This is the first of a series of articles about my journey going from Ruby on Rails to Elixir/Phoenix.
\Part1 From Rails to Elixir: Know Your App
\Part-2 From Rails to Elixir: Safe Rewrites with NOOP Deployments
I've been doing a lot of Ruby on Rails during my career as a Software Engineer, I absolutely love it and I don't necessarily plan to stop doing it.
In fact, Rails has been the de facto choice not only for my professional projects but also for my personal ones. Most of the times I come up with this revolutionary new ideia that will change the world (no doubt about that) and I rush to the implementation because I don't want to lose the excitement. Since I'm usually in a hurry, it seems natural to me to use the most off-the-shelf set of tools out there that allow me to prototype my brain dump as quickly as possible.
The Price Tracker App
That's what I've done, once again, when I decided that I was going to build a price tracker app meant to be compatible with any online shop in the interwebz. Users will mark items as favourites and then receive notifications by email when their price changes.
I wanted people to be able to use a browser extension to save items so I immediately saw trucks loaded with JavaScript coming my way; then I needed some sort of backend to store this information and periodically scrape online pages for updated prices. I also needed something to help me send email notifications.
Here's how my mind works at this point: it needs HTML/CSS/JS to show at least a simple list of items being tracked, an API to get items from the database, a database of course, and perhaps some kind of background processing thing for the scraping and notifications. So...
 |
 |
 |
 |
* I always found that Sidekiq logo hilarous.
Did I get the tech stack right!? Off I go.
I built the browser extension, built the API to get items through both ways, built a background worker that wakes up every two hours and downloads the HTML page for each stored item and built another background worker that parses all these HTML documents searching for updated prices. I even built a small use-and-discard HTTP proxy repository to get away unnoticed with my scraping but I'm saving it for another blog post.
I think I had a working version after one week of coding during my free time (mostly evenings), because Rails ❤️.
Shipping it to Production 💰
I chose to put it all in one server in order to keep things smooth and simple, which means PostgreSQL, Rails, Redis and Sidekiq sharing a single CPU and 1.70GB of memory.
First deploy with just PostgreSQL and Rails went fine, then I added Sidekiq and Redis and the thing just blew up unexpectedly during the deploy - I was using Capistrano. After more than 1 hour of frustration, I finally figured out that my server was out of memory while trying to compile assets and spawn fresh copies of Rails and Sidekiq.
I shouldn't be compiling assets in the production server to start with, but that's how Capistrano works by default. I could also perhaps have spent some time trying to find a way to restart the app in a more memory efficient manner but I felt that I would be fighting against the technology I had imposed on myself. Plus, any time spent on this particular issue felt worthless to me.
So, next up in Google Cloud was a 3.75GB virtual machine which I imagined would be enough for now. As a side note, I was on Google Cloud because I had heard good stuff about it, plus I was planning to use Google Cloud Functions in a later stage and being in the same cloud provider would eliminate network transfer costs.
Everything great so far. My app was running, I was iterating as fast as new JavaScript frameworks are released 😏 and I even managed to convince some friends to start testing it as real users. I was happy!
...until I saw the bill 💰💰💰😐.

Paying as much as USD 24.27 /month (at the time of this writing) to keep alive a low-effort side project was a total waste of money, even more so because the server itself wasn't doing much and sitting still for most of the time. On the other hand, I needed an expensive amount of memory available to accommodate the baseline memory requirements for Puma/Rails and Sidekiq.
It would make sense for a startup company who is committed to a project to pay such a small amount (in these terms) because the compensatory added value in the form of development speed is far superior. There's this controversial article by Rail's creator DHH about Ruby being fast and cheap enough for companies (I agree to a certain extent).
It wasn't the case for me though, I wasn't burning VC money, hadn't committed to any sort of deadline and I didn't have any salaries to pay so I was prepared to bring down my development speed in exchange for a less expensive infrastructure.
Know Your App
Luckily, I've been doing scaling and optimisation on a Rails-based system for the last 2 and a half years as part of my full time job. I learned valuable lessons about knowing my systems before thinking about optimisations by monitoring every workflow, hunt for bottlenecks, deeply understand the underlying workload patterns (are they fundamentally synchronous, can they be concurrent, who depends on who, etc) and finally tracking down who's stealing the most of your CPU and memory resources.
