
Today we're going to build a small image processing pipeline. Our project will be completely serverless and will exemplify how to orchestrate a process over multiple providers, automatically scaling from zero to a million users.
We will use Fauna as a notification hub using its new streaming feature. This allows applications to subscribe to data changes in real time. Currently, it's only possible to subscribe to documents, but subscription to collections and indexes are planned for the future.
Note that streaming in Fauna is still in alpha stage. Bugs and changes in the API should be expected before the final release.
To complete this project, you will need to have an account on these services:
You will also need to have NodeJS installed. Any recent version will be fine. If you don't have it already installed, I recommend downloading the LTS installer from the official website.
The finished project is on this Github repository which you can use to follow along.
In this article:
- Overview
- Setting up Fauna
- Setting up Google Cloud Storage
- Setting up Vercel
- Vercel cloud function
- Front end
- Configuring the Vercel app
- Google Cloud function
Overview
Before we dive in, let's see a quick overview of the process and all the parties involved.
Our pipeline will run on three platforms:
- Fauna will persist data and also be used as a notification hub using streaming.
- Vercel will host the static assets for our front end and upload the images to our storage buckets via a cloud function.
- Google Cloud will be in charge of the resizing duties and hosting the image files.
First, the original image will be uploaded to Google Cloud via a NodeJS cloud function running on Vercel.

Once the file is saved on the private bucket, it will automatically trigger a second cloud function that will resize the image and save it to a public bucket.

We'll be updating Fauna at every step of the way so that our front end is notified of changes and can display the resized image once it's available.
Project structure
This is going to be our folder structure:
/google-cloud-function
/vercel-app
/api
/static
/css
/js
The /vercel-app folder will hold both our front end and a cloud function that will upload the files to the private bucket.
The /google-cloud-function will hold the cloud function that will do the resize and upload the thumbnail to the public bucket.
Setting up Fauna
After creating a user, log into Fauna's dashboard and create a new database. I'll name mine IMAGE_RESIZING, but you can pick whatever name you prefer:

We now need to create a collection to store our documents. To do that, we're going to execute an FQL statement in the dashboard's shell. You can access it from the menu on the left:

Run the following query with this FQL statement:
CreateCollection({
name: "Images"
})
As its name implies, the CreateCollection function will create a new collection called Images where we'll store our image related documents.
Setting up authorization rules
We're now going to take care about authorization so that we can interact with our collection from the outside world.
Server key
First, we need to create a server key so that our cloud function can connect to Fauna. Go to the security section of the dashboard, and create a new key with the Server role:

The Server role comes configured by default when creating a new database. It is omnipotent so be very careful where you use it.
After saving the key you will see its secret. Store it somewhere safe as Fauna will never show it to you again and you will need it later on.

Front end key
We're now going to create a key for our front end application. We can't use the Server role because its secret would be exposed publicly on the web. Instead, we're going to create a new role with restricted permissions.
In the security tab, open to the roles section and create a new role called FrontEnd. Add the Images collection we created previously, and enable the read permission as shown below:

With these settings, our role will only be able to read documents from the Images collection but everything else will be forbidden.
Save the FrontEnd role and create a new key with it. Again, store the secret somewhere as you will need it later on.
For more information on authentication and authorization with Fauna check this introductory article.
Setting up Google Cloud Storage
We're now going to focus on Google Cloud Storage. Open the Google Cloud Console and create a new project with any name you prefer.
Then open the Storage section via the left side menu:

Once there, we need to create two storage buckets:
- fauna-resize-images to store the uploaded images
- fauna-resize-thumbnails will be publicly available and will store the resized images
Bucket names are unique across all Google Cloud, so you will need to use your own names.
To create new buckets just click on the Create bucket button of the Storage section. Simply write the name of the bucket and leave all options as provided by default.
Making the bucket public
We now need to make our second bucket public so that our thumbnails can be accessed from a web browser. There are many ways to accomplish this. For simplicity's sake we're just going to modify the permissions of the bucket itself.
Go back to the Storage section, and open the bucket you will use to store your thumbnails (the one I named fauna-resize-thumbnails). Once there, open the Permissions tab and click on the Add button at the bottom:

In the form to create new permissions write allUsers for its members. Then select the Storage Object Viewer role from the Cloud Storage category:

