My introduction to data’s Big O

Let’s say you’re taking a long-ish flight. You’ve got a list of in-flight movies and how long they are. You decide you want to watch exactly two movies, and you want to know if any two on the list have a total run time that is exactly equal to your flight time. (We’re assuming of course, that the flight duration is set in stone haha).
Easy enough if you’re looking at a list of five, or maybe even 10 movies. But what if you don’t know how many movies are in your list. You might have access a huge database of movies. Your list could include 10,000 movies!
The challenge: Write a Ruby method that returns true if any two movies add up to flight time, and false if not.
BUT — there are two extra conditions.
First, you don’t want to watch the same movie twice. So if your flight time is 100 minutes, and your list of movies has only one movie that is 50 minutes long, you want your method to return false. But if you have two movies in your list, and both are 50 minutes long, you want your method to return true.
Second — and this is the hard part, you need to pay attention to run time. As in you want your method’s Big O notation to O(n) or better. …
What’s the Big O ?
Big O notation is a way to calculate how the size of your data impacts how fast your code runs, or how much RAM it uses. Bottom line: it is way faster to find things in hashes than arrays, since you can call them by key instead of looping through each element in order; and nested loops are evil!
The Rubyist’s Guide to Big O Notation is easy to read and includes this helpful chart of smiley faces:

So why are nested loops evil? Let’s say you have code like this:

If your school has 10 students and your city has 10 residents, you have to make 10 x 10 comparisons to run this code, or 10². That’s not bad, but what if your school and your town each have 1,000 residents? now you're up to 1,000² comparisons.
If you think, like I did … well, we can cut down on the length of the operation by filtering out certain values first, so at least we’re comparing smaller arrays … that doesn’t work either. Big O notation is conceptual and assumes the worst-case scenario. Any array of any size has n elements; if you do two nested loops through arrays, you are always doing n² operations. It doesn’t matter if n is actually just 1. What matters is how the value of n² changes with the size of the dataset.
So how do we get out of this mess?
Hashes to the rescue!

Hashes are way faster to search because you call values by key, instead of iterating through a whole array to find a value (What is happening under the hood? Do posts really magically return values without looking at more than one key? Here’s a post that gets into the details).
I was curious to see how this worked out for my particular challenge.
My first effort involved the dreaded, nested loop:
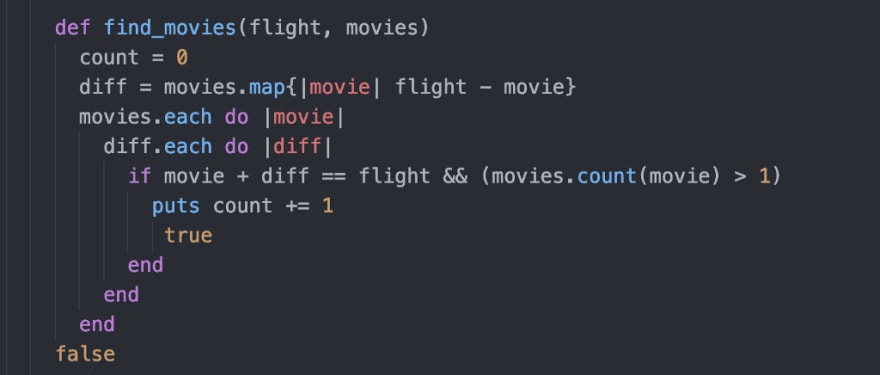
I was curious about the run time with different datasets. I found this great explanation of how to use Benchmark.
Inside my code editor, I added a few lines, including one to randomly generate an array of 10,000 movies, and an impossible flight time (so the method would be forced to look at every single movies element before finishing).

Then I typed ‘ruby test.rb’ to run the code and got this run time: about 4.3 seconds, or 4327.5660001673 milliseconds.
With Hashes
Next, I tried a solution with hashes:

Run time: 3.5880000796169 milliseconds — that is 1,200 x faster!!!

No hash, no nested loops
Next, a solution with no hash, one loop and one operation to pull out common elements from two loops:

Interestingly — this method was actually faster than the one with the hash:.78899995423853 milliseconds.
Finally I tried a super elegant solution from a classmate. This one takes advantage of Ruby’s built-in combination method.

It is short, sweet and wins at code golf. But it is apparently not very efficient under the hood. My computer stalled when I ran this method with an array of 100,000 elements. Here is the time with 10,000 elements: run time: 11.73972999989428 seconds. That’s 3,200 times longer than the hash method … and 15,000 times longer than the comparison method. Yikes!
Here is the chart: (blank spaces mean the method took so long to run that I had to abort after several minutes of inactivty).

The winners for handling data in large arrays (10,000+ elements):
- First place: Ruby’s && method for comparing arrays.
- Second place: hash
- Third place: nested loop
- Fourth place: Ruby’s built-in combination method.
Moral of the story: if you want your code to run fast, avoid nested loops!

Top comments (1)
I had no idea what Big O meant, but not it makes sense. Great post!