PRE:
In my last engagement, I was tasked with the responsibility of building an API gateway that gets called over a million times a day.
The world of software development/engineering has evolved beyond just developing applications. Enterprise businesses require developers with more advanced skills that allow them to build more efficient, scalable, and extremely FAST applications.
That is where Redis comes in.
I will structure this post into the following headings:
- INTRODUCTION
- INSTALLATION
- BASIC USAGE
- EXTENSION USAGE
INTRODUCTION:
According to the official Redis documentation at (https://redis.io/), Redis is an in-memory data store that is used by millions of developers as a CACHE, VECTOR DATABASE, DOCUMENT DATABASE, STREAMING ENGINE, AND MESSAGE BROKER.
This means that Redis is an in-memory data structure store (of a KEY-VALUE format) that can be used as a:
a. Database
b. Cache
c. Message broker
d. Streaming engine
Redis comes with its built-in data structures that allow Redis to be used for a variety of purposes. These data structures include:
a. Strings
b. Hashes
c. Lists
d. Sets
e. Sorted sets
f. Bitmaps
g. Hyperloglog
h. Geospatial Indexes
i. Streams
Redis also has some built-in functionalities/features like:
a. Replication
b. Lua Scripting
c. LRU eviction (Automatically evict/remove some keys when the cache is full)
d. Transactions
e. Pub/Sub
f. Time To Live (expiration) on keys
Added Features of Redis include:
a. On-disk persistence
b. (High-level availability) Redis Sentinel
c. Redis Cluster
As noted earlier, Redis is an in-memory data store and allows for the low-latency feature of Redis. This makes it possible to use Redis for some real-world use cases:
a. Real-time chat
b. Message Buffers
c. Auth Session stored
d. Media Streaming
e. Realtime Analytics
f. Machine learning, etc.
Redis is also used in industries like Marketing and E-commerce.
In my opinion, Redis is extremely FLEXIBLE and SIMPLE to use, and it requires very minimal setup.
Before we dive into the installations and use case, let's talk about what makes Redis special.
- Every operation on Redis is Atomic (as Redis is single-threaded)
- Data is stored in-memory (not on disk)
But, how or why are these 2 features so important? Right?
-
Let's briefly touch on "Concurrency" in Computer Science:
Say our API is expected to handle multiple requests/second, say over One million requests on its high, there are two ways to handle such huge requests.
a. Multi-threading (it creates a new thread for every incoming request, and uses Mutex and Semaphores to allow data quality and consistency). This leads to unnecessary "Blocking" of threads to ensure the correctness of data when the I/O operation is ongoing. Suitable for CPU-bound tasks (with multi-cored processors).
b. I/O Multiplexing (only a SINGLE THREAD is used to accept all incoming requests from the client). This is the concept JavaScript's "Event Loop" is built upon. It involves "notifying" the single thread when the I/O is free to accept new input/command. Well suited for I/O-bound tasks that require high responsiveness (speed). So the single thread receives a lot of requests (TCP/UDP), and then sends a sequence of requests to the I/O in order. Only send each request to the I/O once it has been notified that the I/O is free to receive a new request.
-
In-Memory storage:
Say we designed and built a database (SQL or NoSQL), then we noticed how slow the data fetching process is, say we have millions of records or rows of data. Our interest is then to find ways of speeding up the database query to as low as possible (this was the challenge I gave myself, to build APIs that can process millions of requests in a fraction of a second).
There are so many optimization processes that can be employed.
Examples include:
i. Database Optimization (improving database query and structure, e.g indexing, data partitioning, etc)
ii. Reducing API calls to the database (caching, batch processing)
iii. Parallel processing, etc.Caching is storing frequently accessed data in-memory (RAM) or in a distributed cache. This process can reduce the need to make repeated calls to the database, and hence, speed up API response time by as much as 10 folds.
From these 2 points, we can see that:
- Redis takes advantage of the speed offered by I/O multiplexing, and
- Redis also leverages the super 10x speed offered by in-memory caching.
These two points show the true beauty of Redis and how it can be leveraged to achieve a true OPTIMIZED API.
