Here I will show you how to parse a docx file and map it to a Java object (POJO). You can download the final code from this example here: https://github.com/e-reznik/DocxJavaMapper-example.
Technical Background
Docx is a new standard document format, first introduced in 2007 with the release of Microsoft Office 2007. It stores documents as a set of individual folders and files in a zip archive, unlike the old doc format, that uses binary files. Docx files can be opened by Microsoft Word 2007 and later, and by some open source office products, like LibreOffice and OpenOffice. To simply view the contents of a docx, change its extension to .zip and view the resulting archive using any file archiver.

The main content is located in the file document.xml in the folder word. It contains the actual text and some styling information of the entire document. This is the file we will be focusing on in this tutorial.
Detailed information about the structure of a docx can be found at http://officeopenxml.com/anatomyofOOXML.php.
First, we will extract the docx archive. Next, we will read and map the file word/document.xml to a Java object, which can be used for further processing.
Creating an example docx file
We need to create a simple docx that we will be using throughout this tutorial. I created a short text with some simple formatting:

Extracting document.xml
We need to locate and extract the contents of document.xml. As already mentioned, a docx can be handled like a regular zip file. For reading entries from a zip file, Java provides us with the class ZipFile.
We create a new instance and pass our docx file as a parameter to the constructor. To the method public ZipEntry getEntry(String name) we pass the entry that we want to read. In our case, it’s document.xml which is in the folder word. Finally, we return the input stream of that specific entry, so that we can read its contents.
public static InputStream getStreamToDocumentXml(File docx) throws IOException {
ZipFile zipFile = new ZipFile(docx);
ZipEntry zipEntry = zipFile.getEntry("word/document.xml");
return zipFile.getInputStream(zipEntry);
}
We can call that method and save its return value as an InputStream.
String fileName = "example.docx";
InputStream inputStream = Unzipper.getStreamToDocumentXml(new File(fileName));
Viewing and interpreting the results
For testing purposes, we can return the content of the document.xml as a string.
String text = new BufferedReader(
new InputStreamReader(inputStream, StandardCharsets.UTF_8))
.lines()
.collect(Collectors.joining("\n"));
System.out.println(text);
This is the result xml. Can you find and interpret our example text (see above)?
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:document xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" mc:Ignorable="w14 wp14"><w:body><w:p><w:pPr><w:pStyle w:val="Normal"/><w:bidi w:val="0"/><w:jc w:val="left"/><w:rPr><w:color w:val="2A6099"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr></w:pPr><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:u w:val="single"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>This</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> is my </w:t></w:r><w:r><w:rPr><w:b/><w:bCs/><w:i/><w:iCs/><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t>example</w:t></w:r><w:r><w:rPr><w:color w:val="2A6099"/><w:sz w:val="28"/><w:szCs w:val="28"/><w:lang w:val="en-US" w:eastAsia="zh-CN" w:bidi="hi-IN"/></w:rPr><w:t xml:space="preserve"> text.</w:t></w:r></w:p><w:sectPr><w:type w:val="nextPage"/><w:pgSz w:w="11906" w:h="16838"/><w:pgMar w:left="1134" w:right="1134" w:header="0" w:top="1134" w:footer="0" w:bottom="1134" w:gutter="0"/><w:pgNumType w:fmt="decimal"/><w:formProt w:val="false"/><w:textDirection w:val="lrTb"/><w:docGrid w:type="default" w:linePitch="100" w:charSpace="0"/></w:sectPr></w:body></w:document>
The document.xml follows a specific structure displayed below. This illustration only shows the elements, that are relevant in this example.
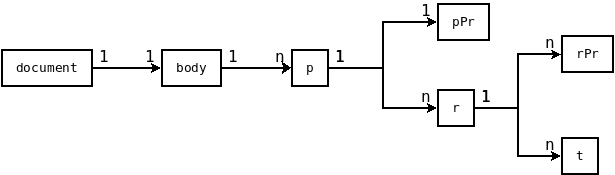
More information about the xml structure in that file can be found at http://officeopenxml.com/WPcontentOverview.php.
Mapping contents to a Java object
Now, that we can read the contents of a docx, we should be able to parse and map it to a POJO. Doing so, we will need to use some tools and create some POJOs in order to map our xml file.
