
Databases are one of the most important concepts in software development and maintenance, they unify the management of data so that everyone that access it can query and easily make sure that the informations are correct from a single reliable source of data
Let's imagine an excel-like paper with all the data about a business customers:
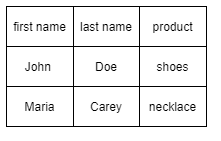
Without a database every different user/department/manager of a business should have to manually update a copy of the paper and this would leave a lot of problems in case of any error because everyone has a copy of the same piece of paper, but with databases we not only end this problem but we can even improve the overall organization and use of our data.
A database will be used by many people, both tech-savvy and not, so we'll need ways to easily input and output data from it.
Some of the data, such as personal informations, salaries and passwords, will need restricted access. Security and permission are one of the most important things to design when creating this kind of software.
In a database a piece of data, a row, is called a record and each item, a column, is called a field

Special fields
Every record has its own ID which is unique to him. This field doesn't duplicate and is the main way to indicate a certain record, it is unique
Another special field is the remarks one. It serves as a place to store more information about the record. Remarks can accept a NULL value. It indicates that a field is empty. The ID doesn't accept a NULL value cause identifies data

The relational data model
A relational data model is based on a two-dimensional table, it is the examples that we used till now. Another example is excel, which can be used as a database (although is inefficient). The most important and useful data model is this one and a database based on it is called a relational database
In a relational database some fields are more important than others. The ID field serves as the main way to identify and is thus called primary key
The main advantages of the relational data model are the mathematical operation that can be performed on it
relational database operations
those operations are either set or relational. Set operations use rows to produce a new set of rows, they are:
- Union
- Difference
- Intersection
- Cartesian product
Relational operations:
- Projection
- Selection
- Join
- Division
Union
The union operation extracts all the different rows from multiple tables and combines them into a new one.
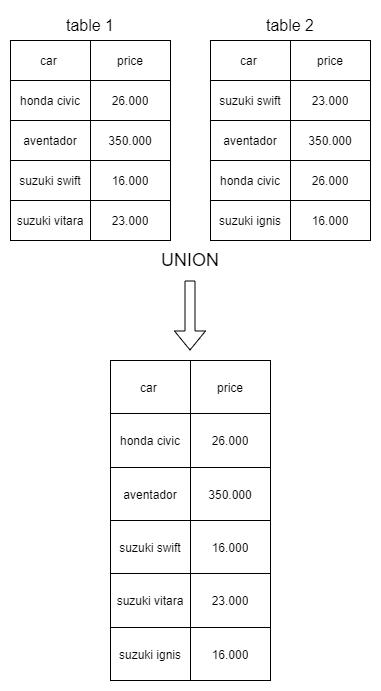
you can think of it as an addition between tables

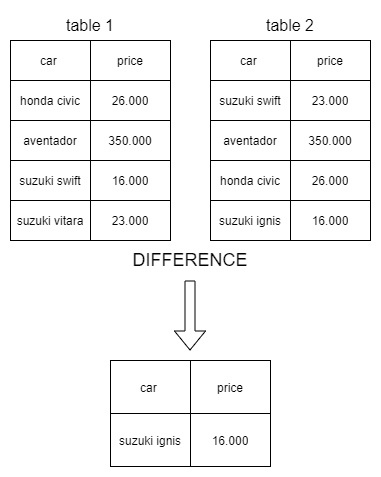
difference
The difference operation extract rows from just one table that are not included in a second one

intersection
The intersection operation extract all the products that are not included in the selected tables


cartesian product
The cartesian product combines all rows in various tables. The difference here is that the tables have different fields

Projection
The projection operation extract one or more fields from a table

Selection
The selection operation extracts one or more records from a table

Join
The join operation, obviously, joins two tables, but it's more powerful than the union.
Earlier we talked about the primary key as the unique way to identify a certain record, this way we can have multiple tables that refers to the same record but with more appropriate data. A primary key in a different table is called a foreign key

with a primary and a foreign key we can split our record into multiple tables and organize more efficiently our data eliminating useless information for that context.
The result of a join operation will be

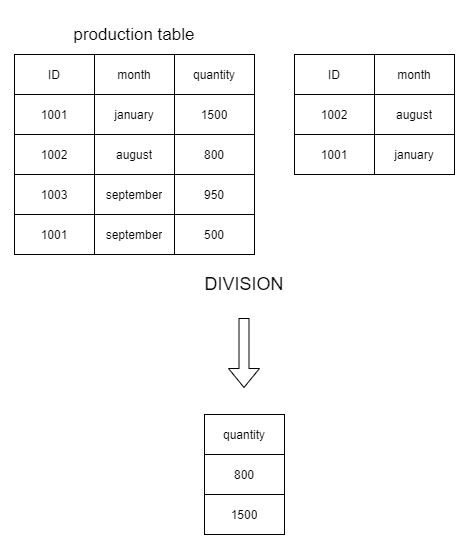
Division
The division operation returns the fields that don't exists in the divided table, is used to discover a specific bit of information from data
Final thoughts
This is all you need to begin your database, everything else will come with experience and with a lot of research





Top comments (0)