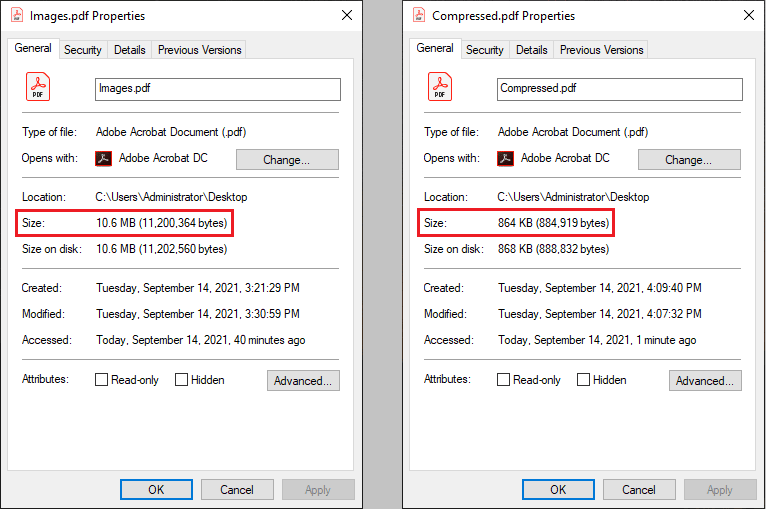
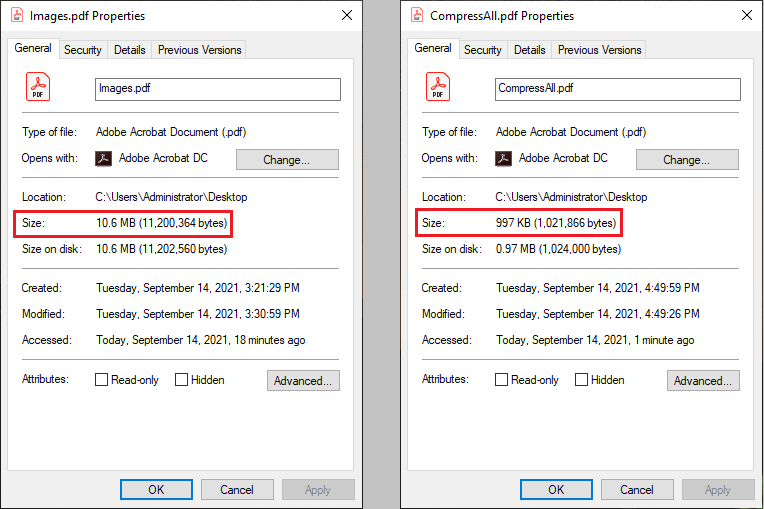
The high quality of the images is often the cause for the large size of a PDF document. Compressing the high-quality images can dramatically reduce the file size by 50% to 90%. In this article, I am going to introduce how to compress PDF images in the following two aspects:
- Automatically compress high-quality images only
- Compress images to a certain extent
Installing Spire.Pdf.jar
If you use Maven, you can easily import the Spire.Pdf.jar in your application by adding the following code to your project’s pom.xml file. For non-Maven projects, download the jar file from this link and manually add it as a dependency in your application.
<repositories>
<repository>
<id>com.e-iceblue</id>
<name>e-iceblue</name>
<url>http://repo.e-iceblue.com/nexus/content/groups/public/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId> e-iceblue</groupId>
<artifactId>spire.pdf</artifactId>
<verson>4.8.7</version>
</dependency>
</dependencies>
Example 1. Compress high-quality images only
Spire.PDF offers PdfPageBase.getImagesInfo() method to retrieve image information from a specific page. The image information includes the image index which is returned by PdfImageInfo.getIndex() method. Then, you can use PdfPageBase.tryCompressImage(int imgIndex) method to compress the specified image.
Kindly note that tryCompressImage() method will compress the high-resolution images only. Low-quality images will no longer be compressed.
import com.spire.pdf.PdfDocument;
import com.spire.pdf.PdfPageBase;
import com.spire.pdf.exporting.PdfImageInfo;
public class CompressHighQualityImage {
public static void main(String[] args) {
//Load the sample PDF document
PdfDocument doc = new PdfDocument("C:\\Users\\Administrator\\Desktop\\Images.pdf");
//Set IncrementalUpdate to false
doc.getFileInfo().setIncrementalUpdate(false);
//Declare a PdfPageBase variable
PdfPageBase page;
//Loop through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
//Get the specific page
page = doc.getPages().get(i);
if (page != null) {
if(page.getImagesInfo() != null){
//Loop through the images in the page
for (PdfImageInfo info: page.getImagesInfo()) {
//Use tryCompressImage method the compress high-resolution images
page.tryCompressImage(info.getIndex());
}
}
}
}
//Save to file
doc.saveToFile("output/Compressed.pdf");
}
}
Example 2. Compress images to a certain extent
After the image information is obtained from a PDF page, we’re able to create a PdfBitmap object based on a specific image. Use the PdfBitmap.setQuality() method to reduce the image quality to a certain extent, and then use the PdfPageBase.replaceImage() method to replace the old image with the compressed image in your document.
import com.spire.license.LicenseProvider;
import com.spire.pdf.*;
import com.spire.pdf.exporting.PdfImageInfo;
import com.spire.pdf.graphics.PdfBitmap;
public class CompressAllImages {
public static void main(String[] args) {
//Load the sample PDF document
PdfDocument doc = new PdfDocument("C:\\Users\\Administrator\\Desktop\\Images.pdf");
//Set IncrementalUpdate to false
doc.getFileInfo().setIncrementalUpdate(false);
//Loop through the pages
for (int i = 0; i < doc.getPages().getCount(); i++) {
//Get the specific page
PdfPageBase page = doc.getPages().get(i);
//Get image info from the page
PdfImageInfo[] images = page.getImagesInfo();
//Determine if there is any image in the pgae
if (images != null && images.length > 0)
//Loop through the images
for (int j = 0; j < images.length; j++) {
//Get the specific image
PdfImageInfo image = images[j];
PdfBitmap bp = new PdfBitmap(image.getImage());
//Reset the image quality
bp.setQuality(40);
//Replace the old image with the compressed image
page.replaceImage(j, bp);
}
}
//Save to file
doc.saveToFile("output/CompressAll.pdf", FileFormat.PDF);
doc.close();
}
}

Top comments (0)