AWS Textract is a document text extraction service.
“Amazon Textract is based on the same proven, highly scalable, deep-learning technology that was developed by Amazon’s computer vision scientists to analyze billions of images and videos daily. You don’t need any machine learning expertise to use it” — AWS Docs
This post will provide a walkthrough of several use cases of AWS Textract service using AWS Lambda with Python implementations. Mainly,
Extracting Text from an S3 Bucket Image.
Prerequisites
You need to have an AWS account and some basic knowledge of working with AWS services. Following AWS services will be utilized throughout this guide.
Lamda Service
Textract Service
Simple Storage Service
Identity Access Management Service
| Extracting Text from an S3 Bucket Image
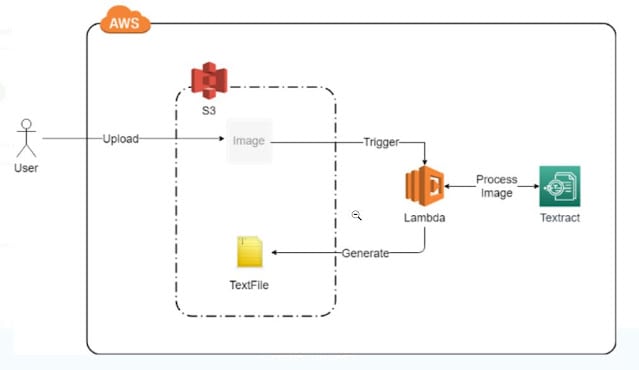
Figure 1: Flow Diagram
When the user uploads the image to the S3 bucket and uploaded it successfully then the Lambda trigger will be activated and the Lambda function will call the Amazon Textract Service which will extract the text from 1mage. Textract will pass the extracted text to the Lamda. Now Lambda function will generate one text file of the same name as the Image name and write the extracted text into text document. This text file will be stored in the S3 bucket.
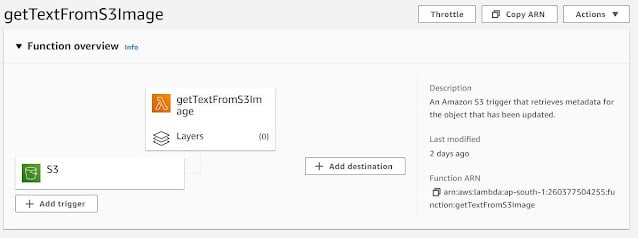
Figure 2: Lambda Function
In the above Figure, one Lambda function is created named getTextFromS3Image.With the Lambda function, the S3 bucket trigger is attached. It will activate on all objects create events with the suffix .png.
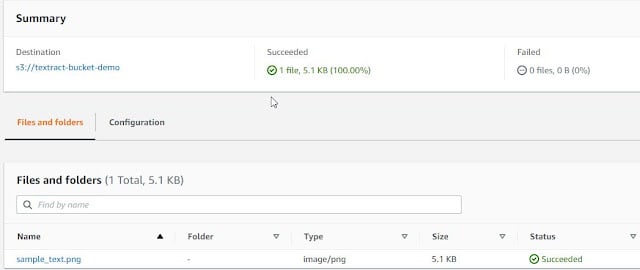
Figure 3:Uploading Image to S3
From the S3 bucket by clicking add files you can attach the png file and then upload it. On the completion of uploading the status will be changed to succeeded.

Figure 4: S3 Bucket
This is the image of the S3 bucket in which I have uploaded 2 png photos for testing the Text extraction.Within 4-5 Seconds the Text file of both the png image is generated and saved as the same name of image with .txt format.
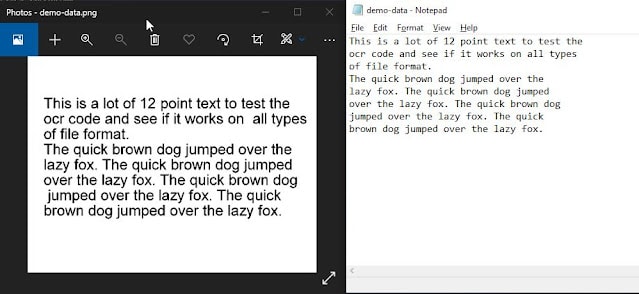
Figure 5: Extracted Text
Here's the final output on the left side one png file is there and on the right side is the extracted text file of the image. As you can see Amazon Textract has correctly identified all the words of the image. Now you can use this text anywhere as per your need.

Top comments (0)