This acquired experience made me look at my price tracker in a sort of zoomed out version of the system, where the specific parts such as classes and objects and how they interact with each other were not important anymore. Instead, what became relevant to me was how the system could be divided into high level concerns, how these concerns were represented and how they were interacting with each other.
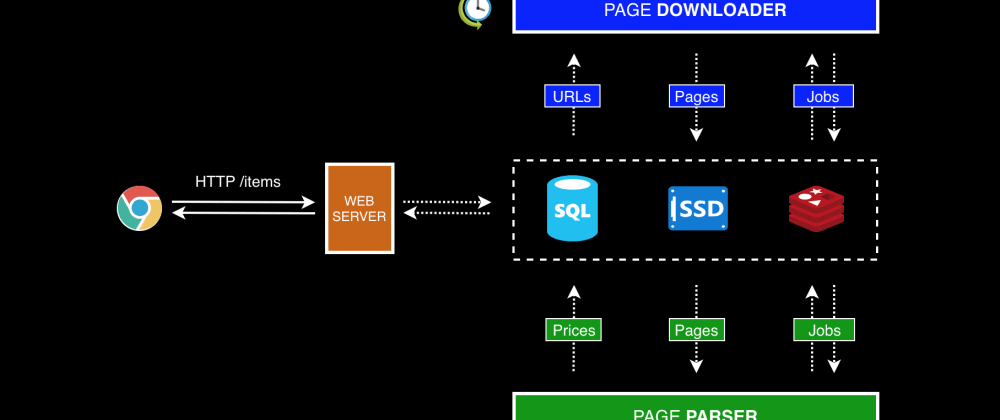
In the end I realised that my price tracker could be divided in four separate concerns:

1\ The Web Server's job was to provide a way for users to manage item lists. This component was just a standard stateless HTTP server, in which each request is 100% isolated from other requests. This is very important because it tells us that they are allowed to run concurrently. Since its main job was to insert and retrieve stuff from a database, most of its execution time was being spent waiting on I/O operations.
2\ The Page Downloader is a background process that wakes up every two hours to gather item URLs from the database and download the corresponding HTML pages into disk. I'm again looking at another type of workload that can run concurrently because there's no shared state between downloads.
3\ The Page Parser is another background process that grabs HTML pages from disk, proceeds with parsing them and then navigates through text nodes searching for updated prices. Whether it finds great prices or not, the final result is reported back to the database. Similarly to the aforementioned services, there's no shared state between different pages being processed, meaning they could also run concurrently. Perhaps the main difference between this and the others is the fact that it might tend to be a little more heavy on CPU than memory due to text search.
4\ The Notifications part of the system is not represented for simplicity, but I plan to write a future blog post about how it integrates with the current topology.
By doing this high level analysis, I learned that all four components had the ability to do their work independently from each other - this didn't happen by accident as they were designed to work concurrently in the first place. The Page Downloader could keep downloading pages while the Parser was already processing the first batch that came through. The Web Server was also there on the side letting users manage their item list without blocking the rest of the system.
I also learned that my system was severely I/O bound as most downloads would take several seconds to complete. I should leverage the slack time the CPU was getting by forcing it to do other useful stuff while waiting.
If you're interested in learning more about concurrent workloads, I recommend the first part of this great talk presented by Golang's co-creator Rob Pike.
If I had a real world application with a fair amount of traffic, I would also spend some time studying server and application metrics. It's important to know every hot path on your system so that you can reason about which parts need to be designed with performance in mind - a concept that is generally described in economy as the Pareto Principle.
That's why people keep talking about monitoring, it really is important, and nowadays there are plenty of options out there to do it, both in premises or as a service. I have used New Relic in the past and I got some pretty valuable insights into my platform from it. Totally recommend it.
Make the Decision
Once I knew that I needed 1) a concurrency-friendly environment to work on top of; and 2) a runtime that would consume very low memory; I felt ready to hunt for the right tool for the job.
In 2018, what is it that pops up in your head when the matter is concurrency? Well, I'm sure the answer to this question will differ based on individual's experiences but in my head it's Elixir and Go.
