One of the principles of the twelve-factor app methodology is strict separation between code and config, where config means everything that is likely to vary between deployments, and code is everything that doesn’t. Historically, was not a good fit for .NET Framework applications, which relied on tools such as web.config transformation and Slow Cheetah to apply build-time transformations to application configuration files. These transformations are based on environment-specific config files stored alongside the application code in the source repo. In the past, this led some commentators to conclude that certain aspects of 12-factor were just not applicable to .NET applications.1 The world has moved on since then, as has the .NET framework, and separation of code and config is much easier to accomplish. This article will describe one technique for managing version-controlled configuration data alongside - but separate from - our application code using Azure DevOps variable templates.
The example
The example project I am using is the sample ASP.NET Core MVC application for Cosmos DB, which is described in a tutorial on docs.microsoft.com as well as being available to download from GitHub. In brief, this consists of a simple website that provides CRUD2 operations for a “to-do list” stored in Azure Cosmos DB. I chose this particular example as it requires a handful of configuration items, of which one - the Cosmos DB API key - is a secret. Most real life projects, at least the ones I’ve worked on, require a much larger number of variables to be set.
By default, ASP.NET Core web apps are provided with a default configuration builder that reads configuration from a number of sources in a predetermined order. The important thing to know here is that environment variables take precedence over values in appsettings.json. This means that appsettings.json and its cousins appsettings.dev.json, appsettings.test.json and so on can be relegated to providing configuration values on the developer’s desktop, with all other environments being configured via environment variables. As it happens, there is an open-source nuget package DotNetEnv which makes it easier to dispense with appsettings.json altogether, but I won’t discuss this further here since the example project doesn’t use it. The disadvantage of appsettings.json is of course that it’s too easy to end up doing this kind of thing.
The config repo
The project contains two repos; sample-app-code and sample-app-config.
sample-app-code is just a fork of the public repo from GitHub, with the addition of an azure-pipelines.yml file to build and release the application. sample-app-config contains one .yml file per environment, which I’ve named after the environment.
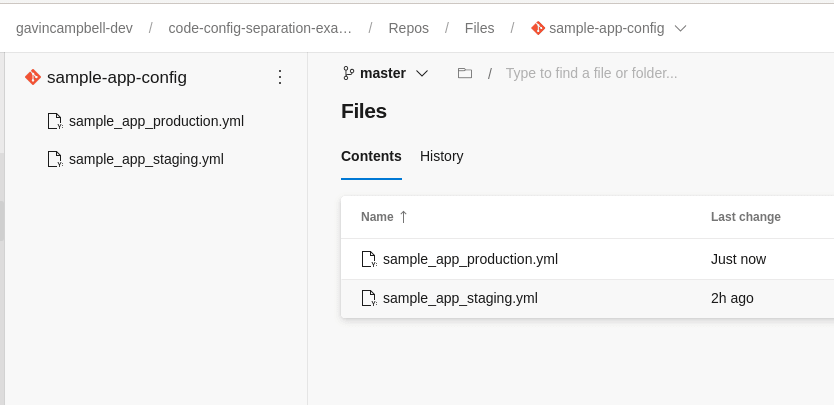
One template file per environment
These .yml files are known as pipeline templates. When we refer to a pipeline template in our pipeline, the entire contents of the template file is inserted at that point. Pipeline templates can be used to define and re-use a number of pipline objects, such as stages, jobs, steps, and, in our case, variables.
In general you can’t mix different types of objects, such as variables and steps for example, in a single template - they would end up being inserted at the “wrong” place in the pipeline.
Each template file contains a variable for everything that is likely to change between deployments, or in other words the configuration. These variables will be available to our pipeline, as well as being available as environment variables to our scripts3.
# This is a comment. Take that, appsettings.json!
variables:
#deployment config
serviceConnectionName: myNonProdServiceConnection
resourceGroupName: rg-todo-staging
resourceGroupLocation: uksouth
#Cosmos DB Config
cosmosAccountName: cosmos-ac-todo-staging
keyVaultName: kv-todo-staging-fdkjiwh
#Web app config
appServicePlanName: asp-todo-staging
servicePlanSku: S1
# need single quotes around double quotes to pass the pipe and the double quotes!
runtimeVersion: '"DOTNETCORE|3.1"'
webAppName: todo-staging-vdorpsbzaoiku
If you do this in “real life”, it’s up to you whether you create one config repo per code repo, or share a single config repo between a number of code repos. In the latter case you’d need to come up with some sort of folder structure and/or naming convention, e.g.
