
Pamela Gotti spoke last year at HasuraCon'20 on how Credimi shifted from REST APIs to GraphQL APIs with Hasura and sped up their development.
As HasuraCon'21 is almost here, we thought it would be the perfect time to take a look back on all the amazing talks by our amazing speakers from 2020!
You can sign up for HasuraCon'21 here!
Here's Pamela's talk in video form:
And below is a text transcription of the talk for those who prefer reading! (The text is slightly paraphrased and edited here and there for clarity's sake.)
TRANSCRIPTION:
Hello, everybody, I'm Pamela. I'm a senior software engineer in Credimi - that's a startup based in Milan - and then CTO of She Tech Italy - that's a community always based in Milan, whose mission is to empower women in tech.
Today, I'm here to talk to you about how we have used Hasura in Credimi, for helping us to develop new features.
What is Credimi

And just gonna take a couple of minutes to tell you what Credimi is. We are a startup born in 2016, in Milan, and we are in FinTech. Our main businesses are invoice financing and medium-long term loans. And we have loaned so far 930 million Euros and that made us the leader digital lender in continental Europe.
I'm going to tell you today how we have used Hasura to improve the time for us to deploy feature in production, as well as how we have used the GraphQL to improve the developer experience by allowing our developers to focus in delivering on business value.
A Time for a Tale
But before I go into detail, I'm going to tell you a story.
So this is a PM, a PM in Credimi that arrives one day, he has this brilliant idea that's going to make our customers very happy. And of course, the developers are really excited to jump on the project to start working immediately. And they are ready to eventually release the feature to production.
So release date, everybody's happy, our customers are happy, everybody is celebrating.
But the day after the PM comes back, he has yet another idea to make our customer even happier if it's possible. But we have to, as developers, we have to get rid of half the code we have written, we have to remove half of the feature. And we have to deploy yet another change that we were not able to anticipate. The developers know that they're going to delete a lot of line of code and that they're going to write some boilerplate over and over again.
So they're not quite happy this time.
What the developers need

So basically, when you're working at a startup, of course, you have to deliver your features as soon as possible to deliver nice user experiences to your customers. And from a developer point of view, that means that you need some versatile tools that allow you to build on what you already have, without necessarily go back, get rid of what you've done, and then building something up that maybe we need to be brought back again.
And that also means that the developer needs to focus on delivering value, they just don't want to spend time reading and writing code all over the places. To argument this, I'm gonna tell you a little bit about how Credimi used to work.
How Credimi Used to Work

This is Credimi 1.0 we're talking about two years and a half ago, we used to have a bunch of microservices written in Scala mostly, we had an Angular JS application client-facing that was interacting with the first layer of backend written in Nodejs. And the complexity of all the microservices was hidden by this Kubernetes Ingress that was taking all the requests from the node and was redirecting them to the right microservice.
So I am talking about Kubernetes here, all our microservices are deployed as a Docker image in a separate pod, and its microservice has its own database. And the communication back then was mainly relying on REST APIs.
What does this mean? This means we have several problems.
Problems with Credimi 1.0

The first one being boilerplate. Whenever we needed to add a new API, we needed to write a lot of code from down to the database up to the REST layer. And then also, we had to remember for example, to add the API at the Nginx level, that's the Ingress I was talking about. Otherwise, the API would not be reachable. That's the point that had a lot of boilerplate to write.
There was no schema shared between the backend and the front end. So even a small typo was giving us problems when developing the new feature, it was kind of tricky to understand where the communication was breaking.
Authorization, why am I talking about authorization because I told you guys that we were doing invoice financing, and after a couple of years, the invoice resource - remember that we are doing, if you're doing a REST back then the inverse resources are huge - we have almost 60 fields on it.
And every time maybe the front end would query the API, the front end would get the full resource back. That means that even if the front end needed 2 or 3 fields, it was still getting the full resource. And if any of those 60 fields was not necessary to the client, or maybe it was not secure to be shown to the client, we had to rearrange the API so that the users, our final user, could see only the data that they needed to see.
And at the same time, this was resulting in a heavy infrastructure. Because at the end of the day to be this huge invoice, we were querying a lot of tables, we were left joining, aggregating, and some of our APIs were taking a lot to execute, we are talking about minutes. And this is, of course, it's not good for the customers.
Credimi was Evolving

