
Websites are stored and run on computers similar to yours, albeit more powerful and sophisticated. Big companies have actual warehouses filled with these little powerhouses stacked on shelves, kind of like Hangar 51 in Raiders of the Lost Ark.

When you type the URL to visit a webpage, your request is ultimately routed to one of these machines. That computer analyzes your request to determine what you’re asking for, then it performs various operations to complete your order, and finally gives it back to you. This is similar to placing an order with the cashier in a coffee shop and having the barista put it together for you.
As more people visit a webpage, the computer has to process and complete each request for each person. Now imagine the webpage gets a nudge by a popular source like Reddit or BuzzFeed. It becomes similar to having thousands of people standing in line in front of you at the coffee shop.
How does cache help?
If everyone is trying to view the same exact thing, why would you process it separately thousands of times? You wouldn’t. Why would you make thousands of individual cups of coffee when you could make one large batch? You wouldn’t.
You process the request once and use that for everyone that wants it. By doing so, the potential processing of thousands of individual requests has been reduced to just one.
This is faster. It’s more efficient. It requires less resources. It saves you money. Everyone comes out a winner here.
… so what is cache exactly?
We summarized earlier that, “cache is an invaluable part of technology that exists in several forms.” So with that, let’s start with a few definitions before we break it down.
Dictionary.com
“A temporary storage space or memory that allows fast access to data: Web browser cache; CPU cache.”
Mozilla.com
“A cache (web cache or HTTP cache) is a component that stores HTTP responses temporarily so that it can be used for subsequent HTTP requests as long as it meets certain conditions.”
Oxford Languages
“A collection of items of the same type stored in a hidden or inaccessible place.”
These definitions provide a nice blend of generalization and specificity to the web. The common denominator here is the topic of storing temporary information.
The idea of cache, temporarily storing information, is important and valuable from microscopic scales up to the most monumental like YouTube and Wikipedia. It exists at various levels throughout each tech stack and is applied for different reasons. Depending on the project, some types of cache provide more value than others, but it’s important to understand the underlying value of cache as a whole to make determinations on where and when to apply the concept.
Reinforcing the idea
Think about how infrequently the majority of content on Wikipedia changes. Then think about the millions of people that consume that content every day. It doesn’t make sense to rewrite each article for every individual requesting it. The logical solution is to write it once, “photocopy” it, then redistribute the photocopies. That’s a conceptual example of cache.
Differentiation of Value
A highly-trafficked website with static (non-changing) information, like Dictionary.com, will likely cache entire pages of content for extended periods of time. A computationally expensive video game may cache the results of complicated math equations that would be referenced thousands of times per second. A key factor in that case isn’t the savings of the individual operation, but the magnitude in which it would be referenced: one penny isn’t a lot of money, but a billion pennies makes you a multi-millionaire.
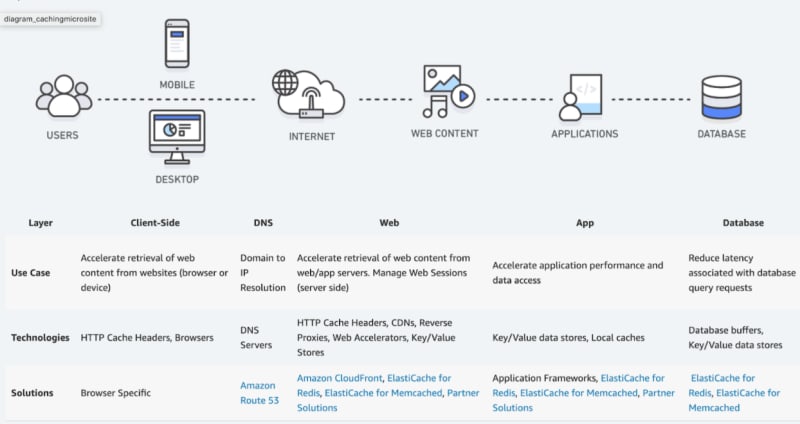
Cache exists in many forms
The anatomy of a web request can be seen in the image above from Amazon’s web services infographic. This will be important because it identifies all the potential bottlenecks that could be sped up using varieties of cache (temporary storage).
Users, like yourself, will typically request content from the web through an app or a web browser. A simplified request flow looks like:
The request starts on your computer/device. Web browsers, like Google Chrome, will cache various bits of information to speed up your access to the web. It will cache DNS responses, it will cache images, it can cache entire webpages, and it can even cache web pages you haven’t looked at yet because it thinks you might look at them.