About Go, the syntax scares me personally and I don't really feel comfortable with the way they do error handling. Although they have an elegant way of doing concurrent stuff using Communicating Sequential Processes (CSP), it's easy to mess up because data structures are still mutable. On top of this, as I heard in a recent podcast, I don't feel that it is capable of providing a high enough abstraction for problems like the one I had in hands.
No hard feelings though, others will have different perspectives 👍.
 |
 |
 |
Elixir, on the other hand, felt immediately familiar to me. Maybe it's because the syntax makes it look like Ruby (it's a trap!) but I can also find similarities in the community. Elixir's creator José Valim was a prolific member in the Ruby community, maybe that's why.
Additionally, because it runs on top of BEAM (Erlang's virtual machine), concurrency primitives are deeply embedded in the language and the actual programming model - the Actor Model - is all about concurrency. This felt like a perfect fit for my concurrency hungry platform. You can learn more about how Elixir shines in this field in this article.
Once I started diving deeper into Elixir and the ecosystem, I started to feel that I was advancing in the right direction:
1\ Great tooling. I needed a web framework and Phoenix checked all the boxes; I needed a jobs framework capable of integrating with Sidekiq for the initial migration and Exq was there; I needed an HTTP client library and httpotion was there; I needed an HTML parser and floki was there; finally, I needed deployment gear and distillery looked fine; All these packages were well documented and well maintained just like I was used to in Ruby land.
2\ It had a Stable and Growing Ecosystem, so I wasn't worried about possibly be using an overhyped tool destined to die in a couple of years. Erlang has been around for 20 years now and Elixir is unleashing its potential by making it more accessible. Even Erlang developers are getting excited by this new language and consequently getting involved in the community. This can only be a positive sign.
3\ It checks all the boxes in terms of my Concurrency requirements. I would be able to spread my workloads across the server and run them in a concurrent fashion, maximising CPU and memory usage. I foresee hundreds or even thousands of downloads happening at the same time in a single machine with little effort.
4\ The native concept of Umbrella Projects would allow me to segregate the different concerns of the platform without the risk of engaging in any sort of over-engineering. More info here.
5\ Infrastructure Costs were expected to be lower judging by all the articles you can read online about companies migrating to Elixir and being able to reduce their fleets from hundreds of servers to just a few. Unfortunately, there's little information about how much memory Elixir needed at rest, but Erlang's website states that people have successfully ran BEAM in a system with just 16MB of RAM, which doesn't mean much. If you have valuable information about memory consumption please reach out.
I would have tested my memory assumptions thoroughly if I was on a real world scenario. In my development machine, I could see an average of 40MB of RAM being used by the BEAM after running iex -S mix with just a few loaded dependencies. I don't know how believable this number is.
6\ I can think of at least two friends of mine that will be very happy once they know I'm finally leaning over Elixir. Seriously guys, if you're reading this, please stop annoying me with all your Elixir shenanigans! It's done, I'm Elixiring now.
Check out their contributions to the community: 1) A super fast jobs framework ExJob based on event sourcing and GenStage by @eidge; and 2) a task scheduling system Cronex by @jbamaro.
More about the pros and cons of Elixir in here.
At this point I felt confident enough to go for this rewrite and I have to add that I was very excited too. I wrote a few modules just to test drive the thing and it really caught my attention. All of the sudden I was devouring documentation, podcasts and online talks so I was genuinely interested and having fun with it. This is very important to me. 🤓🤓
Companies
I was working by myself on this stuff with virtually no restrictions apart from wanting to keep infrastructure costs low. My main goal was to learn and have fun building a low-budget toy product.
Had I been in the context of a company, there's a whole lot of other elements I would have to factor in before making such a decision: 1) it's a relatively new technology so I guess it will be harder to find experienced/keen developers; 2) rewrites usually require considerable development effort and might not produce immediate short-term results; 3) new software might introduce new bugs or bring back old ones; 4) the moment of the switch over to the new platform can be disruptive and takes time to plan carefully; 5) younger startups might benefit from using off-the-shelf tools like Ruby on Rails instead to maximise development speed and consequently burn as less time/money as possible. These are just a few factors worth considering off the top of my head, but I'm sure there are others.