In the meanwhile, Credimi was evolving, we got new people in the team, we got new skills, we got new ideas, and we started improving our infrastructure, adding new microservices, and also adopting new languages. We started with Python, we also added Rust. And at the same certain point, also Kafka came into the stack.
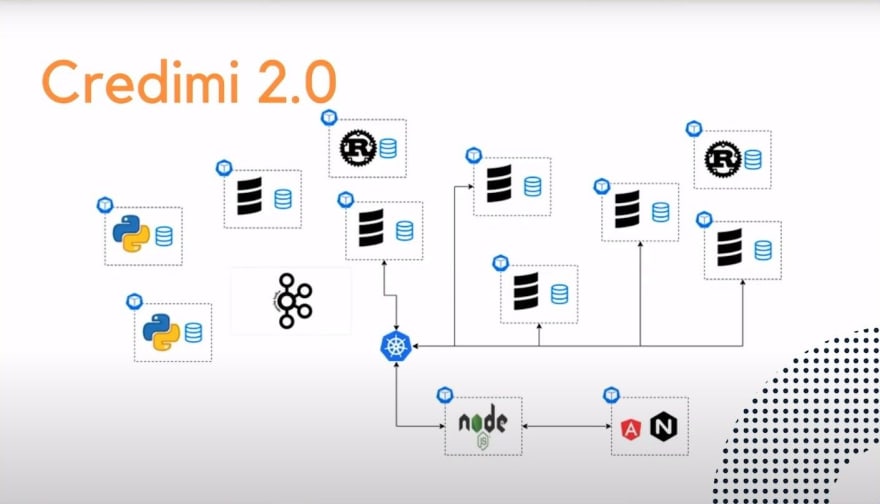
We started using Kafka as, of course, the aggregator of events, and we started switching from a REST API communication model towards a more event sourcing communication model. And we saw an opportunity here.
The Opportunity

So when we started adopting Kafka, it was clear that our write side was behaving really great. But our read side was kind of suffering from using REST APIs and from the fact that all our data were scattered around all the microservices. So we started thinking about taking all the events we were putting on Kafka, and to materialize them into a database.
In this way, we could really start using CQRS, so we could also potentially have a different read side for each user type that was querying our APIs. And at the same time, we also wanted to modernize the stack. We heard a lot about GraphQL, and how it potentially could solve our issues with, as I told by the boilerplate authorization and heavy queries.
Credimi 2.1 - Exposing the Read Side

So the first step was to build the read side database, you can see Postgres database in there is where we actually, we currently materialize all the events that we put on Kafka. And at this point, we started to try to understand how to expose that data to our front end. And, of course, we could have written the server ourselves, but we prefer to rely on somebody that already had experience with GraphQL.

So we were looking for a tool that was easy to integrate with our architecture. So something that was Dockerized, and that could just take the image and to plug it into our Kubernetes cluster. We wanted something that was easy to work with, I don't want my new resource in the team to be stuck waiting for somebody else to fix the server or to expose a new field. I wanted, everybody can just with a couple of configurations would have what they need. And then we also found in time that it's nice to work with a community that is able to share what they are doing with you and to start a collaboration.
Using Hasura - Credimi 3.0
So eventually, we decided to go with Hasura. And this is more or less how Credimi works at the moment.

We still have some REST API here and there. But more or less all the microservices even if there are no ROS in there are communicating with Kafka, they are publishing events. Those events are then materialized on our website that is exposed through Hasura to our front end.
How Development happens at Credimi Now
And I'm going to tell you a little bit about how the developer experience looks like now.

So the very first step that developers do, they meet up and they start to talk about the kinds of resources that they need to develop the new feature. So they try to understand if the resources they need are already there, if they need additional resources, additional fields, if they need additional relationships between the tables, and if they need to expose any new fields with some particular layer of authorization. Basically, they're building the graph of the resources.
And this point is really important, because thanks to this, the developer can also get a grasp of the domain they're working into, and they can bring better value to the feature they are developing.

