Traditionally, importing key-value data stores such as Redis into BI, reporting, and ETL tools is problematic, if not impossible. With the CData Drivers, there are several different ways to building a traditional database model to easily work with Redis data in the BI, reporting, ETL, and custom applications of your choice.
In this article, we discuss the way that CData standards-based drivers handle data stored in Redis and Redis Enterprise.
Redis Data Interpretation Approaches
- Using a Redis Key as a Table Name
- Using a Key Pattern as a Table Name
- Using a Key Pattern in the SQL Query WHERE Clause
- Using Connection Properties: DefineTables and TablePattern
The first three options are useful for working with Redis key-value pairs directly, just as if you were working in a traditional Redis environment. The option for configuring connection properties results in related Redis key-value pairs being pivoted into a more traditional data table model. Each approach is detailed below.
Redis Data Types
Redis data is stored in key-value pairs, but instead of the common limit of simple strings, Redis can assign any of several data structures to a given key. Below is a list of the supported data structures (think data types) that can be found in Redis
- Binary-safe strings.
- Lists: collections of string elements sorted according to the order of insertion. They are basically linked lists.
- Sets: collections of unique, unsorted string elements.
- Sorted sets (ZSets): similar to sets but where every string element is associated to a floating number value, called score. The elements are always taken sorted by their score, so unlike sets it is possible to retrieve a range of elements (for example you may ask: give me the top 10, or the bottom 10).
- Hashes: maps composed of fields associated with values. Both the field and the value are strings. This is very similar to Ruby or Python hashes.
This article will discuss how the CData Software Drivers for Redis interact with the above Redis types and includes sample SQL queries for using the drivers to work with Redis data.
Using a Redis Key as a Table Name
The most direct way to work with Redis data with our drivers is to use a Redis key as a table name. Doing so will return a small table with five columns: RedisKey, Value, ValueIndex, RedisType, and ValueScore. The values in these columns are dependent upon the Redis data type associated with the Redis key being used as a table name.
- RedisKey - the Redis key
- Value - the string value associated with the RedisKey and ValueIndex
- ValueIndex - varies by type: 1 for strings; the one-based index for sets, lists, and sorted sets; or the associated field name for hashes
- RedisType - the Redis data type
- ValueScore - varies by type: NULL for strings, lists, sets, and hashes; or the associated score for sorted sets
Below you will find sample data, queries, and results based on Redis data types.
Redis Strings
Create a string in Redis:
set mykey somevalueOKIf you perform a SELECT query on mykey the driver will return the following:
SELECT * FROM mykey

Redis Lists
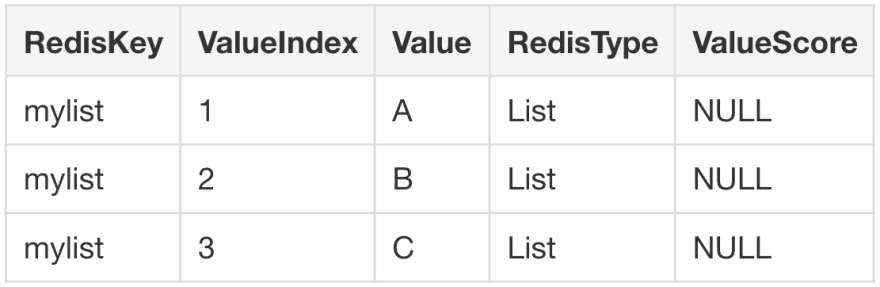
Create a list in Redis:
rpush mylist A B C(integer) 3If you perform a SELECT query on mylist the driver will return the following:
SELECT * FROM mylist
Redis Sets
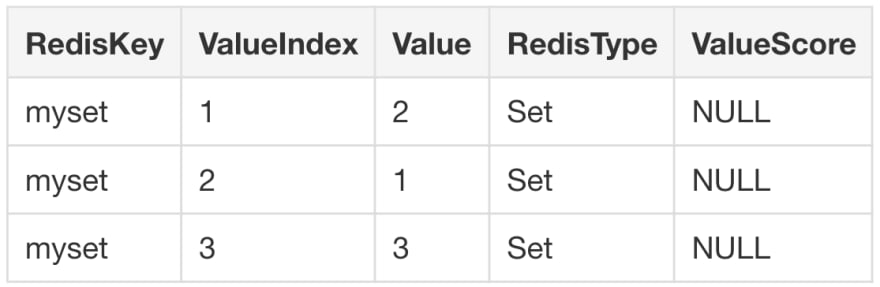
Create a set in Redis:
sadd myset 1 2 3(integer) 3If you perform a SELECT query on myset the driver will return the following (note that Redis can return the elements of a set in any order):
SELECT * FROM myset
Redis Sorted Sets
Create a ZSet (sorted set) in Redis:
zadd hackers 1940 "Alan Kay" 1957 "Sophie Wilson" 1953 "Richard Stallman" 1949 "Anita Borg"(integer) 9If you perform a SELECT query on hackers the driver will return the following:
SELECT * FROM hackers