Having said that, once certain products mature and reach considerable scale, it might be worth to replace parts of the system with more performant alternatives either to be able to handle more traffic or reduce costs. Or both. These dudes were able to reduce their fleet of servers from 150 to just 5 by replacing their Ruby on Rails monolith with Elixir/Phoenix. Having done my bit of infrastructure management myself, I can only imagine the vast sums of money they're saving each month.
I guess the lesson here is: if you're a company, always assess the worthiness of a platform migration of this kind before jumping off the cliff.
Final Thoughts & Next Up
At the time of this writing I don't know how much money I'll be able to save as I'm not done with the full migration yet. My goal is to document the whole journey in a series of articles, so you can follow me to get notified for the upcoming posts. There's plenty to talk about, all the way from choosing technologies, going over various implementation details, and finally discuss how to switch over to the new platform in production.
I'm planning to release a follow up on how to approach these kind of platform migrations in the next article of the series. I want to dive into the thinking process behind streamlining the whole migration (decide which parts should be migrated first, etc) in order to mitigate eventual risks. I'm going to use the Price Tracker App as an example.
If you find this article too conceptual, I'm planning to get more technical as the series goes, so expect to see some Ruby and Elixir snippets going forward.
Well, thank you for stopping by and stay tuned for the next one.
Feedback is much appreciated 👍





Top comments (24)
Hi João, really nice post.
Regarding performance improvements, we are on the process of migrating our Rails monolith to Elixir and Phoenix. It's quite impressive what Phoenix delivers.
So far, without any optimizations, we are experiencing an increase of 7x on the supported traffic, with 5x faster response times and using half of the resources (AWS instances, RDS db, etc).
I will soon write a post about our findings.
Hi Elvio, thank you!
That's great, I'd love to hear from someone who is doing this in the real world.
There are some articles out there from people who have done similar migrations but they focus primarily on the outcome (like "we had X servers and were able to reduce to Y"). I haven't come across a nice detailed article focusing on the actual pains and gotchas. That would be very welcome.
Interesting. I wouldn't expect databases (RDS in your case) to benefit too, in fact I would expect extra load on data repositories due to Phoenix increasing concurrent accesses. I mean, since you are now capable of handling more requests in the web server layer, shouldn't RDS be receiving an increase in traffic as well?
There might be an hidden factor in there that I'm not considering. I've come across very surprising outcomes in the past that I wasn't expecting at all.
Yes, I think there are many things I could write about "pains and gotchas" :)
Regarding RDS, is an interesting thing. We are migrating from a Rails app where all the servers were connecting to the same database, as also multiple Sidekiq workers. It required a lot of open connections to handle that.
We now have a quite simple setup where a small pool of connections can easily handle that, even with traffic always hitting the database :)
Yeah I guess that's a nice side effect, with Elixir you might get more control over your whole system (including "external" resources like databases) because it's so easy to reason about what is running concurrently.
Pretty cool!
There's a really good chance you don't even need the job queue. Take this with a grain of salt, I'm just beginning my Elixir journey as well, but basically everyone has told me that a lot of what we Rails developers spun out as separate services can be done directly on the VM. Even Reddis can be largely replaced with things like Mnesia.
You're exactly right. I'm gonna write a full article about why I chose to use a job queue during the transition but the gist of it is:
1\ I want to migrate bit by bit to Elixir, in an incremental fashion. At a given point in time, I'll have Sidekiq and Elixir running side by side in production, so I'll need to consume jobs from Redis originated by Rails. Exq makes my life easier during the transition.
2\ Once I get all the background jobs into Elixir (both Producers and Consumers), I will be able to think in Elixir terms and start refactoring the app to use Processes and other OTP stuff.
This is the plan, I'll share my findings in a later stage 👍
Hi JD, very nice post! Elixir sure seems exciting and what better environment to test new technologies than side projects.
It seems also, by coincidence, the topic of rewrites is recurrent today. I've posted this a few hours ago:
A big rewrite
rhymes
In it there's a description of a rewrite from PHP to Clojure that somebody else did.
I feel like selling Go (because of Google and the insane amount of servers that are popping up written in Go) and Elixir (because of Erlang, consulting businesses and its strong concurrency culture) to companies is going to be easier in the future.
