
You can have a look at the first post of the series here. To know about all the upcoming articles in the series.
So this article is not going to tell you how to use inverted indexes in any DB/framework, but will give you a nice overview of what exactly an inverted index is, its basic structure, how is it different from traditional forward indexes and how are they used in Search engines.
Topics to look out for in this article:
* Introduction to Information Retrieval
* What is an Inverted Index ?
* Traditional database vs Search Engine
* Components of Inverted Index
* Dictionary
* Posting Lists
Introduction to Information Retrieval

Let us suppose you wanted to determine what all news articles of The Washington Post contain the words "environment" and "health" since it's inception. One approach is to start at the beginning and to read through all the text, noting down each article which contains the mentioned words. This technique is generally refereed to as grepping through text. And this process is going to take half your life to complete, pretty sad right ? So what shall we do ?
One of the most popular way to avoid such linear scanning for each query is to index the documents in advance. With proper indexing in place you can do the above mentioned task in like few seconds/minutes on a modern machines. One such index which is heavily used in indexing of large collection of data is Inverted indexes. All of your popular search engines like Elasticsearch/Lucene/Solr use Inverted Indexes heavily to provide you with amazingly fast search systems.
What is an Inverted Index ? How does it make the info retrieval so fast?
To put in extremely simple words - "Reverse/Inverted Index provide a mapping between terms and their location of occurrence in a text collection". Therefore you don't need to scan the whole text collection to retrieve the information, which eventually reduces downs the search time.
A lot of other functionalities like ranked retrievals, spell correction can be implemented over these Inverted Index system to provide hell lot of more functionalities.(These topics will be covered later in this series)
Traditional Database (Forward Indexes) vs Search Engines(Inverted Index)
Lets us assume our System needs us to a collection which has 4 documents: Doc1, Doc2, Doc3, Doc4
Doc1 : Welcome to the Hotel California Such a lovely place
Doc2 : She's buying a stairway to Heaven
Doc3 : Hey Jude, don't make it bad
Doc4 : Take me to the heaven
In traditional SQL DB the data will look something like this:
| Doc ID | Doc Content |
|---|---|
| 1 | Welcome to the Hotel California Such a lovely place |
| 2 | she's buying a stairway to Heaven |
| 3 | Hey Jude, don't make it bad |
| 4 | Welcome to the heaven |
And it is very clear that for any data/information retrieval on the basis of Doc Content column is going to be difficult and complex. Performance in traditional SQL DBs is gained by querying over primary key or or by building efficient "indexes" for traversing these db tables. You can use inverted indexes in SQL DBs like postgresql, but they are not as efficient as they are in search engines like elasticsearch/lucene etc. The indexes used in SQL like B-Tree index(the default one), HashIndexes are kind of a forward indexes where generally the mapping is from Document(aka doc Id) to the whole data row.
Whereas, the same operation over a search engine is much simplified. Due to the use of reverse indexes, retrieval of information across huge number of documents is comparatively very easy and efficient when compared to the traditional dbs.
In Reverse Indexes the mapping is from "terms" to the Documents(as shown in the table below)
| Term | Doc Id |
|---|---|
| buying | Doc2 |
| california | Doc1 |
| Heaven | Doc2, Doc4 |
| hotel | Doc1 |
| Jude | Doc3 |
| lovely | Doc1 |
| stairway | Doc2 |
| welcome | Doc1, Doc4 |
| and so on.... | .... |
This table shows how a simple inverted index works (Much complex implementation is discussed in future posts, but this will give you the gist of it). And it showcases the power of inverted indexes when terms are being searched.
For example if you just search "welcome heaven", we don't have any exact match in the database but using the inverted index we can see that the user is looking for Doc4 or Doc2 or Doc1 (Doc4 having the highest rank score since it is in both the document list for the term welcome and heaven).
To know more about the differences in between forward and inverted indexes you can read this article:Forward and Inverted Indexes-
requirement based differences
Components of Inverted Indexes
Lets start with understanding the components of the inverted index. The two main components of a inverted index are Dictionary and Postings Lists. For each term in a text collection, there is a posting list which contains information about the term's occurrence in the provided collection.
Dictionary
The dictionary works as a lookup data structure on top of the posting lists. Given an inverted index and a query, our first task is to determine whether each query term exists in the vocabulary. Like in The Washinton Post example we first need to identify if the word "environment" is actually available in our vocabulary i.e the inverted index and if so identify the corresponding postings. This lookup operation uses a classic data structure called the dictionary. It has two broad sections of solutions: hashing and search trees. We will be going through them in the next articles.
Posting List
The actual index data is stored in posting list. It is accessed through the search engine's dictionary. Each term has its own postings list assigned to it.
Since the actual size of posting list is too large and therefore its better to keep this stored over disk to reduce the cost. Of course the implementation of disk systems are much more complex than keeping this whole thing in RAM.
Only during query processing are the query term's posting list is loaded into the memory, as required by the query processing routines.
There is no fixed format of posting lists and index, there are alot of different versions for its index like docid-index, frequency index, positional index, schema independent etc. We will be going through them in the coming articles.
Here is the diagram which shows a very simplified structure of an inverted index
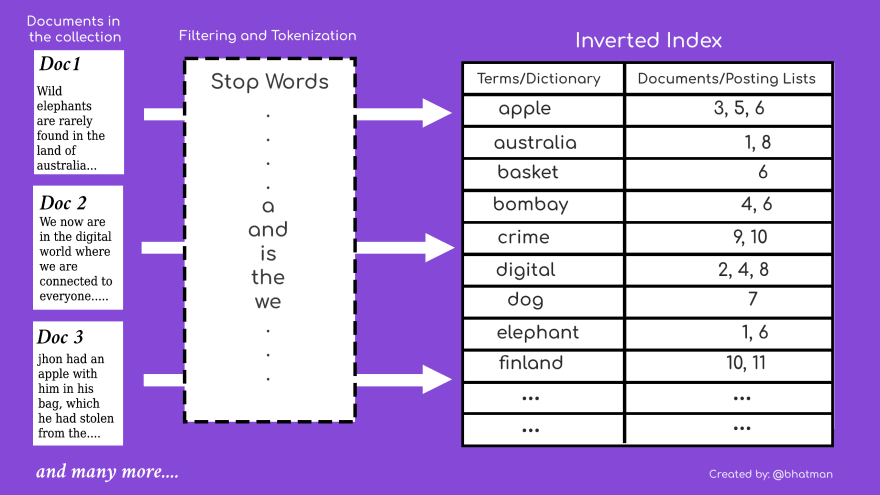 )
)
Stop Words : Some extremely common words that would appear to be of little value in helping select documents matching a query need are excluded from the the vocabulary entirely. Like a, an, and, are, as etc.
The Terms on the left column of the inverted index table is contains the whole vocabulary of our collection which we have received from parsing N number of documents.
Documents/Posting list column helps us to identify the location of the term in our collection. For example: identify in which document is a particular term occurring, at what position in document the term is occurring etc. Other information like frequency of the term in doc, position of the term in doc etc can also be saved in the posting lists column with the document id. There are different ways to implement this too which are discussed in the coming articles.
As of now we have provided a overview of components of the inverted indexes i.e dictionary and posting list. In the next article we will be discussing about the dictionaries and its implementations in-depth.
If you feel some part of the article needs more clarification or some topics which can be covered in the series, please do put them in the comments below and I will for sure work on them.
Thanks. Stay Safe, Stay Strong.

Latest comments (0)