.
├── app1
│ ├── production.yml
│ └── staging.yml
└── app2
├── otherenv.yml
├── production.yml
└── staging.yml
or
.
├── app1-production.yml
├── app1-staging.yml
├── app2-otherenv.yml
├── app2-production.yml
└── app2-staging.yml
The Pipeline
The pipeline file is pretty short, so I have included it in its entirety here. During the build stage, we just do dotnet publish and publish the resulting package as a pipeline artifact for later consumption. The deployment stages have been encapsulated into a job template that takes two parameters. The first is the name of the environment we are deploying to, and the second is the name of a variable group containing some additional secret variables - since we don’t want to store secret variables in our config repo.
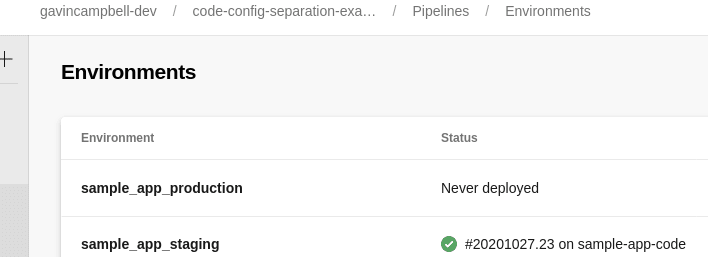
Enviroments in Azure Pipelines
I created an approval on the production environment using the UI.
Observant readers will have noticed that the value we pass in the stageName parameter matches the name of the yml file in the config repo as well as the name of the enviroment as defined in Azure Pipelines; this matters as we are going to use this parameter to figure out which variable template to use as well as which enviroment to deploy to. Of course, if you wanted these names to be different, you could accomodate this with some additional mapping logic. Unlike the variable templates, the job template pipelineTemplates/doTheDevOps.yml is stored in the same repo as the code, since it doesn’t vary between environments.
The effect of this is that every stage in our pipeline is deployed identically. We use the same template for deployment, and we tell the template where to retrieve its configuration. This should greatly increase our confidence in deploying to production, as since we use the same code everywhere we have lots of chances to “practice” before we do the production deployment.
trigger:
- master
pool:
vmImage: 'ubuntu-latest'
resources:
repositories:
- repository: config
type: git
name: sample-app-config
stages:
- stage: buildAndPublish
displayName: Build project and publish artifact
jobs:
- job: buildAndPublish
displayName: Build and Publish
steps:
- task: DotNetCoreCLI@2
displayName: dotnet publish
inputs:
command: 'publish'
publishWebProjects: true
arguments: '-c Release -o $(Build.ArtifactStagingDirectory)/todo'
modifyOutputPath: false
- task: PublishPipelineArtifact@1
displayName: Publish todo.zip as Pipeline Artifact
inputs:
targetPath: '$(Build.ArtifactStagingDirectory)/todo/todo.zip'
artifact: 'todozip'
publishLocation: 'pipeline'
- stage: deployStaging
displayName: Deploy Staging Environment
jobs:
- template: pipelineTemplates/doTheDevOps.yml
parameters:
stageName : sample_app_staging
variableGroupForSecrets : SecretVarsForStaging
- stage: deployProduction
displayName: Deploy Production Environment
jobs:
- template: pipelineTemplates/doTheDevOps.yml
parameters:
stageName : sample_app_production
variableGroupForSecrets : SecretVarsForProduction
The deployment job
As the name suggests, this file is where the action takes place. In summary, we create our supporting infrastructure4 - the CosmosDB account, a key vault to hold the CosmosDB Key, the App Service plan, and then deploy our web app with appropriate configuration.
