En el anterior artículo sobre la gestión de atributos hice una introducción básica a los tipos existentes y comenté con algo más de detalle los de Request y los de Session. En este post veremos los que nos quedaban: Persistent attributes.
Como ya conté en el artículo de introducción, los atributos persistentes se caracterizan por tener un ciclo de vida que va más allá de la sesión. Es información que será guardada en el sistema de almacenamiento que configuremos al crear la skill en el back.
Configurando la capa de almacenamiento
Para poder hacer uso de atributos persistentes tenemos que configurar un PersistenceAdapter cuando creamos la skill. Este adapter será usado por el AttributesManager para guardar y leer los atributos persistentes.
Podemos hacer uso de algunos adapters que ya existen en el SDK o podemos crear los nuestros propios siempre que siga la interfaz marcada. Podéis consultarla en la doc oficial.
En mi caso he usado DynamoDB, una base de datos NoSQL de Amazon, como capa de persistencia y el SDK ya te ofrece un adapter que puedes usar y configurar para tus necesidades. Para S3, un sistema de almacenamiento también de Amazon, existe un adapter que podrás igualmente usar.
Cada sistema tiene sus propias opciones de configuración. Los valores que necesites los podrás indicar en la creación del adapter. Vamos a ver un ejemplo básico en código:
Aquí podemos ver:
- Un método llamado
withPersistenceAdapteral cual tenemos que pasarle el adapter del sistema de almacenamiento ya configurado. - La creación de
DynamoDbPersistenceAdaptercon la config que nos hace falta. Hay varios atributos posibles que están documentados. Como mínimo requerido hay que indicar el nombre de la tabla. El resto son opcionales.
Un punto importante antes de arrancar nuestra skill con persistencia. En el caso de estar usando AWS Lambda tendremos que configurar los permisos del role para poder leer/escribir en la base de datos. En mi caso añadí un permiso bastante completo que, entre otras cosas, te da acceso a DynamoDB.
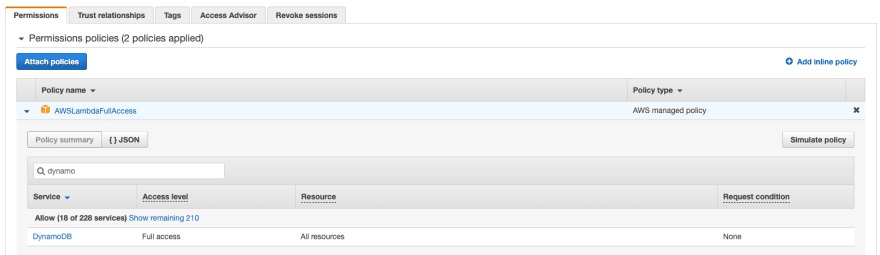
Otro punto interesante a destacar es la posibilidad de indicar una función generadora del partitionKey. Si no indicamos nada, ya que es opcional, por defecto el SDK usará el campo completo userId que viene en cada request. Este campo tiene una parte que no varía por usuario y no nos aporta valor al guardarlo. Por eso, en mi caso, hice una función que se queda solo con la parte identificadora del usuario, la parte final de la cadena "amzn1.ask.account.[unique-value-here]".
Uso del AttributesManager con los atributos persistentes
Una vez tenemos configurada nuestra capa de persistencia ya vamos a poder hacer uso de los atributos persistentes en nuestra skill. Al igual que con los otros tipo de atributos vamos a usar el AttributesManager para leer/guardar la información.
Antes de explicar los métodos hay que reseñar que, por temas de rendimiento, el AttributesManager gestiona una caché local. Esto afecta al funcionamiento de los métodos que nos ofrece el SDK:
-
getPersistentAttributes=> lee la información, primero de la caché y, en caso de no tenerla, irá al sistema de almacenamiento. -
setPersistentAttributes=> guarda la información pero solo en la caché local. De esta forma el método de lectura siempre tendrá los últimos cambios. -
savePersistentAttributes=> este método es el que realmente guarda la información en el sistema de almacenamiento. -
deletePersistentAttributes=> este método elimina la información, tanto de la caché como del sistema de almacenamiento final.
Una práctica bastante extendida a la hora de trabajar con atributos persistentes es crear un par de interceptores, uno para la request y otro para la response, que se encargarán de lectura y escritura de los mismos respectivamente. Lo habitual es volcar información a la sesión y trabajar desde ahí.
Para el interceptor de lectura podemos destacar:
- Solo carga los atributos persistentes si la sesión es nueva. En caso contrario se supone que ya los debería tener de la primera petición.
- Crea la estructura necesaria para volcarlos a los atributos de sesión. En mi caso creé una interfaz para tipar esa estructura y así facilitar su uso en las otras partes de código. De esta forma evitamos equivocarnos al coger los atributos y nos lo valida en tiempo de compilación.
- Al final usamos el método
setSessionAttributespara, a partir de este punto, trabajar con la información a nivel de sesión.
Para el interceptor de escritura podemos ver:
- La capa de persistencia solo se maneja si la
responsees sobre finalizar la sesión del usuario. De esta forma se optimiza la escritura contra el sistema de almacenamiento. - Recuperamos los atributos de sesión y cogemos lo que necesitemos llevar a la capa de persistencia. Los volcamos a los
PersistentAttributescon el métodosetPersistentAttributes. - Por último, guardamos la info anterior en el sistema de almacenamiento final configurado.
Y con esto tendríamos la información necesaria para usar información persistente en nuestra Alexa Skill. Esta claro que, además de este sistema, podríamos tener nuestra propia conexión con una base de datos y gestionarla a mano. Lo interesante en este caso es ver si el SDK nos facilita un poco la vida y exprimirlo al máximo :)

Top comments (0)