
What is eBPF?
eBPF or the "extended Berkeley Packet Filter" is a new Linux kernel bytecode interpreter built at the strong foundation of Cilium, eBPF was originally introduced to filter network packets such as tcpdump, Wireshark, socket filters and more.
Since then eBPF has had a major upgrade with additional data-structures such as hashtable, arrays as well as other packet support actions like mangling, forwarding, encapsulation, etc.
eBPF enables dynamic insertion of powerful security, visibility and networking control logic into the Linux kernel.
Multi cluster, multi cloud capabilities, advanced load balancing, transparent encryption, network security, transparent observability are some of the other services offered by eBPF that we will be going through in this article.
Bytecode Interpreter : The job of the bytecode interpreter is to execute Python code
Hashtable : It is a data structure that maps keys to values using the hash function.
Array : It is a collection of items of the same data type stored at contiguous locations.
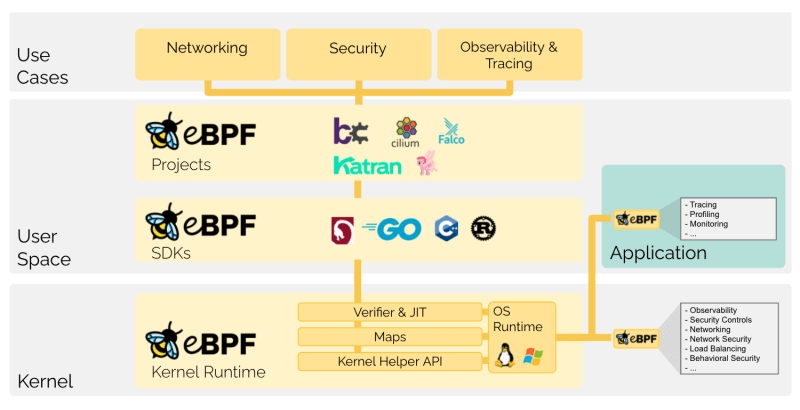
eBPF use cases
Networking beyond limits
Developers can create custom programs that integrate into the Kernel effortlessly, this is at the heart of eBPF, it is able to perform many more tasks such as packet filtering , network monitoring and beyond.
eBPF stands out for its dual prowess in efficiency and programmability, making it a prime choice for networking solutions. Its efficiency ensures swift packet processing, while its programmability allows for versatile adaptation to various requirements. This technology smoothly integrates into the Linux kernel, seamlessly updating packet forwarding logic without disrupting overall processing. eBPF's programmability enables the addition of new protocol parsers, facilitating the recognition and handling of diverse network data types. Crucially, eBPF achieves these tasks without exiting the packet processing context, akin to performing maintenance on a running vehicle. Leveraging a Just-In-Time (JIT) compiler, eBPF executes programmed tasks with exceptional speed, approaching the efficiency of kernel-embedded code.
Safety and security
eBPF is fortified with strict safety checks, before loading into the kernel it undergoes a process as explained below.
There is a built in-kernel verifier that verifies if the eBPF programs are safe to run and the JIT compiler converts the bytecode into instructions specific to the architecture of the CPU. There are various hooking points within the kernel such as incoming and outgoing packets, eBPF can be used in these areas to verify the programs before they have been loaded into the hook points.
Dynamic tracing
Dynamic tracing is one of eBPF's standout features, it gives developers the ability of tracing kernel functions and system dynamically, helping capture intricate system activities without letting kernel modifications and reboots effect it.
eBPF offers the unique capability to be attached to trace points as well as to kernel and user probe points enabling visibility into runtime behavior of applications and the system.
Providing the introspection capability for both the applications and system we can combine the views and find new powerful insights to troubleshoot system performance issues.
Advanced statistical data structures lets us extract useful visibility data in an effective way, without needing to export huge amounts of sampling data that is typical for similar systems.
Observability and Monitoring
Moving Beyond Traditional Metrics: Instead of just using basic measures provided by the operating system, eBPF lets you create your own visibility events and gather specific metrics from various sources.
Deeper Visibility, Lower Overhead: This approach allows for a more detailed understanding of what's happening in your system while reducing the strain on the system itself. It does this by only collecting the necessary data and organizing it directly where it's generated, rather than relying on exporting lots of samples.
So, eBPF gives you more control over what you can measure and understand about your system's performance, all while keeping things running smoothly.
How eBPF works?
eBPF programs are used to access hardware and services from the Linux kernel area. These programs are used for debugging, tracing, firewalls, networking, and more.
Developed out of a need for improved Linux tracing tools, eBPF was influenced by dtrace, a dynamic tracing tool available mainly for BSD and Solaris operating systems. Unlike dtrace, Linux was not able to achieve a global overview of running systems. Rather, it was restricted to specific frameworks for library calls, functions, and system calls.
eBPF is an extension of its precursor, BPF that is a tool used for writing packer-filtering code via an in-kernel VM. A group of engineers started to build on the BPF backend to offer a similar series of features as dtrace, which eventually evolved into eBPF. Although initially released in limited capacity in 2014 with Linux 3.18, you need at least Linux 4.4 or above to make full use of eBPF.
The diagram below is a simplified illustration of eBPF architecture. Prior to being loaded into the kernel, the eBPF program needs to pass a particular series of requirements. Verification includes executing the eBPF program in the virtual machine.
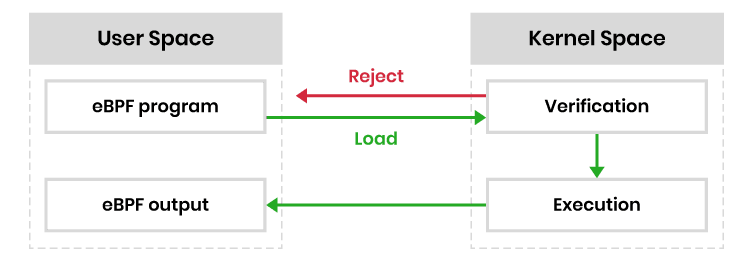
This permits the verifier, with 10,000+ lines of code, to carry out a set of checks. The verifier will go over the potential paths the eBPF program might take when executed in the kernel, to ensure the program runs to completion without any looping, which would result in a kernel lockup.
Additional checks—from program size, to valid register state, to out-of-bound jumps—should also be made. eBPF distinguishes itself from Linux Loadable Kernel Modules (LKM) by adding these additional safety controls.
If all checks are cleared, the eBPF program is loaded and compiled into the kernel at a location in a code path, and waits for the appropriate signal. When the signal is received in the form of an event, the eBPF program is loaded in the code path. Once initiated, the bytecode collects and executes information according to its instructions.
To summarize, the role of eBPF is to allow programmers to execute custom bytecode safely within the Linux kernel, without adding to or changing the kernel source code. Though it cannot replace LKMs altogether, eBPF programs introduce custom code that relates to protected hardware resources, with limited threat to the kernel.

Top comments (0)