Setting up required tools
-
Maven
- build automation tool
- JAXB
- tool for mapping xml documents and Java objects
- I will use the Eclipse Implementation of JAXB
-
Lombok
- Reduces boilerplate code
You can simply copy the required dependencies in your pom.xml:
<dependency>
<groupId>jakarta.xml.bind</groupId>
<artifactId>jakarta.xml.bind-api</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>com.sun.xml.bind</groupId>
<artifactId>jaxb-impl</artifactId>
<version>3.0.0</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.16</version>
</dependency>
Creating POJOs
In order to be able to map the document.xml to our Java object, we need to create some classes, following the structure of our file (see above).
Every document has 1 node document, which itself has 1 node body. We only need getters in order to access its contents later. The fields can be private. Using the annotations from Lombok and JAXB, the POJO (or DTO) for our document element would look like:
@Getter
@FieldDefaults(level = AccessLevel.PRIVATE)
@XmlRootElement(name = "document")
@XmlAccessorType(XmlAccessType.FIELD)
public class DJMDocument {
@XmlElement(name = "body")
DJMBody body;
}
1 body can have multiple paragraphs, that’s why we need to map the paragraphs to a list. The setter is private, because we only need it internally, inside of the class itself. The POJO for the body looks like:
public class DJMBody {
List<BodyElement> bodyElements;
@XmlElements({
@XmlElement(name = "p", type = DJMParagraph.class)
})
public List<BodyElement> getBodyElements() {
return bodyElements;
}
private void setBodyElements(List<BodyElement> bodyElements) {
this.bodyElements = bodyElements;
}
}
Similarly, we need to create a class for every element that we want to map to. I will not go too much into detail here. As already mentioned, you can find the complete example project in my GitHub account.
Checking the results
After successfully creating all required classes, we want to check whether we can get the actual text of our docx. The following method iterates through the document, finds all the runs, appends their texts to a StringBuffer and returns it:
public static String getTextFromDocument(DJMDocument djmDocument){
StringBuilder stringBuilder = new StringBuilder();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
stringBuilder.append(dJMRun.getText());
}
}
}
}
return stringBuilder.toString();
}
Executing that method, we receive our text from the document:
This is my example text.
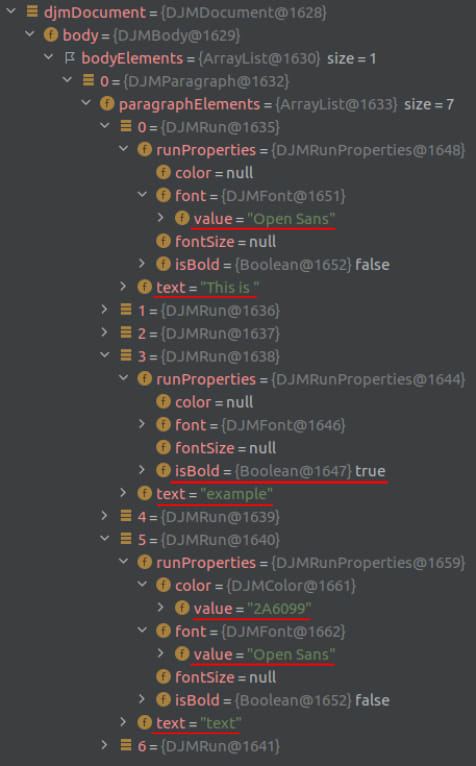
But how can we get the text formattings, like colors, fonts etc.? Using a debugger, we can take a look at our newly created document object during runtime. Unsurprisingly, we can find all the attributes that we set in your docx: Besides the actual text, we can see the font, color and if a particular word is bold.
If we slightly change our method, we can find all bold words in our text, and put them into a list:
public static List<String> getBoldWords(DJMDocument djmDocument) {
List<String> boldWords = new ArrayList<>();
// Different elements can be of type BodyElement
for (BodyElement bodyElement : djmDocument.getBody().getBodyElements()) {
// Check, if current BodyElement is of type DJMParagraph
if (bodyElement instanceof DJMParagraph) {
DJMParagraph dJMParagraph = (DJMParagraph) bodyElement;
// Different elements can be of type ParagraphElement
for (ParagraphElement paragraphElement : dJMParagraph.getParagraphElements()) {
// Check, if current ParagraphElement is of type DJMRun
if (paragraphElement instanceof DJMRun) {
DJMRun dJMRun = (DJMRun) paragraphElement;
boolean isBold = dJMRun.getRunProperties().isBold();
if (isBold) {
String text = dJMRun.getText();
boldWords.add(text);
}
}
}
}
}
return boldWords;
}
After executing that method, we correctly get:
[my, example]
Next Steps…
The final code used in this tutorial can be found here: https://github.com/e-reznik/DocxJavaMapper-example. You can clone that project, play around on your machine and try to extends it with more elements, like images, tables, lists etc.
A more advanced project with more mapped elements can be found here: https://github.com/e-reznik/DocxJavaMapper.
You can also check out one of my other projects, where I create a pdf from a docx, using this approach: https://github.com/e-reznik/Docx2PDF.

Top comments (0)