Files in Google Cloud Storage are referred to as objects. In plain English, we're telling Google that anyone (allUsers) can view the files of this bucket.
After saving, Google Cloud will show you multiple warnings reminding you this bucket is now public. Public buckets can incur in massive bandwidth costs, but you can safely ignore these warnings for the purpose of this demo.
Creating a service account
We now need to create a service account which will allow us to upload files to our buckets from outside of our Google Cloud project.
From the sidebar menu, go to the IAM & Admin category and open the Service Accounts section:

Once you're there, create a new service account with any name you wish and leave all the options as default.
I'm using Vercel Service Account as the name of my service account:

We now need to create a key for our service account. On the list of accounts, click on the three dots button and select Create key:

Finally, create a JSON key:

This will download a .json file that we will need later on. Keep it safely and do not commit it to your Git repository.
We're done for now with Google Cloud.
Setting up Vercel
Once you've created your Vercel account you will need to install the Vercel CLI.
After that's done, log in from the CLI using the Login command and follow the instructions:
vercel login
We're now ready to start writing some code!
The Vercel cloud function
Let's start by focusing on the cloud function that will upload the files to the private storage bucket.
First, create the vercel-app folder inside your project folder and access it from your terminal.
Then, initialize NPM with:
npm init -y
This will create a vercel-app/package.json file and allow us to install the dependencies for our cloud function:
npm i @google-cloud/storage faunadb
Let's now create the vercel-app/api folder. By default, any JavaScript file inside the api folder of a Vercel app will be executed as a serverless cloud function.
With this in mind, let's create the file vercel-app/api/upload.js that will respond to requests to the /api/upload endpoint:
import faunadb from 'faunadb';
import {Storage} from '@google-cloud/storage';
const storage = new Storage({
projectId: process.env.GOOGLE_PROJECT_ID,
credentials: {
client_email: process.env.GOOGLE_SERVICE_ACCOUNT_EMAIL,
private_key: JSON.parse(process.env.GOOGLE_SERVICE_ACCOUNT_KEY)
}
});
const bucket = storage.bucket(process.env.PRIVATE_BUCKET_NAME);
const faunaClient = new faunadb.Client({secret: process.env.FAUNA_SECRET});
const {Create, Collection, Update, Ref} = faunadb.query;
export default async function (request, response) {
const document = await faunaClient.query(
Create(
Collection('Images'),
{
data: {
status: 'UPLOADING'
}
}
)
);
const documentId = document.ref.id;
await bucket.file(document.ref.id + '.jpg').save(request.body);
await faunaClient.query(
Update(
Ref(Collection('Images'), documentId),
{
data: {
status: 'WAITING_FOR_THUMBNAIL'
}
}
)
);
response.send({documentId});
};
As you can see, there is no need to install any framework as Vercel does all the heavy lifting. We only need to interact with the request and response objects.
For simplicity's sake we're not handling any errors here. We're just just going to assume we will only receive POST requests with images.
Let's now examine the code of our cloud function.
First, we are initializing the Google Cloud Storage and Fauna clients:
const storage = new Storage({
projectId: process.env.GOOGLE_PROJECT_ID,
credentials: {
client_email: process.env.GOOGLE_SERVICE_ACCOUNT_EMAIL,
private_key: JSON.parse(process.env.GOOGLE_SERVICE_ACCOUNT_KEY)
}
});
const bucket = storage.bucket(process.env.PRIVATE_BUCKET_NAME);
const faunaClient = new faunadb.Client({secret: process.env.FAUNA_SECRET});
const {Create, Collection, Update, Ref} = faunadb.query;
We're using some environment variables (process.env) that we will be configuring a bit later.
Take note that this code is executed outside the function itself and will remain in memory for as long as the cloud function is "awake" or "hot".
Once we receive a request to the function, it will create a Fauna document into our Images collection:
const document = await faunaClient.query(
Create(
Collection('Images'),
{
data: {
status: 'UPLOADING'
}
}
)
);
const documentId = document.ref.id;
We're adding a status property to the document that we will be updating at each step of the process. In a real world scenario you'd also probably need some sort of log. Another option could be simply using Fauna's temporal features to check when the status changes have occurred.
Once the document is created, we're ready to start uploading the image to our storage bucket by simply passing the body of the request (of type Buffer) to the Storage client:
await bucket.file(document.ref.id + '.jpg').save(request.body);
The name of the file on the bucket will correspond to the id of the Fauna document. It will look something like this:
288917002031989250.jpg
Once the upload has finished, the image will be safely stored in our private bucket, waiting for the next step of the process.
We can now update the status in the document to WAITING_FOR_THUMBNAIL, and finally return the id of the document to our front end (or whoever did the POST request):
await faunaClient.query(
Update(
Ref(Collection('Images'), documentId),
{
data: {
status: 'WAITING_FOR_THUMBNAIL'
}
}
)
);
response.send({documentId});
Front end