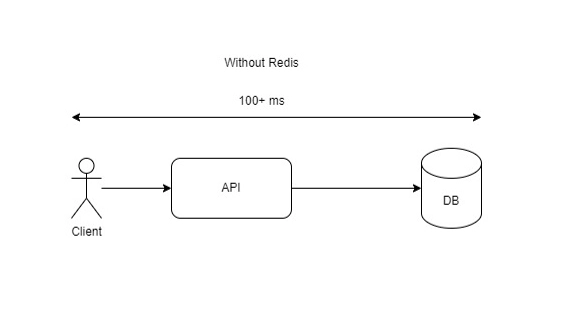
a. API endpoint without Redis cache:
b. API endpoint with Redis cache implemented:
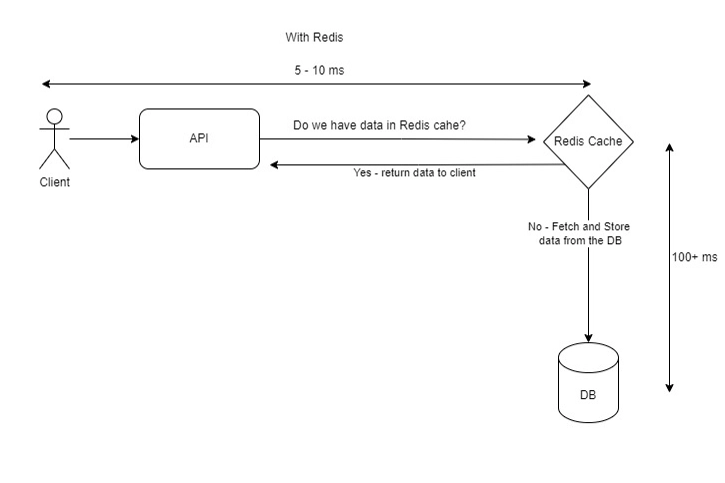
As shown in the two images, we can see how our API response speed has been increased by over 10 folds.
INSTALLATION
Redis is available on Linux, Windows, and MacOS.
Installing Redis on Linux and Mac is straightforward.
a. Linux (Debian based):
sudo apt install redis
b. Mac:
* use Homebrew (I don't know how).
* But please check, I think I read something about Homebrew no longer being supported. Please check the official Redis website.
c. Windows OS:
* So, Windows installation is a little tricky, not really that hard. Just tricky.
Here's how I got it to work.
i. Download the Redis Windows installation file (don't worry about the version, Redis application for Windows is always outdated. 😂)
ii. Install the application like you normally would (please tick the checkbox to add Redis to Path).
iii. After the installation, you can confirm if it was successfully installed by running the following command on your terminal:
$ redis-cli ping
or:
$ redis-cli
If the installation is successful, you will receive either a "PONG" for the first command or a new shell (with IP address) for the second command.
Now to the fun part:
iv. Check the Redis server by typing the following command:
$ redis-server
if you get a response like this (at the tail part):
[18972] 22 Mar 12:16:27.897 # Server initialized
[18972] 22 Mar 12:16:27.909 * DB loaded from disk: 0.010 seconds
[18972] 22 Mar 12:16:27.909 * Ready to accept connections
Then congratulations, everything has been successfully set up.
Else, if there is an error creating a new connection, you will get an error message either stating that "It failed to create a new connection to port 6379" or something like that.
This error occurs because the Redis server has already been started (which is why the redis-cli command was successful too).
If the redis-cli can't connect to the redis-server, it'll notify with this error:
Could not connect to Redis at 127.0.0.1:6379: No connection could be made because the target machine actively refused it.
not connected>
To resolve this:
1. Type this command into your terminal:
$ netstat -ano | findstr :6379
* This will list any process that is making use of port 6379 (the default port for Redis).
* If there is a connection to Redis server (the output of the netstat command above), then you can go further by going into your Task Manager, then find and kill the corresponding process (using the PSID).
* Retry the "redis-server" command again
$ redis-server
2. After the first step has been done, and the redis-cli command is still failing, guess the culprit: Your WSL2 Linux installation.
* This step was what worked for me.
i. I opened my WSL Ubuntu terminal, then uninstalled redis-server from it.
$ sudo apt remove Redis
* This will uninstall Redis from your WSL2 Ubuntu.
ii. Uninstall your Windows Redis installation too
iii. Re-install your Windows Redis application
iv. Enter the command "redis-server" again. If it works, congratulations.
v. Else, just repeat Step 1, it should work this time.
** The whole Windows installation process in summary:
1. Download the (outdated) Windows Redis installation file.
2. Install and click on Add Redis to Path during installation
3. Start Redis server using the command:
$ redis-server
4. If successful, congratulations. If not, check the processes and see if it is already running. Close the process if it is.