After we enter a URL into our address bar, like “youtube.com”, the computer will enter the DNS phase (“Domain Name System”). The DNS is essentially a phonebook for the internet. It’s a decentralized system that converts easy to remember names into difficult to remember IP addresses. For the purpose of analogies, IP addresses are kind of like a computer’s phone number and the DNS is your contact list.
By combining domain names and IP addresses with the internet, we are able to specifically locate the computer that contains the files you’re looking for.
This computer (Host Server/Origin Server) accepts our request by looking at the URL we asked for and various other details including, but not limited to, cookies and headers.
By processing this information through a series of programs, the computer is able to determine which video you want to see, which article you’re looking for, etc. The execution of these programs results in a response the computer sends back to the user, which could be an image, a video, a text file, etc.

Let’s work backwards from the Host Server
Backend code is executed on the host server/origin server through programs such as PHP, Python, and Go. Don’t be afraid of these tech terms; they’re just names of programs similar to “Spotify” and “Pandora.” A common flow executing on the computer would be:
NGINX parses the requested URL to determine which program to run next. It could send back a basic image / text file or run complicated programs, such as PHP.
PHP processes backend code written by a developer. It’s capable of performing a wide variety of complicated operations, including database communication, to form a response which is sent to the user.
MySQL is a commonly used database that PHP can connect to. It stores a wide variety of data, such as users, content, transaction information, etc. Think of it like an Excel spreadsheet.
Using each of these programs will consume resources. Computers have a limited amount of resources, such as: memory, computing power, diskspace, and bandwidth. The more money you spend on a server, the better quality of resources you’ll have: more memory, faster CPUs, etc. Even with larger quantities of expensive resources, some demands are just too much.
A developer’s choice in programs matters. Different programs have different memory requirements and some programs are optimized for doing one thing over another.
Technical Example
PHP is significantly faster than Python which means it can complete more requests in a shorter amount of time, but Python is a more generalized language capable of easily handling OpenCV work.
Instead of throwing more money at the problem, we can modify our architecture to use our available resources wisely. Let’s say our server has enough resources to handle 30 programs simultaneously. If 100 users visit our website at the same time, we’ll only be able to process 30 of those requests at once which leaves 70 people waiting in a queue; just like at the coffee shop. After the first 30 are complete, it can process an additional 30 requests; however that still leaves 40 users waiting.
This is often why servers crash and why you see Connection Timed Out errors. It can become a more serious problem with high volume traffic. If we get 100 users per second, then the queue will grow at an unresolvable rate. The server is able to process 30 requests a time, which leaves 70 requests in queue, but in that time, 100 more requests came in, so now there are 170 people waiting. Soon to be 240, then 310, etc.
Using something called reverse proxy cache (nginx, varnish, or others) can assist in fixing this problem. Instead of processing the same request 100 times (once per user), it will process the request just once and send that shared result to the remaining 99 users. This is extremely efficient and saves on resources; which then allows you to do other things with your available resources while also saving you money on hardware.
We won’t dive too far into reverse proxy caching here because it’s an involved subject, but a simple understanding is that you can easily associate basic information like the requested URL to cached data (stored information; on file or in memory). By doing this, you bypass the need for complicated processing; no need to run additional instances of programs like PHP, Python, MySQL, etc. It’s kind of like walking into a coffee shop, grabbing a pre-made coffee, and walking right back out.
There are other varieties of caching that can be performed on the backend such as caching database results, caching the result of complicated filtering, and instance caching. These are often performed by programs such as Varnish, memcached, Redis, and others; additionally, big companies like Google and Amazon offer a wide variety of caching services if you don’t want to operate your own.
Warning!
Be careful about caching data unique to a user. It’s possible to accidentally cache personal information, like authentication tokens or credit card information, and serve that cache to the wrong users.
Practical Example
Maybe your program needs to filter thousands of images by size and color. This can be a very expensive and taxing process to run, so caching helps here by saving the results of your complicated program for the next time you need them.
If you need only yellow images larger than 600px, an acceptable set of results will likely be the same for the next 30 minutes, next few hours, or even days later which means you don’t have to recalculate the same result. Highly complicated actions can be delivered in seconds because they don’t have to be executed on a per-user basis.
What is a CDN?
A CDN (“Content Delivery Network”) represents groups of clustered servers distributed throughout the world. They’re designed to be extremely fast and reliable.
They most commonly exist between you (the user) and the host server (where the backend code files are). That means when your browser is asking for content or downloading an image, it’s actually talking to a computer in the CDN network rather than the machine where the code exists.
