
Introduction
In the era of big data, we are processing data in TB, PB, or even EB. How to deal with huge data sets is a common problem for those working in the database field.
At the core of this problem is whether the data stored in the database is still valid and useful. Therefore, such topics as how to improve the utilization rate of valid data and filter the invalid/outdated data have attracted great concerns globally.
In this post we will focus on how to deal with outdated data in database.
There are various methods to clean outdated data in database, such as stored procedures, events and so on. Here we will give an example to briefly explain the commonly used stored procedure events as well as TTL in data filtering.
Stored Procedures and Events
Stored Procedures
Stored procedures are a collection of one or more SQL statements. This technique encapsulates the complex operations into a code block for code reusing when a series of read or write operations are performed on the database, saving time and effort greatly for database developers.
Usually once compiled, stored procedures can be executed multiple times, thus greatly improving efficiency.
Advantages of stored procedures:
- Simplified operations. Encapsulating the duplicate operations into a stored procedure, which simplifies calls to these SQL queries.
- Batch processing. The combination of SQL jobs can reduce the traffic between server and client side.
- Unified interface ensures data security.
- Once compiled, run anywhere improves the efficiency.
Take MySQL as an example, assume we want to delete the table as follows:
mysql> SHOW CREATE TABLE person;
+--------+---------------------------------------------------------------------------------------+
| Table | Create Table
|
+--------+---------------------------------------------------------------------------------------+
| person | CREATE TABLE `person` (
`age` int(11) DEFAULT NULL,
`inserttime` datetime DEFAULT NULL
) ENGINE=InnoDB DEFAULT CHARSET=utf8 |
+--------+----------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
This is a table named person, where the inserttime column is a datetime type. And we use the inserttime column to store the generatition time of the data.
Next, we create a stored procedure that deletes this table:
mysql> delimiter //
mysql> CREATE PROCEDURE del\_data(IN `date_inter` int)
-> BEGIN
-> DELETE FROM person WHERE inserttime < date\_sub(curdate(), interval date\_inter day);
-> END //
mysql> delimiter ;
The example creates a stored procedure called del_data, where parameter date_inter specifies the interval between the deletion time and current time, i.e. if the sum of the inserttime column (datetime type) and the date_inter is less than the current time, the data is expired and then deleted.
Events
Events are tasks that run according to a schedule. An event can be invoked either once or repeatedly. A special thread called event scheduler executes all scheduled events.
An event is similar to a trigger as they both run when a specific condition is met. A trigger runs when a statement in database is executed while an event listens to its scheduler. Due to the similarity, events are also called temporary triggers. An event can be scheduled every second.
The following example creates a recurrent event that invokes the del_data stored procedure at 12:00:00 everyday to clean data since 2020–03–20.
mysql> CREATE EVENT del\_event
-> ON SCHEDULE
-> EVERY 1 DAY
-> STARTS '2020-03-20 12:00:00'
-> ON COMPLETION PRESERVE ENABLE
-> DO CALL del\_data(1);
Then run:
mysql> SET global event\_scheduler = 1;
Turn on the event del_event so that it will automatically execute in the background at the specified time. Through stored procedure del_data and event del_event, the expired data is cleaned automatically.
Cleaning Data via TTL
The above section introduces cleaning data periodically via the combination of stored procedures and events. However NebulaGraph provides a simple and efficient way to automatically clean the expired data, i.e. the TTL method.
The benefits of using TTL to clean the expired data are as follows:
- Easy and convenient.
- Ensured security and reliability by processing through the internal logic of the database system.
- Highly automated. The database automatically judges and performs when to process according to its own status. No manual intervention is needed.
Introduction to TTL
Time to Live (TTL for short) is a mechanism that allows you to automatically delete expire data. TTL determines the data life cycle in databases.
In NebulaGraph, data that reaches its expiration can no longer be retrieved, and will be removed within certain future.
The system will automatically delete the expired data from disk during a background garbage collection operation called compaction. Before being deleted from the disk, all expired data have been invisible to the user.
TTL requires two parameters, ttl_col and ttl_duration. ttl_col indicates the TTL column, while ttl_duration indicates the time duration of TTL. When the sum of the TTL column and the ttl_duration is less than current time, the data is expired. The ttl_col type must be either integer or timestamp, and is considered in seconds. ttl_duration must also be set in seconds.