For our front end we will be using Preact, a fast and small React-like library. We'll also be using Htm by the same author so that we can use JSX without having to configure a build setup.
Be sure to use the latest version of your browser to run this demo, as we will use a couple of modern JavaScript features.
We will begin by creating the vercel-app/index.html file. This will be the entry point of our front end:
<!DOCTYPE html>
<html>
<head>
<title></title>
<link rel="stylesheet" type="text/css" href="static/css/styles.css">
<script src="https://cdnjs.cloudflare.com/ajax/libs/js-signals/1.0.0/js-signals.min.js" crossorigin="anonymous"></script>
<script src="https://cdn.jsdelivr.net/npm/faunadb@latest/dist/faunadb-min.js"></script>
<script src="static/js/FaunaStream.js"></script>
<script type="module" src="static/js/main.js"></script>
</head>
<body>
</body>
</html>
We're importing the Fauna JS driver from a CDN and a couple of other things:
- js-signals is a small implementation of signals in JavaScript
- styles.css will hold our global CSS styles
- main.js will be our main JavaScript file
- FaunaStream.js will store a small class for working with Fauna document streams
I won't be going over the CSS in this article, but you can check the global styles I used in the repository.
FaunaStream class
Our first JavaScript file will be a class to encapsulate the subscription to a Fauna document.
Inside your project folder, create the a new file at vercel-app/static/js/FaunaStream.js with this content:
class FaunaStream {
constructor (client, documentRef) {
this.client = client;
this.documentRef = documentRef;
this.onUpdate = new signals.Signal();
}
initStream () {
this.stream = this.client.stream.document(this.documentRef);
this.stream.on('snapshot', (data, event) => {
this.onUpdate.dispatch(data);
});
this.stream.on('version', (data, event) => {
this.onUpdate.dispatch(data.document);
});
this.stream.on('error', (data, event) => {
this.stream.close();
setTimeout(() => {
this.initStream();
}, 250);
});
this.stream.start();
}
destroy () {
this.stream.close();
this.onUpdate.removeAll();
}
}
The constructor takes an instance of the Fauna client and a reference of the document we want to subscribe to.
Once the stream is created with client.stream.document() we can add handlers to a number of events:
- The snapshot event will return the full document at the start of the stream.
- The version event will return the updated document whenever there is a change.
- The error event will be triggered if anything goes wrong. If an error happens, it's necessary to close the stream and create a new one after waiting a bit.
Although we're only subscribing to three events, here's an article with a complete list of events and more information on using Fauna streams.
The onUpdate signal will dispatch any updates from the stream to the rest of our application.
Main JavaScript code
Let's now focus on the main code of our small front end application. Create the vercel-app/static/js/main.js file with this content:
import {h, Component, render, createRef} from 'https://unpkg.com/preact?module';
import htm from 'https://unpkg.com/htm?module';
const html = htm.bind(h);
const faunadb = window.faunadb;
const {Ref, Collection} = faunadb.query;
const faunaClient = new faunadb.Client({
secret: 'fnAEAljlZZACBk1sm8pK_M0jYYELASNStPDCfQyc',
});
const AppStates = {
WAITING_FOR_FILE: 'WAITING_FOR_FILE',
UPLOADING_FILE: 'UPLOADING_FILE',
WAITING_FOR_THUMBNAIL: 'WAITING_FOR_THUMBNAIL',