So the first step, instead kinda like, usually, in Credimi the, at this point, the front end developers, I put a cup of coffee there, because literally, they could wait for half an hour, so then the environment is all set up. Or they also could mock the answer, then the response that the server would give back to them and start to work immediately, but just pretend for now that they just went to grab a cup of coffee.
And the backend developers starts to bring up a new environment where they can both work together. We have our CI/CD tool that can set up a new namespace on our Kubernetes cluster that is totally isolated from the other developing environments that we have up at the moment.
So the namespace is going to have all the microservices that are needed to develop the feature, a dedicated database that is going to act like the read side database we have in production, and the Hasura instance that is going to expose that read side.
A Look at Credimi’s Repo with Hasura
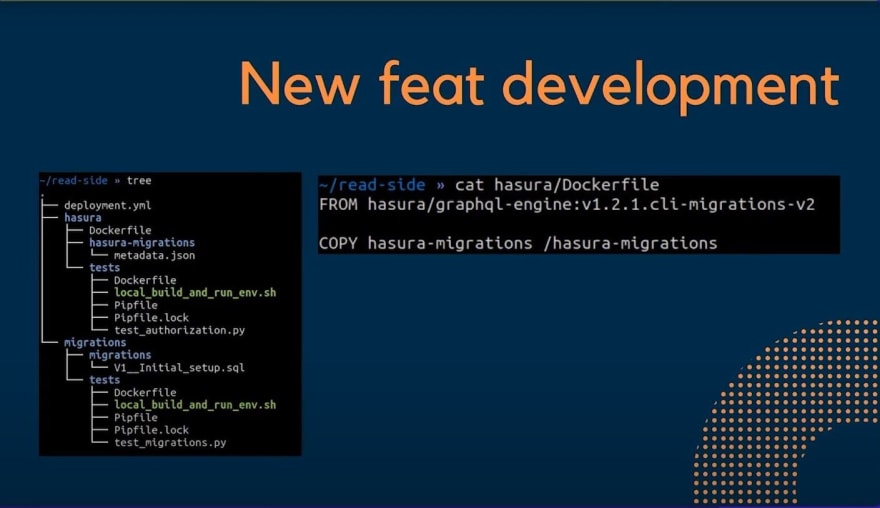
To do that, I'm going to show you the repository that we actually use for bringing up Hasura in a new namespace. This is of course, just an extract of our repository. But you can see on the left-hand side, at the top level of the tree, there's this deployment of YAML file that tells our CI/CD pipeline, what it needs to do.
The first thing our pipeline does, of course, is referred to is to run tests. You can see that in the tree, there are both Hasura folder and the migrations folder. The migrations folder, of course, contains all the migrations that needs to go on the rich side database. And the reason why we have them in the same repository is because we, are assure in this way that Hasura never breaks and that is always aligned with the version of Postgres we expect.
So the first thing with the CI/CD pipelines does we say it is to run the test. How does he do it? He brings up a Docker composition, one that has a Postgres database where all the migrations are applied, and another container is going to run Hasura and then the tests are going to be run.
Note that when we started using Hasura, Hasura still didn't have integration tests, integrating the tool. So we wrote our own tests in Python. So we do have both tests for the migrations and tests for the authorization fields, that test in the Hasura folder, actually check that depending on the type of token we use for querying the server, we get back the fields we are supposed to get.
So this is kind of like testing the authorization layer of Hasura. And the metadata dot JSON file, it will help us to bring up the Hasura exactly as it is in production. It is a data that defines all the relationships and the authorization at field level that builds up the graph.
On the right hand side you can see the Docker image that actually runs Hasura. It is literally the, that is the file, we get the image from Hasura, then we copy over the metadata file, JSON, and that's it, we have Hasura exactly as it supposed to be, plugged into our read side database.

After the tests have run, our CI/CD pipeline runs the migrations, it brings up Hasura, and at that point, we do have a namespace in Kubernetes, that is an exact replica of what we have in production.
Then at this point to go on with the development process.
If there's a need of any additional migration, the backend developer writes the migration, runs the new migration.

And then if anything needs to be added on the GraphQL schema, the backend developer modifies the metadata, that JSON file that I have showed you before. Or she can go on the Hasura UI and she can check that just clicking around making the tables visible, the columns visible to a specific user, then she exports the metadata file and then at that point, that file's version and this is also helpful in phases of code review.
Whenever a pull request is open, whoever reviews that code can clearly see what has changed in terms of permissions on the metadata that are exposed by Hasura.

At this point, we have a namespace that is totally set up. Again, it's ready for the development. The front end developer comes back, uses Apollo to introspect the graph on Hasura. And at this point, he can literally start writing code, whereas the back end developer can focus on some more fun stuff to do.
Note that at this point, if the PM comes back with yet another idea, and he decides that he doesn't want anymore to show data x, y, z to the customer, but he wants instead of to show a, b, and c, the front end developer is totally able to modify the metadata JSON file itself without waiting for the backend developer to modify the server.
Learnings

So this is basically the conclusion of the talk.
What I tried to explain is that following this process, our developers have a better domain comprehension. And they can have really a great comprehension of the big picture. So they can really focus on delivering value. And they stopped writing most of the boilerplate they used to write.
We are able to deliver features faster and why is that because thanks to the first step, the domain comprehension, we have a resource graph that is well defined and well understood from the developer. If the PM asks for modification, then it's trivial to go on the Hasura UI or to modify directly the graph. So the new data are exposed, performance are improved.
Remember, at the beginning, I was explaining that we had this huge resources that were creating a lot of tables in a not efficient way. Now, if the front end only has 3 of those 60 fields that we used to expose them Hasura holds the queries, only the tables that are involved, and APIs that used to take minutes now take milliseconds.
And last but not least, the authorization, I don't need to care anymore that the user don't need to see certain fields of the invoice resource, I can just expose them all. And then at the authorization layer, I'm going to expose, to the, our customers only the fields they need to see and I am able to discriminate on the kind of customer using the token that is used to create a server.
Thanks!
And that's it for the process we use in Credimi if you have any questions feel free to reach out (@pamela_gotti, pamela.gotti@credimi.com), and thank you for tuning in.

Top comments (0)