Today there is no longer a need for a system designed for a particular font. OCR services are intelligent, and OCR is even one of the most important branches of computer vision, and more generally of artificial intelligence. Thanks to OCR, it is possible to obtain a text file from many digital supports:
- PDF file
- PNG, JPG image containing writings
- Handwritten documents
The use of OCR for handwritten documents, images or PDF documents can concern companies in all fields and activities. Some companies may have a more critical need for OCR for character recognition on handwriting, combined with Natural Language Processing (NLP) : text analysis. For example, the banking industry uses OCR to approve cheques (details, signature, name, amount, etc.) or to verify credit cards (card number, name, expiration date, etc.). Many other business sectors make heavy use of OCR, such as health (scanning of patient records), police (license plate recognition) or customs (extraction of passport information), etc.
How OCR works:
OCR technology consists of 3 steps:
Image pre-processing stage, which consists of processing the image so that it can be exploited and optimized to recognize the characters. Pre-processing manipulations include: realignment, de-interference, binarization, line removal, zoning, word detection, script recognition, segmentation, normalization, etc.
Extraction of the statistical properties of the image. This is the key step for locating and identifying the characters in the image, as well as their structures.
Post-processing stage, which consists in reforming the image as it was before the analysis, by highlighting the “bounding boxes” (rectangles delimiting the text in the image) of the identified character sequences:

This article briefly treats how to use OCR with JavaScript. We will see on this article that there are many ways to do it, including open source and cloud APIs engines.
Open source engines are available for free, you can often find those solutions on github. You just need to download the library and use these engines directly from your machine. On the contrary, OCR cloud engines are provided by AI providers, they are selling you requests that you can process via their APIs. They can sell requests with a license model (you pay a monthly subscription corresponding to a certain amount of requests) or a pay-per-use model (you pay only for requests you send).
How to choose between open source and cloud engines ?
When you are looking for a OCR engine, the first question you need to ask you is: which kind of engine am I going to choose?
Of course, the main advantage of open source OCR engines is that they are open source. It means that this is free to use and you can use the code in the way you want. It allows you to potentially modify the source code, hyperparameterize the model. Moreover, you will have no trouble with data privacy because you will have to host the engine with your own server, which also means that you will need to set up this server, maintain it and insure you that you will have enough computing power to handle all the requests.
On the other hand, cloud OCR engines are paying but the AI provider will handle the server for you, maintain and improve the model. In this case, you have to accept that your data will transit to the provider cloud. In exchange, the provider is processing millions of data to provide a very performant engine. The OCR provider also has servers that can support millions of requests per second without losing performance or rapidity.
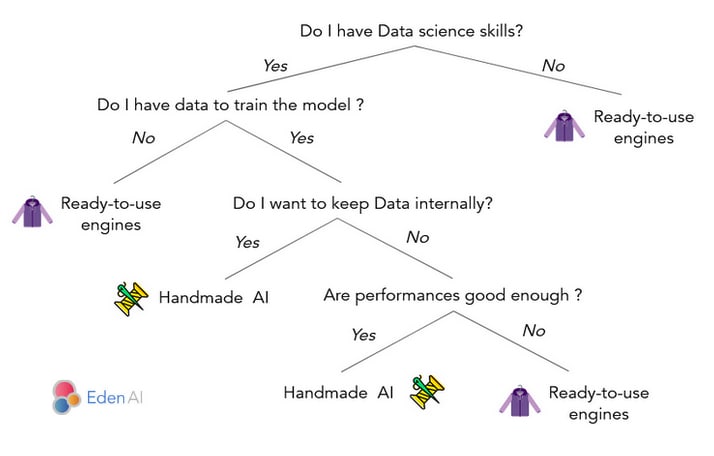
Now that you know the pros and cons of open source and cloud engines, please consider that there is a third option: build your own OCR engine. With this option, you can build the engine based on your own data which guarantees you good performance. You will also be able to keep your data safe and private. However, you will have the same constraint of hosting your engine. Of course, this option can be considered only if you have data science abilities in your company. Here is a summary of when to choose between using existing engines (cloud or open source) and build your own one:
Open Source OCR engines:
There are multiple open source OCR engines available, you can find the majority on github. Here are the most famous ones:
Tesseract:
Tesseract is an optical character recognition (OCR) tool for JavaScript. That is, it will recognize and “read” the text embedded in images.
It exists a wrapper that makes Tesseract work with JavaScript. Tesseract has unicode (UTF-8) support, and can recognize more than 100 languages "out of the box".
Tesseract supports various output formats: plain text, hOCR (HTML), PDF, invisible-text-only PDF, TSV and ALTO.
docTR
docTR is an end-to-end OCR provided by Mindee. It uses a two-stage approach: text detection (localizing words), then text recognition (identify all characters in the word). As such, you can select the architecture used for text detection, and the one for text recognition from the list of available implementations.
Cloud OCR engines:
There are many cloud OCR engines on the market and you will have issues choosing the right one. Here are the best providers of the market:
- Base64
- Cloudmersive
- OCR Space
- Google Cloud Vision Text Recognition
- Amazon Textract
- Microsoft Azure Computer Vision OCR
All those OCR providers can provide you good performance for your project. Depending on the language, the quality, the format, the size of your documents, the best engine can vary between all these providers. The only way to know which provider to choose is to compare the performance with your own data.
Eden AI OCR API:
This is where Eden AI enters in your process. Eden AI OCR API allows you to use engines from all these providers with a unique API, a unique token and a simple JavaScript documentation.
By using Eden AI, you will be able to compare all the providers with your data, change the provider whenever you want and call multiple providers at the same time. You will pay the same price per request as if you had subscribed directly to the providers APIs and you will not lose latency performance.
Here is how to use OCR engines in JavaScript with Eden AI SDK:

If you want to call another provider, you just need to change the value of the parameter “providers”. You can see all providers available in Eden AI documentation. Of course, you can call multiple providers in the same request in order to compare or combine them.
Conclusion
As you could see in this article, there are many options to use OCR with JavaScript. For developers who do not have data science skills or who want to quickly and simply use OCR engines, there are many open source and cloud engines available. Each option presents pros and cons, you know have the clues to choose the best option for you.
If you choose a cloud OCR engine, you will need some help to find the best one according to your data. Moreover, OCR providers often update and train their models. It means that you may have to change your provider’s choice in the future to keep having the best performance for your project. With Eden AI, all this work is simplified and you can set up an OCR engine in JavaScript in less than 5 minutes, and switch to the best provider at any moment.
You can create your Eden AI account here and get your API token to start implementing an OCR engine in JavaScript!

Top comments (0)