TTL Read Filtering
As mentioned earlier, TTLed records are invisible to users. And therefore it is a waste to transfer these records from storage server to graph service through network. In the NebulaGraph storage service, the TTL information is obtained from meta service first, and then the ttl_col value is checked for every vertex or edge upon graph traversing, i.e. the system compares the sum of the TTL column and the ttl_duration with the current time, finds the expired data then filters them.
TTL Compaction Details
Background: RocksDB file organizations
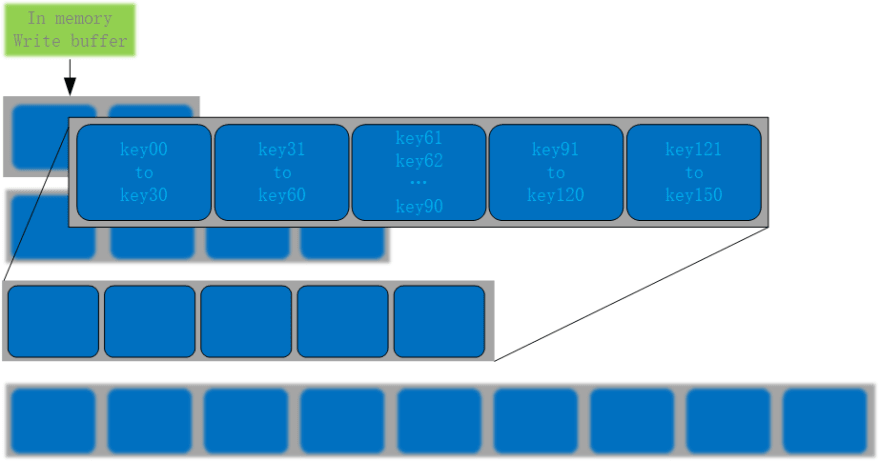
NebulaGraph uses RocksDB as its storage engine. The RocksDB files on disk are organized in multiple levels. By default there are seven levels.

These files are called SST files. For all the keys inside an SST file, they are well sorted by key, structured, and indexed. For Level 1 to Level 6, in every level, SST files are also sorted arranged. But two files in different levels may overlap. So do the files in Level 0, which are flushed and generated from memory (MemTable), i.e. files in L0 will overlap with each other. As shown in the following figure:
RocksDB compaction
RocksDB is based on log-structured-merge tree (LSM tree). But LSM is a concept and design idea of data structure. Please refer to the LSM thesis for details. The most important part of LSM is compaction. Because data files are written in an append only mode, the expired, duplicated and removed data need to be cleaned up through a background compaction operation.
RocksDB compaction logic
The compaction strategy used here is leveled compaction (which is inspired by Google’s famous LevelDB). When data is written to RocksDB, it is first written to a MemTable. When a MemTable is full, it will become an Immutable MemTable. RocksDB flushes this Immutable MemTable to disk through a flush thread in the background, generates a Sorted String Table (SST) file, and places it on Level 0. When the number of SST files in the Level 0 exceeds some threshold, a compaction is performed. It reads all the keys from Level 0, and writes some new SST files to the Level 1 layer. Generally, all files of L0 must be merged into L1 to improve read performance, because L0 files are usually overlapping.
Level 0 and Level 1 compactions are as follows:

The compaction rules of other levels are the same, take the compaction of Level 1 and Level 2 as an example:
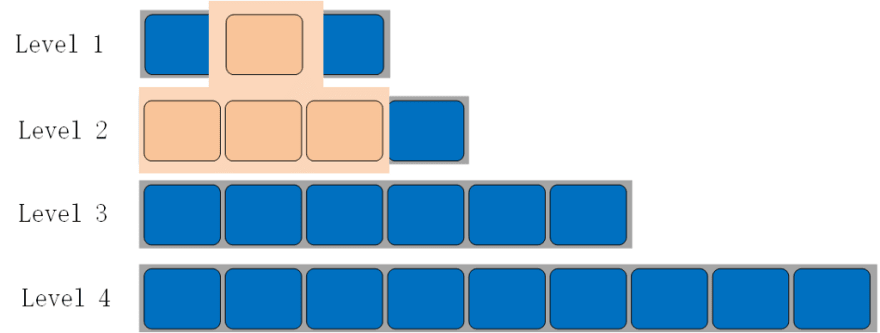
When a Level 0 compaction is completed, the total file size or number of files in Level 1 may exceed a threshold, triggering another compaction between Level 1 and Level 2. At least one file from L1 will be selected and some files in L2 are also selected (which have overlap with this selected L1 file). After this new compaction, the selected files in L1 and L2 are deleted from disk directly, and some new files will be written into L3, which may again trigger another new compaction between L2 and L3, and so on.
