
Microsoft researchers just claimed a breakthrough in AI efficiency with phi-3-mini, a language model that approaches the performance of industry leaders like GPT-3.5 while being small enough to run on a smartphone. On the surface, this is an exciting development — who wouldn’t want a pocket-sized AI assistant that can engage in deep conversation and analysis without even needing an internet connection?
But once you look past the novelty factor, it becomes clear that on-device LLMs are a technical curiosity, not a game-changing advance. In a world of ubiquitous connectivity and cloud computing, deliberately limiting an AI to run locally is almost always going to be a handicap, not a feature. Useful language model applications almost always rely on access to live information (or for you to provide live info in the context window) and the ability to interface with other systems, which fundamentally assumes a networked environment.
In this post, I’ll break down the key claims of the phi-3-mini paper and explain why I believe on-device LLMs are ultimately a technological dead-end, at least in terms of real-world utility. Impressive efficiency gains aside, a model that can’t leverage the full resources of the cloud is going to be severely limited in the value it can provide to users.
This full analysis — covering an overview of the model, its performance, how it works, and why I think it’s all for nothing because it misses something critical not about how AI works but about how technology works — is only available to you if you’re a paid subscriber. Let’s begin.
Subscribe or follow me on Twitter for more content like this!
Overview
The core claim of the paper (more details here) is that phi-3-mini, a 3.8B parameter transformer model, can achieve competitive results on benchmarks like question-answering and coding against much larger models (e.g. GPT-3.5 at 175B parameters) while being up to 46x smaller. This is accomplished not through changes to the model architecture, but by carefully curating the training data to be more information-dense and targeted, an approach the authors call “data optimal.”
“Figure 1: 4-bit quantized phi-3-mini running natively on an iPhone with A16 Bionic chip, generating over 12 tokens per second.”
On common benchmarks like MMLU (68.8% vs GPT-3.5’s 71.4%), HellaSwag (76.7% vs 78.8%) and HumanEval (58.5% vs 62.2%), phi-3-mini indeed achieves impressive results for its size. By using techniques like quantization and long-range attention, they are able to run the model on an iPhone 14 entirely locally.
The authors rightly point out several limitations of phi-3-mini, including its restriction to English, lack of multi-modal understanding, and relatively weak performance on knowledge-intensive tasks (e.g. TriviaQA at 64.0%). But they fail to address the more fundamental issue with the entire premise of on-device LLMs — that deliberately limiting a model’s access to networked resources is crippling for any real-world application.
Technical Details
The key innovation in phi-3-mini is the “data optimal” training approach, which aims to curate a dataset that allows a small model to punch above its weight. Specifically, the authors heavily filtered web data to only retain the most informative examples, and supplemented with synthetic data from larger models designed to improve reasoning ability. The hypothesis is that a lot of natural datasets like raw web crawls contain redundant or irrelevant information that wastes model capacity.
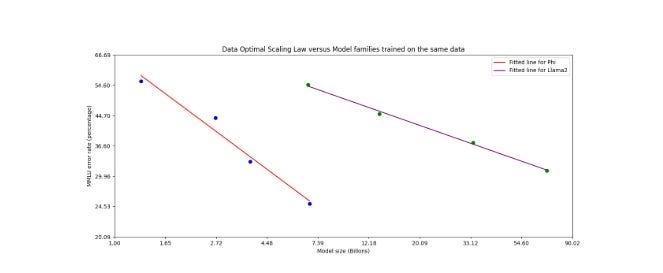
“Figure 2: Scaling law close to the “Data Optimal Regime” (from left to right: phi-1.5, phi-2, phi-3-mini, phi-3- small) versus Llama-2 family of models (7B, 13B, 34B, 70B) that were trained on the same fixed data. We plot the log of MMLU error versus the log of model size.”
The model itself is architecturally similar to Llama-2, using a decoder-only transformer with a context length of 4K tokens (adaptable to 128K using the LongRope method). It was trained on a total of 3.3T tokens using bfloat16 precision. Quantization to 4-bits allows the model to run in under 2GB of memory on a smartphone SoC.