Redis Hashes
Create a hash in Redis:
hmset user:1000 username antirez birthyear 1977 verified 1OKIf you perform a SELECT query on user:1000 the driver will return the following:
SELECT * FROM user:1000

Using a Key Pattern as a Table Name

If you have several Redis keys that match the same pattern (e.g., "user:*"), then you can use that pattern as a table name. This allows you to retrieve multiple Redis keys at once. Start by adding several keys to Redis that match a pattern:
hmset user:1000 name "John Smith" email "john.smith@example.com" password "s3cret"OK> hmset user:1001 name "Mary Jones" password "hidden" email "mjones@example.com"OK
If you use user:* as the table name, the driver will retrieve all Redis key-value pairs whose keys match the pattern. You can see the expected results below:
SELECT * FROM [user:*]

Using a Key Pattern in a SQL Query WHERE Clause
If you have several Redis keys that match a pattern and have more granular control over the SQL query, then you can use a key pattern (e.g., "user:*") as the criteria for the key column in a WHERE clause. The results will be the same as using a key pattern as the table name. This allows you to retrieve multiple Redis keys at once. Start by adding several keys that match a pattern:
hmset user:1000 name "John Smith" email "john.smith@example.com" password "s3cret"OK> hmset user:1001 name "Mary Jones" password "hidden" email "mjones@example.com"OK
If you use a table pattern as the criteria for the key column in the WHERE clause then you need to use "Redis" as the table name. The driver will retrieve all Redis key-value pairs whose keys match the pattern. You can see the expected results below:
SELECT * FROM Redis WHERE key = 'user:*'

Using Connection Properties
When it comes to connecting to data in third party tools and apps using drivers, you often have little control over how queries are formed and sent to the drivers. In these instances, it makes sense to configure the driver directly, using connection properties, to shape how the data is interpreted. For the Redis drivers, these two properties are DefineTables and TablePattern.
For these sections, we will create the following hashes in our Redis instance:
hmset user:1000 name "John Smith" email "john.smith@example.com" password "s3cret"OK> hmset user:1001 name "Mary Jones" email "mjones@example.com" password "hidden" OK> hmset user:1002 name "Sally Brown" email "sally.b@example.com" password "p4ssw0rd"OK> hmset customer:200 name "John Smith" account "123456" balance "543.21"OK> hmset customer:201 name "Mary Jones" account "123457" balance "654.32" OK> hmset customer:202 name "Sally Brown" account "123458" balance "765.43"OK
When these properties are used to define the driver's behavior, the Redis keys will be pivoted, so that each Redis key that matches the pattern in the definition is represented as a single row in the table. Each value associated with that Redis key becomes a column for the table. While this works differently for each Redis data type, this article will focus on hashes.
DefineTables Property
The DefineTables connection property allows you to explicitly define the names of the tables that will appear in various tools and apps by aggregating all of the Redis keys that match a given pattern. To do so, set the property to a comma-separated string of name-value pairs, where the name is the name of the table and the value is the pattern used to assign Redis keys to that table.
DefineTables=Users=user:,Customers=customer:;
With the property set as above, the Users and Customers tables will be exposed in the tool or app you are using. If you were to query the tables, you would see the following results:
SELECT * FROM Users

SELECT * FROM Customers

TablePattern Property
The TablePattern connection property allows you to define the separator(s) that determine how the drivers define tables. For the Redis keys described above, user and customer would be defined as tables if the separator is set to ":" since the unique piece of each Redis key appears after the ":". If you have a need to structure the tables differently, to drill down further, you can include multiple instances of the separator. Set the property to a pattern that includes the separator(s) needed to define your table structure. Below is the default value.
TablePattern=:;
With the property set as above, the tables user and customer will be exposed in the tool or app you are using. If you were to query the tables, you would see the following results:
SELECT * FROM user

SELECT * FROM customer

More Information
Modern data-driven applications require modern solutions to quickly process a massive volume, variety, and velocity of data and automate decision making.
With the CData Software Drivers for Redis, users can connect to live data cached in Redis from BI, analytics, and reporting tools through bi-directional data drivers.

Top comments (0)