In this tutorial, we will be exploring SELECT DISTINCT and how to use them for removing duplicate rows form the result set returned by PostgreSQL query.
Introduction
As, we know when we run Select statement. It returns some data and that data contains duplicates sometimes. Hence, Distinct clause is used to discard all the duplicates. Distinct clause can be used on single or multiple columns.
Basic Syntax
SELECT DISTINCT column
FROM table_name;
Here, column will be used to evaluate duplicates.
It is also possible to use multiple columns for evaluating the duplicates.
Only thing we need to do is to define multiple columns after distinct.
SELECT DISTINCT column1, column2
FROM table_name;
In this scenario, the evaluation of duplicates will consider the combination of values found in both the column1 and column2 columns.
Examples
Assume we have following table named distinct_demo.
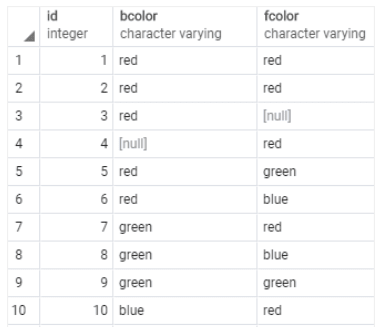
let's use distinct only on one column.
Code
SELECT DISTINCT bcolor
FROM distinct_demo
ORDER BY bcolor;
Output

Now, let's consider the case of using distinct on multiple columns.
Code
SELECT DISTINCT bcolor, fcolor
FROM distinct_demo
ORDER BY bcolor, fcolor;
Output

When we used the SELECT DISTINCT clause in PostgreSQL, specifying both the bcolor and fcolor columns, the database considered the combined values of both columns to determine the uniqueness of each row. The query results displayed the distinct combinations of bcolor and fcolor from the distinct_demo table. It is important to note that the distinct_demo table contained two rows with the value "red" in both the bcolor and fcolor columns. However, when the DISTINCT was applied to both columns, one of those rows was eliminated from the result set since it was considered a duplicate.

Top comments (0)