DISPLAYING_THUMBNAIL: 'THUMBNAIL_READY'
}
class App extends Component {
constructor() {
super();
this.state = {
appState: AppStates.WAITING_FOR_FILE,
thumbnailUrl: null
};
}
async uploadFile (file) {
this.setState({appState: AppStates.UPLOADING_FILE});
const response = await fetch('/api/upload', {
method: 'POST',
headers: {
'content-type': 'application/octet-stream'
},
body: file
});
const responseBody = await response.json();
this.initStream(responseBody.documentId);
}
initStream (documentId) {
if (this.faunaStream) this.faunaStream.destroy();
this.faunaStream = new FaunaStream(faunaClient, Ref(Collection('Images'), documentId));
this.faunaStream.initStream();
this.faunaStream.onUpdate.add((document) => {
const status = document.data.status;
const newState = {appState: AppStates[status]};
if (document.data.thumbnailUrl) {
newState.thumbnailUrl = document.data.thumbnailUrl;
}
this.setState(newState);
});
}
render () {
switch (this.state.appState) {
case AppStates.WAITING_FOR_FILE:
return html`<${DropFile} onFileSelected=${this.uploadFile.bind(this)}/>`;
break;
case AppStates.UPLOADING_FILE:
return html`<div class="spinner"></div><h2>Uploading file!</h2>`;
break;
case AppStates.WAITING_FOR_THUMBNAIL:
return html`<div class="spinner"></div><h2>Waiting for thumbnail!</h2>`
break;
case AppStates.THUMBNAIL_READY:
return html`<img src="${this.state.thumbnailUrl}" />`;
break;
}
}
}
class DropFile extends Component {
onDropFile (event) {
event.preventDefault();
const items = event.dataTransfer.items;
if (items.length > 1) {
alert('Only 1 file can dropped!');
return;
}
this.props.onFileSelected(items[0].getAsFile());
}
render () {
return html`
<div class="DropFile" onDrop=${this.onDropFile.bind(this)} onDragOver=${e => e.preventDefault()}>
<svg xmlns="http://www.w3.org/2000/svg" width="100" height="100" viewBox="0 0 16 16">
<path d="M6.002 5.5a1.5 1.5 0 1 1-3 0 1.5 1.5 0 0 1 3 0z"/>
<path d="M2.002 1a2 2 0 0 0-2 2v10a2 2 0 0 0 2 2h12a2 2 0 0 0 2-2V3a2 2 0 0 0-2-2h-12zm12 1a1 1 0 0 1 1 1v6.5l-3.777-1.947a.5.5 0 0 0-.577.093l-3.71 3.71-2.66-1.772a.5.5 0 0 0-.63.062L1.002 12V3a1 1 0 0 1 1-1h12z"/>
</svg>
Drop a JPG file in here!
</div>
`;
}
}
render(html`<${App} name="World" />`, document.body);
Most of this code should be self-explanatory, but let's go over the main points.
First, we're importing Preact and Htm directly from Unpkg as modules just as if we were using them with NPM:
import {h, Component, render, createRef} from 'https://unpkg.com/preact?module';
import htm from 'https://unpkg.com/htm?module';
This should be fine for our demo as it's supported on all modern browsers.
Then, we're instantiating Fauna's client using the secret we obtained earlier with our FrontEnd role:
const faunadb = window.faunadb;
const {Ref, Collection} = faunadb.query;
const faunaClient = new faunadb.Client({
secret: 'fnAEAljlZZACBk1sm8pK_M0jYyELASNstPDCfQyc',
});
We have to be very careful with using secrets publicly on the internet. Our FrontEnd role only allows reading documents from the Images collection, but exposing a secret from a Server key would give total control of the database to anyone.
Whenever a user selects a file, it will be submitted to the Vercel cloud function available at the /api/upload REST endpoint:
async uploadFile (file) {
this.setState({appState: AppStates.UPLOADING_FILE});
const response = await fetch('/api/upload', {
method: 'POST',
headers: {
'content-type': 'application/octet-stream'
},
body: file
});
const responseBody = await response.json();
this.initStream(responseBody.documentId);