5. Retry the command, see if it works. Otherwise, it's most likely the WSL2 Ubuntu running the process in the background. uninstall the Redis server from the wsl2 ubuntu. Then retry the command.
Hopefully, the Redis application is up and running now.
BASIC USAGE
There are many use cases of Redis, but the most common or popular usage is for "CACHING".
There are also several different ways of implementing the caching functionality, and the way I will show is not the best.
- This is just for educational purposes only!
I will be touching on a practical use case of implementing Redis in a Nodejs Application.
Redis uses the concept of a KEY-VALUE pair for storing data.
This means that before any data can be stored, there has to be a given 'name' (index) for the data.
This also allows for the speed of Redis as all data are indexed by default (using the key attributes).
e.g:
- redis-cli> set name "Abdulhakeem"
This is used to add the key "name" to the cache with the value of "Abdulhakeem".
redis-cli> get name
returns "Abdulhakeem"
redis-cli> set age 30
returns "OK" every time we add/del a key
redis-cli> get age
returns 30 ( the value given to the "age" key)
redis-cli> del age
deletes the "age" key as well as the value it holds.
Now, lets see it in action:
Open a terminal and run the redis-server command
$ redis-server
Open your Nodejs application in your IDE, and let us add Redis caching to it.
Create a new redis.js/ts file, and implement all your Redis-related functionalities in it.
redis.utils.js (your choice)
import {createClient} from "redis";
// set up redis
const redisClient = createClient()
await redisClient.connect()
// set up expiration (you can also set it in your .env file)
const EXPIRES_IN = 3600 * 24 * 7 // 7 days
// ############ Redis FUnctions ########## //
// get or set key and value
export const getOrSetCache = async (key, cb) => {
try {
let data = await redisClient.get(key);
if (data != null) return JSON.parse(key)
else {
// run the db query if key not found in cache
data = await cb;
await redisClient.SETEX(key, EXPIRES_IN, JSON.stringify(data)) // save data to cache
return data
}
} catch (error) {
return false
}
}
// get or set List datatype
export const getOrSetListCache = async (key, cb) => {
try{
let data = await redisClient.LRANGE(key, 0, -1); // fetch all elements in the list
if (data.length > 0) return JSON.parse(data);
else {
data = cb;
await redisClient.LPUSH(key, EXPIRES_IN, JSON.stringify({data}));
return data
}
} catch (error) {
return false
}
}
// ... More can be added as desired/needed
Now, to use this redis functions:
import the functions into the file
import UserModel from "./../models/user.model.js"
import {
getOrSetCache,
getOrSetListCache,
} from "./../utils/redis.utils.js";
> Call these functions inside where and when needed:
// get all users
export const getUsers = async (req, res) => {
try {
// create a function to query your database for users
const foundUsers = async () => {
try {
const allUsers = await UserModel.find()
return allUsers
} catch (err) {
return err
}
}
// check the cache for users key or run the function to fetch users from db
const users = await getOrSetCache(allUsers, foundUsers())
return res.status(200).json({
success: true,
message: "Fetched all users!",
data: users
})
} catch (error) {
return res.status(500).json({
success: false,
message: `${error.message}`
})
}
}
You can also call the "getOrSetListCache" function this same way.
But this is used to GET or CREATE a new List key with the element.
I used the LPUSH method (this appends the new element to the top/left of the list) so new elements are at the top, while the old elements are pushed to the bottom (and can easily be removed using the RPOP()).
These simple implementations
EXTENSION USAGE
We've seen how we can implement Redis caching and how we can store or retrieve data from it.
We also briefly touched on setting Expiration time for the key (so we don't have outdated keys in our store).
But what happens on endpoints with millions of records and requests that have been accessed regularly?
For example, we set an expiration on the cache to say 7 days (to minimize the call to d db). If say a user updates his/her record or a new user is added, but the cached record has not yet expired, won't the Redis cache be holding outdated data then?
Two challenges:
- Reduce API calls to the database as much as possible (e.g, databricks tables are not optimal for querying, and they hold too large unstructured data)
- Keep the Redis cache updated with the latest data.
In other to solve these 2 challenges, I created an updateCache function to update the Redis cache every time there is a CRUD call to the database, except GET/READ requests.
The updateCache function is called on every Create, Update, and Delete record that is related to a key in the Redis cache.
This is how I got my Redis to work, how did you implement yours?

Top comments (0)