In order to demonstrate the use of variable groups to hold secret variables for YAML pipelines, I’m also adding an additional sensitive setting that is never used by the app. Other than for holding secrets that need to be masked in the pipeline log output, I think using variable templates removes the need for variable groups. Once again the template file is short enough to reproduce in full here:
parameters:
- name: stageName
type: string
- name: variableGroupForSecrets
type: string
jobs:
- deployment: deploy${{ parameters.stageName }}
displayName: Deploy ${{ parameters.stageName }} Environment
environment: ${{ parameters.stageName }}
variables:
- template: ${{ parameters.stageName }}.yml@config
- group: ${{parameters.variableGroupForSecrets}}
strategy:
runOnce:
deploy:
steps:
- task: AzureCLI@2
inputs:
azureSubscription: ${{ variables.serviceConnectionName }}
scriptType: 'bash'
scriptLocation: 'inlineScript'
inlineScript: |
az group create --name $(resourceGroupName) --location $(resourceGroupLocation)
az appservice plan create --name $(appServicePlanName) --resource-group $(resourceGroupName) \
--sku $(servicePlanSku) --is-linux
az webapp create --resource-group $(resourceGroupName) --plan $(appServicePlanName) --name $(webAppName) \
--runtime $(runtimeVersion)
az webapp identity assign --name $(webAppName) --resource-group $(resourceGroupName)
# Grant the web app identity permission to read secrets from the vault
az keyvault create --resource-group $(resourceGroupName) --location $(resourceGroupLocation) --name $(keyVaultName)
principal=$(az webapp identity show --resource-group $(resourceGroupName) --name $(webAppName) | jq -r .principalId)
az keyvault set-policy --name $(keyVaultName) --secret-permissions get --object-id $principal
# Add our secret var to the key vault
az keyvault secret set --vault-name $(keyVaultName) --name PointlessSecret --value $(PointlessSecret)
# Create cosmosdb account and retrieve uri and key for app settings
az cosmosdb create --name $(cosmosAccountName) --resource-group $(resourceGroupName)
cosmosUri=$(az cosmosdb show --name $(cosmosAccountName) --resource-group $(resourceGroupName) | jq -r .documentEndpoint)
cosmosAccountKey=$(az cosmosdb keys list --name $(cosmosAccountName) --resource-group $(resourceGroupName) | jq -r .primaryMasterKey)
# Add cosmos key to key vault
az keyvault secret set --vault-name $(keyVaultName) --name cosmosAccountKey --value $cosmosAccountKey
# Get Secret Uris to add to app settings
cosmosKeyKvUri=$(az keyvault secret list-versions --name cosmosAccountKey --vault-name $(keyVaultName) --maxresults 1 | jq -r .[0].id)
pointlessSecretUri=$(az keyvault secret list-versions --name PointlessSecret --vault-name $(keyVaultName) --maxresults 1 | jq -r .[0].id)
# Set up app settings
az webapp config appsettings set --resource-group $(resourceGroupName) --name $(webAppName) \
--settings Logging __LogLevel__ Default=Warning \
AllowedHosts="*" \
CosmosDb__Account=$cosmosUri \
CosmosDb__Key="@Microsoft.KeyVault(SecretUri=$cosmosKeyKvUri)" \
CosmosDb__DatabaseName=Tasks \
CosmosDb__ContainerName=Item \
PointlessSecret="@Microsoft.KeyVault(SecretUri=$pointlessSecretUri)"
# set web app to mount zip file read-only https://docs.microsoft.com/en-us/azure/app-service/deploy-run-package
az webapp config appsettings set --resource-group $(resourceGroupName) --name $(webAppName) --settings WEBSITE_RUN_FROM_PACKAGE="1"
az webapp deployment source config-zip --resource-group $(resourceGroupName) --name $(webAppName) --src $(Pipeline.Workspace)/todozip/todo.zip
There isn’t really much going on here, we create an app service plan and web app, along with a key vault to hold the Cosmos Key, as well as the secret we are reading from the variable group. The web app is created with a managed identity, which we retrieve in order to grant access to the key vault. Next, we create the Cosmos DB Account, and store the account key in the key vault. Finally, we set up all of the app settings, including the key vault references, and deploy the web app. Since this application doesn’t write anything to local paths, we are taking advantage of the facility to mount our zipped deployment package directly as a read-only filesystem.