From the user’s view, if there is no compaction, the write will be very fast (append only), but the read is very slow (the system has to find a key from a bunch of files). In order to make a balance among write, read, and disk usage, RocksDB performs compaction in the background to merge the SSTs of different levels.
NebulaGraph TTL compaction principle
In addition to the above-mentioned default compaction operation (leveled SST file merge), RocksDB also provides a way to delete or modify key/value pairs based on custom logic in the background, i.e. the CompactionFilter.
NebulaGraph uses CompactionFilter to customize its own TTL function discussed in this post. The CompactionFilter calls a customized filter function each time when data is read in the compaction process. Based on the method, TTL compaction implements the TTLed data deletion logic in the filter function.
Following is the implementation in detail:
- First get the TTL information of tag/edge from meta service.
- During graphs traverse, read a vertex or edge and take the value.
- Get the sum of ttl_duration and ttl_col, then compare it with the current time. This determines whether the data is out of date. The expired data will be deleted.
TTL in Practice
In NebulaGraph, adding TTL to an edge is almost the same as to a tag. We take tag as an example to introduce the TTL usage.
Setting a TTL value
There are two ways to set TTL value in NebulaGraph.
Set the TTL attribute when creating a new tag. Use ttl_col to indicate the TTL column, while ttl_duration indicates the lifespan of this tag.
nebula> CREATE TAG t (id int, ts timestamp ) ttl\_duration = 3600, ttl\_col = "ts";
When the sum of TTL column and ttl_duration is less than the current time, we consider the data as expired. The ttl_col data type must be integer or timestamp, and is set in seconds. ttl_duration is also set in seconds.
- When ttl_duration is set to -1 or 0, the vertex properties of this tag does not expire.
- The ttl_col data type must be integer or timestamp.
Or you can set a TTL value for an existing tag by an ALTER syntax.
nebula> CREATE TAG t (id int, ts timestamp );
nebula> ALTER TAG t ttl\_duration = 3600, ttl\_col = "ts";
Show TTL
You can use the follow syntax to show your TTL values:
nebula> SHOW CREATE TAG t;
=====================================
| Tag | Create Tag |
=====================================
| t | CREATE TAG t (
id int,
ts timestamp
) ttl\_duration = 3600, ttl\_col = id |
-------------------------------------
Alter TTL
Alter the TTL value with the ALTER TAG statement.
nebula> ALTER TAG t ttl\_duration = 100, ttl\_col = "id";
Drop TTL
If you have set a TTL value for a field and later decided that you do not want it to ever automatically expire, you can drop the TTL value, set it to an empty string or invalidate it by setting it to 0 or -1.
nebula> ALTER TAG t1 ttl\_col = ""; -- drop ttl attribute
Drop the ttl_col field:
nebula> ALTER TAG t1 DROP (a); -- drop ttl\_col
Set ttl_duration to 0 or -1:
nebula> ALTER TAG t1 ttl\_duration = 0; -- keep the ttl but the data never expires
Example
The following example shows that when the TTL value is set and the data expires, the expired data is ignored by the system.
nebula> CREATE TAG t(id int) ttl\_duration = 100, ttl\_col = "id"; nebula> INSERT VERTEX t(id) values 102:(1584441231);
nebula> FETCH prop on t 102;
Execution succeeded (Time spent: 5.945/7.492 ms)
NOTE:
- If a field contains a ttl_col value, you can’t make any changes to the field. You must drop the TTL value first, then alter the field.
- Note that a tag or an edge cannot have both the TTL attribute and index at the same time, even if the ttl_col column is different from that of the index.
Here comes to the end of the TTL introduction. Share your thought on TTL by raising us an issue or post your feedback on our official forum.
Originally published at https://nebula-graph.io.

Top comments (0)