
In the last example, we have created our own small myFamily.db. Now let's take a look at the original family.l document which you can download from here as tgz-file or from my GitLab-repository.
If you open family.l, you will see this:

Note that the database relationship definitions are identical except that the attribute names are much shorter: nm instead of name, pa instead of father and so on. This is mostly a matter of coding style (in my opinion the longer attributes look more friendly).
A potential downside of longer attribute names: Unlike in table-based formats (like for example CSV), the property names are stored in every record so if you really have an extremely large amount of data, it could be an issue. But don't forget: Pre-mature optimization is the root of all evil. 😈
Defining the database block size
At the bottom, you see the following lines:
(dbs
(0) # @:64
(2 +Person) # A:256
(3 (+Person nm)) # B:512
(3 (+Person job dat fin)) ) # C:512
nm stands for name, dat for birthday, fin for death day.
What does this mean? The dbs function ("database size") initializes the global variable *DBs. It takes a list as an argument, where each list element has a number in its CAR (the block size factor), and the information which items to store in the CDR.
The default block size, indicated by 0, is 64 Byte. Analogously, 1 stands for 128 Byte, 2 for 256 Byte and so on. In our example, we see four database files defined.
If you go into the family-folder, you will see that there are four files: @, A, B andC. If you try to open them with a normal text editor, you will see that these are binary files with only few readable strings inside. Let's see where these come from and why we are having four files instead of one.
Let's check their size, for example with $ ls -l:
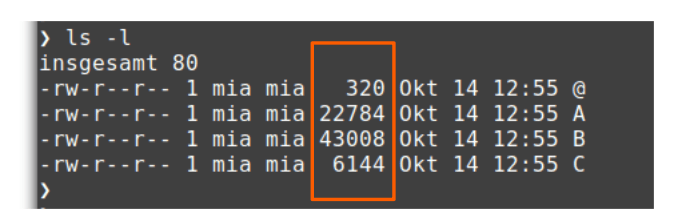
The file size of @ is 320 kB. We know that one block is 64 kB, i. e. file @ contains 5 blocks. File B contains 43008 kB/256 kB = 168 blocks.
Why do we take the trouble to define the block size? Every record starts at a new block. If our blocksize is much smaller than our record size, we need many blocks per record. Even worse, if our item is smaller than the block size, we give away a lot of empty space.
Again, for really small applications it should not matter much, but it can be an important factor for the scalability.
Defining the database content
Now that we have defined the block size per database file, we need to think about what to store where.
As you might remember, we have defined the person's name (nm) as non-unique index, and job, birthday and deathday (job dat fin) as references that should be searchable. In other words, these attributes should be indexed.
Let's check the documentation of the dbs function:
(dbs . lst)Initializes the global variable
*Dbs. Each element inlsthas a number in its CAR (the block size scale factor of a database file, to be stored in*Dbs). The CDR elements are either classes (so that objects of that class are later stored in the corresponding file), or lists with a class in the CARs and a list of relations in the CDRs (so that index trees for these relations go into that file).
Let's compare that to our example:
(dbs
(0) # @:64
(2 +Person) # A:256
(3 (+Person nm)) # B:512
(3 (+Person job dat fin)) ) # C:512
In other words, our database file @ (blocksize 64 kB) is empty (except for the root object and other general meta information). The second file A (blocksize 256 kB) contains the person object (and its subclasses +Woman and +Man). The third file contains the name index. As you might remember, we choose the soundex algorithm for indexing, which means that besides the full-text index also phonetically similar variations are kept. In the forth file we store job, birthday and deathday information.
Working with multiple database files in the REPL
Now let's repeat our little experiment from the last post. We start the REPL with our file family.l:
$ pil family.l +
:
Let's check the global variable *Dbs:
: *Dbs
-> (0 2 3 3)
Good, so the REPL "knows" already about the correct block size of the database. This is important to read available data correctly.
Setting the namespace
Before we open the database files, we need to set the namespace. The namespace tells the interpreter where to look for the symbols.
In the top of the family.l file, you find the following line:
(symbols 'family 'svg 'pico)
This syntax corresponds to the "fourth form" of the symbols function. From the documentation:
In the fourth form,
sym1is initialized to a new namespace if its value isNILand not modified otherwise, andsym1,sym2and all following arguments are set as the current namespace list.
So with this, the namespace name family has been created and all new symbols are now found within the family namespace.
Therefore, before we load the library files, we should also set the REPL to this namespace. For this we use the symbols function again, this time to set the namespace using the syntax symbols lst:
: (symbols '(family svg pico))
-> (pico)
family:
You can see that it changed successfully due to the family in front of the prompt. Now let's open the database files. We can do this by specifying the folder (the trailing slash / is important!):
family: (pool "family/" *Dbs)
-> T
Let's apply what we learned in the last post: Let's look at all entries for +Men with the collect function.
family: (more (collect 'nm '+Man) show)
{A64} (+Man)
ma {A57}
fin 711698
dat 688253
nm "Adalbert Ferdinand Berengar Viktor of Prussia"
pa {A55}
On <Enter> we get many more entries. So as you can see, the database is pre-populated with royals.
The first entry we find is "Adalbert Ferdinand Berengar Viktor of Prussia", and the symbol name is {A64}. The number is the block position of the entry in octal numbers: 64 octal is 52 decimal, which means this record is starting at block 52 in database file A.
Playing around
As mentioned before, collect provides some options that help searching and filtering the results. Let's now try to find all records of Persons that were born between January 1, 1982 and December 31, 1988.
family: (collect 'dat '+Person (date 1982 1 1) (date 1988 12 31))
-> ({A30} {A27} {A20})
We find exactly three entries. To view their names, we can add another argument to the collect function:
family: (collect 'dat '+Person (date 1982 1 1) (date 1988 12 31) 'nm)
-> ("William" "Henry" "Beatrice")
To find a single object in the database, the function db is used:
family: (db 'nm '+Person "Edward")
-> {A13}
As you might remember, we have set the name as a non-unique index. So there could be more than one entry with the name "Edward". Let's specify it with further data:
family: (db 'nm '+Person "Edward" 'job "Prince" 'dat (date 1964 3 10))
-> {A13}
Obviously, a database without interface is a little bit useless. Let's return to the Web Application Tutorial to see how we can integrate the database into our GUI.

Oldest comments (0)