In terms of safety and bias, the authors point to improvements from focused filtering of the training set and additional supervised alignment (Table 2). But it’s unclear if these piecemeal mitigations are sufficient in a scenario where the model is running autonomously on millions of user devices with no centralized monitoring or control (maybe that’s a limitation, or maybe that’s appealing, depending on your point of view when it comes to AI safety/censorship).
Critical Analysis
The core problem with on-device LLMs is this: No matter how efficient or well-trained the model is, deliberately restricting it to run locally on a smartphone or tablet means cutting it off from the vast majority of information and capabilities it would need to be truly useful.
Think about the most impactful applications of large language models today — search, content generation, analysis, coding, task automation. All of these leverage the LLM’s ability to interface with external databases, knowledge bases, and live information feeds as an absolutely essential component. A model running locally on a phone has none of that — it’s operating in a silo, cut off from vital context.
Imagine using GPT-3 to write a report or essay on a recent event. The model would draw on up-to-date information from web searches (either those you perform and feed in or those it does itself), news feeds, and even real-time social media chatter to construct its output. Now imagine trying to do the same with phi-3-mini running locally on your iPhone, with no connection to the outside world for some reason even though your phone probably has cell service or wifi. All it has is its static pre-trained knowledge AND your static pre-trained knowledge, both of which become stale almost immediately. And that’s not even getting into tasks that require active output, like retrieving a file or writing a message you want to another person.
Even if we get local LLMs to work, you still need a network to make that work useful!
The authors gesture at this issue by showing a PoC of phi-3-mini using local search on a phone (Fig. 4), but this doesn’t come close to making up for what’s lost by forgoing cloud resources. A language model is fundamentally a knowledge retrieval and combination engine — why would you deliberately constrain its access to knowledge?

“Figure 4: Left: phi-3-mini’s completion without search. Right: phi-3-mini’s completion with search, using the default HuggingFace Chat-UI search ability.”
Advocates of on-device AI often point to privacy, security, and accessibility benefits. But in reality, a cloud-backed model can be designed to be privacy-preserving and secure, while also being far more accessible by nature of running on centralized infrastructure rather than user hardware of varying capability.
In terms of AI safety and ethics, on-device deployment seems actively counterproductive. An LLM running unsupervised on a user’s device, without centralized monitoring, is a misuse and bias incident waiting to happen. How do you update or patch such a model when new safety issues are discovered? How do you prevent adversaries from extracting the model weights and repurposing them for spam and fraud? These are hard enough problems for cloud models, let alone on untrusted edge devices.
Conclusion
Phi-3-mini is absolutely a genuine accomplishment in terms of language model efficiency and compression. The “data optimal” training approach, if it proves to be robust, could allow us to train high-capability models with significantly less compute and environmental footprint. That’s a meaningful advance and I don’t want to diminish it.
But the use case of on-device LLMs is a technological dead-end. No matter how efficient they become, a model that can’t interface with the web and external tools and services will always be crippled in its real-world utility, so you might as well develop your LLMs for cloud usage. Since you need the internet to get the inputs and outputs, you should just run the model in the cloud too.
In addition, deploying these models directly to users seems to make existing challenges around safety and bias significantly harder, not easier (although you may not find this a drawback).
The true potential of the techniques pioneered here is in making cloud models cheaper and more efficient, not in enabling local deployment. If we can get GPT-3 level capabilities with an order of magnitude less training thanks to data quality improvements, that has massive implications in terms of cost, accessibility, and sustainability of AI progress going forward.
So let’s celebrate phi-3-mini for what it is — an impressive demonstration of language model compression that challenges our assumptions about the size/capability tradeoff. But let’s also be clear-eyed that on-device LLMs, while striking as technical demos, are not the future of real-world AI impact. That future is cloud-native, multimodal, and deeply networked. Local inference is useful for latency and offline functionality, but it will always be a limited subset of what we want these models to do.
Subscribe or follow me on Twitter for more content like this!

Top comments (0)