Another Analogy
It’s kind of like UPS. They have delivery facilities all over the world. They’re capable of local truck delivery and long distance plane delivery. It doesn’t matter where you order your goods from because UPS is the middleman that eliminates the pain of transport by coordinating a worldwide distribution network. Without them, goods ordered from far away would take longer to receive. Similarly, viewing a website hosted on a far away server would take longer to load.
The CDN is essentially an extremely efficient layer of cache itself. It doesn’t offset the need for other types of cache, but it does provide high value on its own. There are many benefits to using a CDN that go beyond just caching content.
Back down to browser level
Frontend code is executed on each user’s device, such as their web browser. The most common example of this is Javascript code. The files are downloaded from the internet down to your computer, then your browser reads and interprets the file, and you see the results in real time.
When people talk about “clear your cache,” this is usually what they’re referring to. Browsers implement and apply a variety of instructions for each file you download. Instructions from the server may say “This image is allowed to be cached for 3 days,” which means the next time you load that website, the image will be drawn from your computer as opposed to being requested over the internet. This allows websites to load seemingly fast because the content is already on your computer.
“Clearing your cache,” will delete those locally-saved images, Javascript files, CSS files, etc and explicitly ask the server again. This ensures that they will be as fresh as the server allows them to be.
There are several approaches to cache from a frontend perspective including standing browser caching, cookies, localStorage, and sessionStorage. By using an appropriate combination of these mixed with server caching, you can create an extremely efficient API-based SPA (Single Page Application).
Remember!
If the CDN or host server hasn’t updated the content they’re distributing, you won’t see a change no matter how many times you clear your computer’s cache.
Project considerations
Depending on your project, some varieties of cache will provide more value than others. It’s important to understand what you’re building and how you intend to deliver it because it will influence where you should focus your caching efforts.
Technical Reminder
It’s good practice to instance cache / memoize references to objects you use more than once in your code, but if those references provide low value and you forget to reverse proxy cache your application… you’ve just spent your time working to save a dollar when you could’ve been saving thousands of dollars.
Caching is almost always a good solution. Using a 1-second reverse proxy cache can provide amazing value while also providing the illusion of randomness. Let’s say you have a website that shows random memes on page load. Rather than processing a random meme for each and every user requesting the website, you should process a random meme just once every second. Two users in New York and California may see the same meme if they visit at the exact same moment, but what does that matter? When they refresh, they’ll both see something new.
The value for 1 second caching shows up by being able to handle spikes in traffic. If you have 10,000 users from across the world visit your site at the exact same moment, cache can process the request just once and serve the cached result to the remaining 9,999 users. If this spike in traffic continues for a few minutes, resulting in 60,000 users, your servers will only have to process 60 separate requests (one per second) as opposed to processing 60,000 unique requests to deliver identical results. Even the cheapest of computers can handle 60 requests per minute, whereas the amount of resources required to process 60,000 simultaneous requests would cost a fortune.
Closing remarks
The topic of cache is vast, delicate, and intricate. This article didn’t cover all the approaches, ideologies, or types of cache, but acts more as a primer for general understanding by analogy and example. It will take additional work on your part if you want to learn how to apply some of these techniques, but hopefully you have a better understanding about what cache is and the wide variety of places can be used.
If you were to take anything away from reading this, please understand:
Cache is about temporarily storing information which results in saving computational resources, money, bandwidth, and time.
-
Your project will dictate how valuable each level of cache is, which should help guide your efforts toward what will be most valuable for you and your team.
- By understanding the concepts of cache and applying the coffee shop analogy, you can reduce confusion around why certain assets aren’t showing up, why certain text isn’t changing, and determine who is at fault. e.g.: Is it your local computer’s cache? The CDN’s cache? The origin server’s cache?
Cache isn’t just saving files to disk/memory and reading them. It can be used as an intermediary to reduce complex operations like math equations in video games, complex filtering on images, or reducing database query complexity.
When planning your project, have an open conversation across disciplines about what you’re trying to accomplish. Consider points all throughout the network flow of where various types of cache can be beneficial.
Understand that a small file size doesn’t directly equate to speed. If your server’s resources are tied up doing something else, it won’t matter how much you minimized your code. From a coffee shop perspective, it’s kind of like the guy that orders complicated drinks for his entire office right in front of you when all you want is a black coffee. Sure, your order is quick, easy, and should be fast, but he’s in front of you and now you have to wait.
We all want our coffee shop to be popular, enjoyable, and capable of serving as many customers as possible. Be realistic about your coffee shop; is it in a high trafficked area? How will it handle spikes in traffic? Are your baristas working smarter or harder? You’ve implemented online orders, but still only have one barista on staff: Did you really solve the problem or just make it worse?

Top comments (0)