It's also peculiar how many Ruby devs gravitate towards Elixir and how many Python devs gravitate towards Go. It probably has something to do with the fundamental philosophies of the four different languages.
There's always that big tradeoff in productivity that DHH talks about and the concept of good enough for most apps.
I'll happily read the next episodes and learn something :)
Hi, great feedback, thanks!
Just read your post about rewrites and I can relate, going for a rewrite in the context of a company requires careful analysis and planning, but there are some edge cases where it's in fact necessary. You said it all in there.
I guess Elixir/Phoenix feels familiar for Ruby devs. It inherits some things from the Ruby culture like great open source support (people do care about maintaining their extensions, etc) and a tendency for simplicity. Similarities in syntax also help, but as I'm discovering, it's merely superficial.
Personally, I'm leaning over Elixir because I feel that I'm getting what I usually get from Ruby/Rails (tooling, community, simplicity, convention over configuration) and more. It's very easy to create a project and start playing with it,
mixdoes pretty much everything for you.I don't feel the same with Go. I can't say much more because my experience with it is negligible, but I felt that I would have to spend more time thinking about setup/configuration and actual code. I love to write code, don't get me wrong, but I prefer a "less bloated" language in terms of syntax. It allows me to prototype faster and spend more time thinking about the workflow.
Yeah, DHH is very bold in his interventions. I do agree with the idea behind his article, but now we have this new thing that might deliver development speed in the same order of magnitude and at the same time puts you in a better position for the future (in case you come across scaling issues).
Great! The next one will be about how I usually approach rewrites in order to reduce friction during the process.
Thanks for the explanation, I think you made the right choice as I said and indeed tooling can seem a bit more "unixy" and primitive with Go, but this too is because of its philosophy. Tooling it's getting better though. I love Go but Makefiles feel like a step back.
The main selling point in deployment for Go is that you distribute a single binary exec, that you can cross compile and that takes a short time.
I only disagree with one remark you made or maybe I misunderstood your use of the adjective. When you talk about "less bloated" what do you mean? Go is famous for how compact its syntax is. I'm not implying Go is a simpler language to use (after all Elixir abstractions have tons of value) but I wouldn't say "bloat" either :D
I feel like he has become better at explaining the why behind his bold statements in the last few years. I find myself agreeing more and more with his development world view, even if I might not agree 100% with the solution or something (eg. Rails concerns :D)
:-)
Makes sense. If I'm not mistaken, Go was created to be a system's language but I may be wrong
My experience writing Go code is close to zero, I may be saying something silly, but everytime I see a code snippet in Go it looks kind of noisy. Well, "noisy" might not be the right word. Cluttered?
I don't know if it's the amount of symbols, or the type declartions, or even the actual convention of naming things in
PascalCaselike:Which looks strange to me because my eye is trained for Ruby:
Well, one day I'll find the motivation to write some proper Go and get over it :)
I thought so too, but the info I had was incomplete. Go was created for Google's problems. Thousands of developers working with a monorepo and millions of C++ and Java code taking ages to compile. They created a language that was simple to pickup (also for less experienced devs) and had fast compilation time.
From Go at Google: Language Design in the Service of Software Engineering:
So, it was created as a practical working language that was going to be maintanable at large and, initially, would have replaced C++. The thing is C++ programmers outside Google didn't convert in mass, mainly because it's garbage collected and that can be a problem with limited resources and system programming. That's probably why Rust is more interesting to them.
Regarding Go and system programming, Rob Pike says, in the same talk:
He later backtracked on the idea of Go as a "systems programming language". From a later talk with the C++ creator and D and Rust core developers:
Indeed Go is mainly used to write networked servers.
It may have something to do with the explicit error handling. I hated it in the beginning, I still wish there was a better way (I come from exceptions as well) but I understand why they did it. The big advantage is forcing developers to handle error there and then.
