Pricing and reimbursement data are the lifeblood of the pharmaceutical industry. The maintenance of GPI Pulse involves retrieving, standardising, and interpreting data from over 100 different sources. Automating this data collection and processing is vital to our commercial success.
Historically, our data processing pipelines have been built by developers. These work well, until the data source changes. Unfortunately, when the source drifts, it takes a developer to make the corresponding adjustment to the pipeline. One of our significant challenges in the engineering team has been balancing this sort of maintenance with feature development. At the same time, the analysts were facing delays.
Our response has been to invest in bespoke tooling for our data analysts. Taking the lessons learnt from the development of our traditional pipelines, we have been able to produce a generic, customisable pipeline. This approach has put our analysts back in control of data processing and increased the agility with which we can respond to upstream changes in data formats.
Central to this strategy has been the development of an internal “Domain Specific Language” (DSL). For the sake of familiarity, we modelled this new language on Excel formulas. This language allows for the declarative articulation of a group of data transformation actions, arranged in a sequence of phases. We call this new language “Bartscript” in honour of the contractor who lead the development efforts.
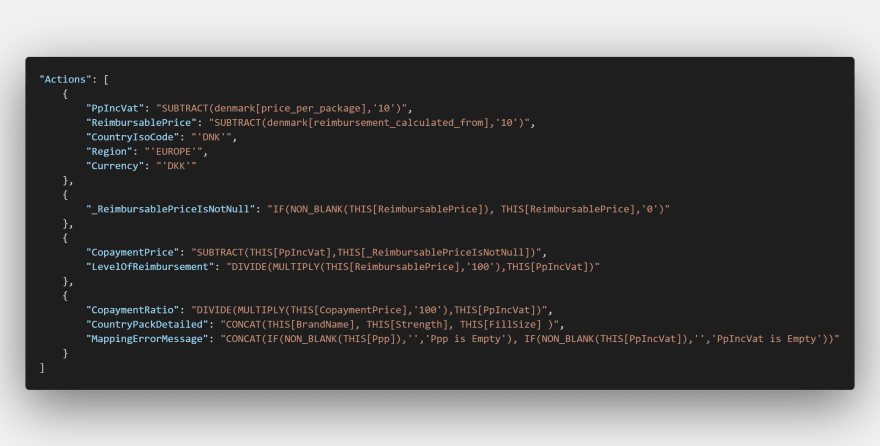
Even though it is so niche, Bartscript has many of the features you’d expect from a fully-fledged programming language:
- Branching logic
- Loosely typed and liberal when it comes to coercion.
- Full sandboxing
- Comprehensive error handling
Despite this sophistication, Bartscript remains deceptively simple to use. This simplicity has facilitated a team of two analysts and one developer to automate sources at a rate of 5 per sprint. For comparison, under the old approach, we would have expected one developer and one analyst to work on one country full time for one sprint (give or take). In other words, we have reduced development time by two thirds.
The real test will come when one of the pipelines requires some modification due to a change in its source. We hope that, in many cases, the analysts can make the necessary changes with minimal support from the developers. We are still in the early days, but the initial signs are good.

Top comments (0)