}
We're adding a content-type HTTP header with a value of application/octet-stream. This will tell Vercel that the body of the request has to be parsed into a Buffer before handling it to our cloud function.
Configuring the Vercel app
All the code for our Vercel app is ready, but we need to configure it first to be able to run it locally or upload it to Vercel's infrastructure.
Go to the vercel-app folder with your terminal and execute this command:
vercel
You can accept all the default options and use any project name you prefer.
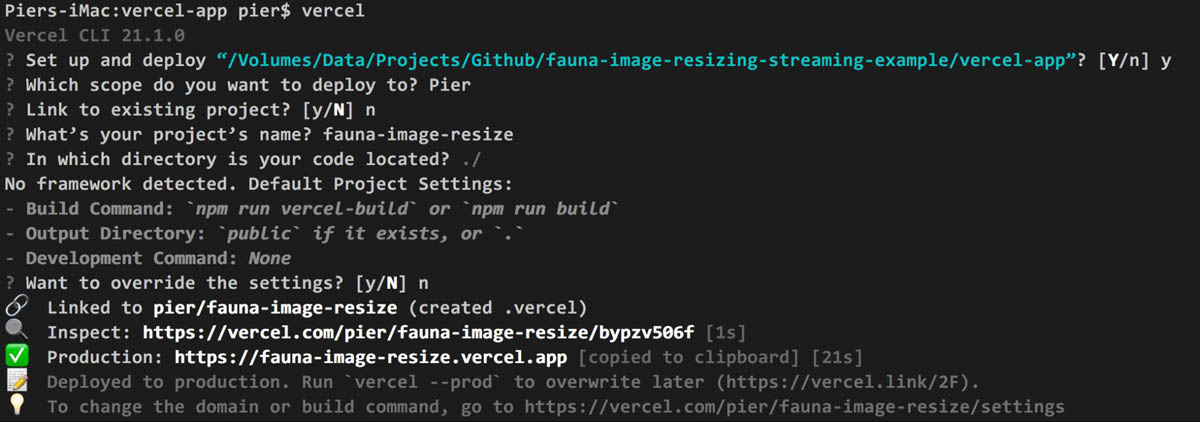
Our project is now uploaded to Vercel and available at a subdomain with your project's name such as:
https://fauna-image-resize.vercel.app
The Vercel CLI should have created two things:
- The vercel-app/.vercel folder with all the metadata and cache the CLI needs to run
- A .gitignore file that prevents the .vercel folder from being committed to Git.
If you intend on pushing this project to Git you should add the node_modules folder to that .gitignore file.
Configuring environment variables
If you try to run it now it will break though. Our cloud function needs some environment variables to be able to execute. We're going to configure those using the CLI, but you could use Vercel's dashboard too if you prefer a visual tool.
Storage Bucket
First, let's add the name of our private bucket.
Run this command:
vercel env add
Select these options:
- Type: Plaintext
- Name: PRIVATE_BUCKET_NAME
- Value: write the name of your private bucket. I used fauna-resize-images
- Environments: select all three environments by pressing the space key.
Fauna secret
For the Fauna secret, repeat the same process using the secret you got when creating the Fauna key for the Server role. The environment variable should be named FAUNA_SECRET .
Google Cloud service account credentials
Now, open the .json you downloaded from Google Cloud with the service account key.
It should look similar to this:
{
"type": "service_account",
"project_id": "fauna-image-resizing",
"private_key_id": "67f17be157f1b0300...",
"private_key": "-----BEGIN PRIVATE KEY-----\nMIIEvgIBADA...",
"client_email": "name-service-account@fauna-image-resizing.iam.gserviceaccount.com",
"client_id": "...",
"auth_uri": "https://accounts.google.com/o/oauth2/auth",
"token_uri": "https://oauth2.googleapis.com/token",
"auth_provider_x509_cert_url": "https://www.googleapis.com/oauth2/v1/certs",
"client_x509_cert_url": "https://www.googleapis.com/robot/v1/..."
}
Create an environment variable called GOOGLE_PROJECT_ID with the project-id value of the JSON. Use the string value as-is, don't include the quotes (eg: fauna-image-resizing).
Now, create a variable called GOOGLE_SERVICE_ACCOUNT_EMAIL with the email of your service account (the client_email value in the JSON). Again, don't include the quotes.
Our last variable will be GOOGLE_SERVICE_ACCOUNT_KEY. You need to use the private_key value of the JSON.
For this value you now need to include the quotes. For example:
"-----BEGIN PRIVATE KEY-----\nMIIE......7vK\n-----END PRIVATE KEY-----\n"
The problem is that these types of keys use the new line character \n and it needs to be properly parsed. By including the quotes we will be able to use JSON.parse() in our cloud function to pass the proper characters to the Storage client:
JSON.parse(process.env.GOOGLE_SERVICE_ACCOUNT_KEY)
At the end of this process, use the vercel env ls command to check you have properly created these five environment variables:

Running the Vercel app
You should already be able to access your Vercel app on your production domain (eg: fauna-image-resize.vercel.app).
Alternatively, you can also run the dev command to run the app locally:
vercel dev
In any case, if you now select an image in your front end it should be uploaded to your private bucket. The status in the Fauna document will remain as WAITING_FOR_THUMBNAIL though because we haven't implemented the resizing part yet.

Google Cloud function
The final piece of our project is a cloud function that will take care of the resizing duties. This function will be triggered automatically when an image is uploaded to the private bucket, and the resized image will be uploaded to our public bucket.
Open the Google Cloud console and go to the Functions section from the left side menu in the Compute category:

Once you're there, click the button to create a new function:

The console might need to to do a bit of work before the button is available, but this shouldn't take long.
You can use any name you prefer for the function. I will name mine create_thumbnail.
Trigger configuration
On the trigger configuration, be sure to select your private bucket with the Finalize/Create event and click Save:

Environment variables
Now, open the Variables, Networking, and Advanced Settings, go to the Environment Variables tab:

Add the following Runtime environment variables:
- FAUNA_SECRET with the secret of your Server key
- BUCKET_IMAGES_NAME with the name of your private bucket. In my case it's fauna-resize-images.
- BUCKET_THUMBNAILS_NAME **with the name of your public bucket. In my case it's **fauna-resize-thumbnails.
Then click the Next button at the bottom.
Adding the code of the function
You should now be at this code editor for our function:

For the Runtime you can leave the default value of NodeJS 10.
On the Entry point field use createThumbnail as this will be the name of our JavaScript function.
On the the package.json add the faunadb and gm dependencies like so:
{
"name": "sample-cloud-storage",
"version": "0.0.1",
"dependencies": {
"@google-cloud/storage": "^1.6.0",
"gm": "^1.23.1",
"faunadb": "^4.0.0"
}
}
The gm package makes using ImageMagick much easier in Node. We'll use it to resize our images as it comes installed by default on the virtual machine running our cloud function.
Now, open the index,js file, delete everything, and paste this:
const gm = require('gm').subClass({imageMagick: true});
const path = require('path');
const os = require('os');
const fs = require('fs');
const faunadb = require('faunadb');
// Fauna
const faunaClient = new faunadb.Client({secret: process.env.FAUNA_SECRET});
const {Update, Ref, Collection} = faunadb.query;
// Storage
const storage = require('@google-cloud/storage')();
const bucketImages = storage.bucket(process.env.BUCKET_IMAGES_NAME);
const bucketThumbnails = storage.bucket(process.env.BUCKET_THUMBNAILS_NAME);
exports.createThumbnail = async (event, context) => {
const filename = event.name;
// Download image from bucket to VM
const originalFilePath = path.join(os.tmpdir(), filename);
await bucketImages.file(filename).download({
destination: originalFilePath
});
// Resize image with Image Magick
const thumbFilePath = path.join(os.tmpdir(), 'thumb.jpg');
await new Promise((resolve, reject) => {
gm(originalFilePath).resize(400, 300).write(thumbFilePath, (error, stdout) => {
if (error) {
reject(error);
} else {
resolve(stdout);
}
});
});
// Upload thumbnail to bucket
await bucketThumbnails.upload(thumbFilePath, {
destination: filename
});
// Update the Fauna document
const documentId = filename.split('.')[0];
const thumbnailUrl = `https://storage.googleapis.com/${process.env.BUCKET_THUMBNAILS_NAME}/${filename}`;
await faunaClient.query(
Update(
Ref(Collection('Images'), documentId),
{
data: {
status: 'THUMBNAIL_READY',
thumbnailUrl
}
}
)
);
};
Finally, click the DEPLOY button. The deployment of the function will take a minute or two.
It should be noted that we don't need to use any credential to instantiate the Storage client. This function can now automatically interact with all the resources of our Google Cloud project:
const storage = require('@google-cloud/storage')();
The rest of the code should be self explanatory as it is very similar to our Vercel cloud function.
Once the image has been resized and uploaded to our public bucket, the status of the Fauna document will change to THUMBNAIL_READY and the URL of the thumbnail will be added. Because our front end is subscribe to the document, it will now display the thumbnail.
It would be a good idea to save the code of the function and package.json to your project folder for future reference. I've done that in the repository of the project.
Also, if you install the gcloud CLI you can actually deploy updates to the cloud function from your machine.
Conclusion
If you've made it this far, good job!
If you want to keep on learning about Fauna, check these other articles I wrote:
Getting started with FQL
- Part 1: Fundamental Fauna concepts
- Part 2: Deep dive into indexes
- Part 3: Modeling data with Fauna
- Part 4: Running custom functions in Fauna
- Part 5: Authentication and authorization in Fauna
Core FQL concepts
- Part 1: Working with dates and times
- Part 2: Temporality in Fauna
- Part 3: Data aggregation
- Part 4: Range queries and advanced filtering
- Part 5: Joins
Thanks for reading and, as always, if you have any questions don't hesitate to hit me up on Twitter: @pierb

Top comments (0)