Another thing I started loving is the difference between
myStrandMyStr, the first is private to the module, the second is public. Very simple. I think simplicity is what they aimed for for many features, sometimes at the expense of features (like generics).Hi João,
Great post! I'm REALLY looking forward to these figures (if I understand correctly you'll let us know in the end):
Rails: x hours development time, y $/month spent to monitor z pages [reasonably fine-tuned, eg after the jemalloc tweak mentioned above], w resources (time, money, ...) to keep it going
Elixir: p hours development time, q $/month spent to monitor r pages, s resources to keep it going
I'm working with Ruby/Rails since 2005, enjoying Elixir a LOT (it's the second time I feel like this in my life - the first one was when I found Ruby!), interested in scraping (have been doing it for the past 15 years, professionally, academically, OS and every other way) thinking about (partially) switching to Elixir). Oh yeah, and I feel similar about Go (not debating it's power, but not really excited about the implementation details - it's C-like, for starters, which is a dealbreaker for someone thinking the Elixir way is the best stuff since sliced bread, err, Ruby.)
What I'm secretly hoping is that someone can prove me that for this setup, Elixir/Phoenix is a better choice so much so that I can justify spending time on rewriting my Ruby tooling from scratch -considering that my time is really scarce (If I had plenty of time, I would do it out of joy, even if I knew the answer - however, right now I have 2 jobs, 2 kids, 200 other things to tend to etc).
The thing is that as someone currently working on a Rails codebase that's monitoring 1000s of sites around the clock, I know that the shiny stuff that comes with Elixir will get you only so far, and eventually you are going to fight language-agnostic issues anyway (how to detect which of your scrapes are broken, how to maintain/fix the issues the quickest way possible, how to stay under the radar if you are grabbing massive amounts of data (hint: concurrent hammering, even is relatively cheap, is not it), how to deal with rogue data... and more).
Anyways, this comment is way too long already, I'm wondering if you'd like to move the conversation to email - I hate communicating via web forms ;)
Hi Trinity, we are on the same boat then!
Spot on.
Well, I hope that you can find some value from what I'm planning to share in future articles - an incremental migration to Elixir by having both systems working together during the transition phase. You can do a partial rewrite of your system by migrating something that you feel would fit Elixir best in a first stage, just to experiment with it and see if you are getting value from it. In my case I'm planning to migrate the Page Downloader first, keeping all the other components in Rails' land, communicating via Redis (using the Sidekiq protocol).
Absolutely. Using Elixir may offer you better control and tooling but the typical scraping/crawling problems won't go away with Ruby.
Sure, it sounds like our circumstances are very similar, it would be great to share experiences/thoughts with someone with the same set of challenges in-hands. I'm now following you on dev.to (here) and Twitter, we can get in touch through either and share email addrs.
Thanks for the feedback!
Great post. I like how you provided context about your app as part of the justification for making the switch in addition to listing some general pros and cons of Elixir that teams may consider. Thoughtful analysis!
jemalloc may have helped reach your goals with the Ruby implementation. speedshop.co/2017/12/04/malloc-dou...
In theory, jemalloc would have been more conservative in post-boot allocations, keeping memory consumption growing at a lower rate and eventually more stable, due to its focus on handling fragmentation. It wouldn't do much to the baseline memory consumption that Puma/Sidekiq require after boot.
Is this a fair statement? I've never had the chance to try
jemallocmyself, so I'm unaware of how it affects the runtime in practice. I've read a few articles here and there.Sounds like a fair statement. Not sure what we can do about baseline memory requirements on boot.
Though I'm currently using jemalloc on a Standard 1x Heroku dyno (512MB ~ $25/mo) serving about 1.5 million requests/day and it averages 275MB of memory usage with a mean response time of 35ms.
-edit
Note that this is a standard Rails 5+ app using Sidekiq for background jobs. Currently processing about 50k jobs/day.
That's a very efficient Rails app, well done!
I'm waiting for the next part! Thank you for sharing your experience!
Thank you for sharing, - by the way, the link to the Part-1 (dev.to/jdcosta/from-rails-to-elixi...) is broken :(
Still not convinced that elixir has the same use cases as rails
Hello, part 2 is now available:
From Rails to Elixir: Safe Rewrites with NOOP Deployments
JD Costa
Enjoy!
A bit late but for a Rubyist Elixiring this kind of articles are very good ! Thanks !
Nice article, thanks. I wonder why you didn't consider JRuby first?