When we run the pipeline, we build the app and deploy it to each of our stages in succession:
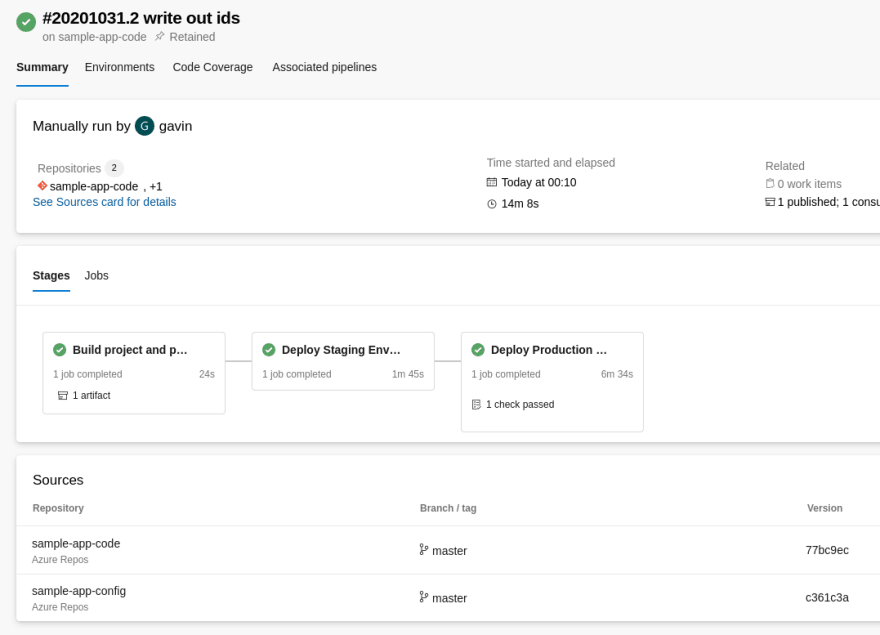
The completed pipeline run
If we inspect the logs, we can see that the steps from our template have been included just as if they were defined in the main azure-pipelines.yml file:
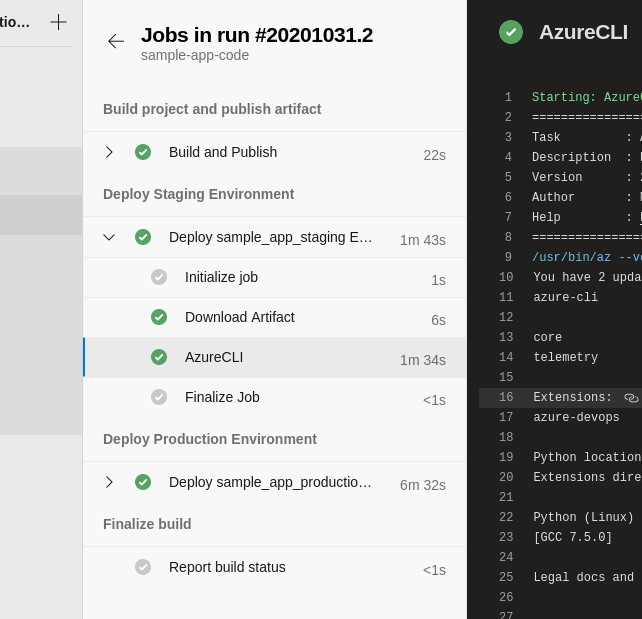
The pipeline logs
The payoff
Whilst this approach requires a bit of work to set up, it delivers a number of benefits.
- There is no need to have any logic in our source repo based on what environment we are deploying into.
- Changes to our application config don’t mean we have to rebuild our application code, we can redploy the same version with the new config.
- Since the config repo can be versioned, it is possible for different code repos to pin to different versions of the config.
- Config repos often contain cost-sensitive items, such as the number or size of VMs being deployed to a particular environment. Having this stored in Azure Repos enables us to use the usual source-code management and audit techniques to control changes to these variables
- We can add a new environment to our release pipeline just by creating a new config file in the config repo and a stanza of the following form in the release pipeline.
- stage: deployWhatever
displayName: Deploy Whatever Environment
jobs:
- template: pipelineTemplates/doTheDevOps.yml
parameters:
stageName : sample_app_whatever
variableGroupForSecrets : SecretVarsForWhatever
<!-- raw HTML omitted --><!-- raw HTML omitted -->
-
This stackoverflow thread is from 2012. It’s included here not as a criticism of the participants, but as a criticism of the ideas that were current at the time. The post that states that the twelve-factor authors “clearly don’t understand the use of configuration files in .NET” has been awarded a “bounty” of 50 points! ↩︎
-
https://en.wikipedia.org/wiki/Create,_read,_update_and_delete ↩︎
-
A quirk of Azure DevOps is that variable names are upper-cased when being exposed as environment variables. ↩︎
-
In the interest of brevity, this example uses the Azure CLI to create all the infrastructure. On a real project I might use a different tool to do this, but the variable templates would be the same, as would the other parts of the pipeline. ↩︎

Top comments (0)