Before jumping into how does python runs internally, let's see the difference between compiler and interpreter in brief.
Compiler:
From Wikipedia:
“A compiler is a computer program that translates computer code is written in one programming language (the source language) into another language (the target language). The name compiler is primarily used for programs that translate source code from a high-level programming language to a lower level language (e.g., assembly language, object code, or machine code) to create an executable program.”
So, a compiler is a software which will take your code written in a high-level language and do some magic and convert it to low-level language which your CPU will understand and execute. Compiled binaries are faster as compiler need not validate binaries every time. You can execute it directly.
Usually, compiled binaries can not run on different operating systems, this is a drawback. Although there are ways and there are different cross compilers available which are a solution for this limitation. I will not go in detail as compile is not in the topic of this blog.
Interpreter:
From Wikipedia:
“In computer science, an interpreter is a computer program that directly executes instructions written in a programming or scripting language, without requiring them previously to have been compiled into a machine language program.”
So, it means interpreter will not process your code before executing. As soon as you run the program, it will start executing your code line by line, starting from line number 1. While executing your code if it gets some syntax error at any line number “n”, it will stop execution and give an error. So, the program will run till line “n-1” which is not the case with compilers. The compiler checks for the syntax and language rule and converts your code in machine language before it starts executing.
Python Interpreter:
Python interpreter is a software program that executes other programs. It’s is a layer of software logic between your code and machine. It may be implemented in C, JAVA etc. depending on the Python flavour you are using.
Let’s check what happens in python.
What happens when you write “python your_file.py"?
You wrote a very complex logic in your python script and now going to execute it. What happens behind the scene?
When you execute a program, it first compiles your complex logic code into a format known as Byte Code. Python interpreter then processes this byte code and execute instruction one by one.
Byte code:
The compilation is a translation step and byte code generated in this step is a low level, platform-independent representation of your complex logic. This byte code can run faster than your code.
Python stores the byte code of your program in files with extension .pyc (.pyc means compiled .py source).
n python 2.x, byte code was created at the same location where your source file is but from 3.2 onwards, it is saved in a subdirectory named pycache located in the same directory where your complex code is and in files whose names identify the Python version which created this byte code.
test.cpython-38.pyc
This is a sample byte code file name which has your source file name as a first part. The second part is the interpreter type and python version. In this example byte code is created using CPython and python version is 3.8(number 38 in the file name) and the third part is byte code file extension.
The new pycache subdirectory helps to avoided clutter and naming convention for byte code prevents different python versions installed from overwriting each other’s byte code.
So, let’s summarize how byte codes are generated:
Python checks the last modified timestamps of source and byte code to know if code needs to recompile.
Python check to see if the file needs to recompile is python version is changed, using either a “magic” version number in the byte code file itself in 3.2 and earlier or the information present in byte code filenames in 3.2 and later.
The result is that both source code changes and differing Python version numbers will trigger a new byte code file.
If python can not write the byte code files on your machine, your programs still work. The byte code is generated in memory and discarded on program exit.
Python will execute your code if finds a valid byte code of your program. It does not matter if your source code is present or not.
This is the stage where all syntax/indentation errors are generated.
But it did not create a byte code for my script.
Keep in mind that byte code is saved in files only for files that are imported, not for the top-level files of a program that are only run as scripts. it’s an import optimization done in python.
What it means is, if your script does not import any file, byte code will not be saved on machine, but it will be generated in memory.
Let’s simulate this. Let's write 3 small script files.
test1.py:
import test2
test2.py:
import test3
print("Namaste world!!!")
test3.foo()
test3.py:
def foo():
if 1:
print("Namaste world from Foo!!!")
print("Namaste world from Foo - 1!!!")
We have 3 files in our directory. Let’s run this as see what happens.

On a successful run, it will generate a subfolder pycache here. But what is there in this directory?

You can see clearly, python interpreter compiled our code and generated byte code for test2.py and test3.py. No byte code is created for test1.py as it is the main script.
Hope it is clear now that byte code files are saved for files which are imported in your script.
But still, if you want to save a byte code file for your script. You will have to write a small script to compile your main program. Add this code in test.py. Replace your script file in place of test4.py.
test.py:
import py_compile
py_compile.compile('test4.py')
test4.py:
def foo():
if 1:
print("Namaste world from Foo!!!")
print("Namaste world from Foo - 1!!!")
foo()
when you will run this compile script, it will compile your main script and save a byte code in pycache subdirectory. You can run this byte code file.
What next, I have a byte code.
Once your program has been compiled to byte code either in a file or in memory, it is forwarded to Python Virtual Machine (PVM).
Python virtual machine:
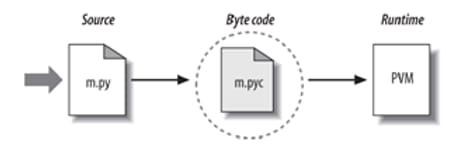
ref: Learning Python by Mark Lutz(5th Edition)
Python Virtual machine is a big code that iterates over your byte code and executes each instruction one by one on your machine. It’s a runtime engine which is always present as part of python. PVM is the one which runs your code on the machine. Python is designed such a way to hide all these complexities from python programmer.
There are some performance implications of PVM. The PVM loop still must interpret the byte code and byte code instruction require more work than CPU instructions.
The bottom line is, unlike in classic interpreter, there is still an internal compilation in python.
Runtime errors are generated in this stage.
Summary
*Python interpreter checks for the timestamp of your script and byte code file. If there is any change in the timestamp, it will recompile the script.
*It will read your script line by line and convert it to bytecode and saves as a byte code file in pycache directory. If there are multiple files imported, it will generate byte code file for each imported file. At this stage, syntax errors are generated.
*Load this byte code file in memory and send it to PVM. PVM will loop over the byte code and execute each instruction. This is the step where all Runtime errors are created in your code.
In my future blog, I will dig deeper into byte code and we will play with it.

Top comments (0)