
ทีมท่าแซะ ทำงานไม่เป็น ดีแต่ปากดีไปวันๆ วันนี้เราจะมาโชว์การออกแบบ Macbook Pro Cluster สำหรับรองรับระบบที่มีโหลดน่าจะสูงสุดในประเทศไทยกันเลยอย่าง "เราไม่ทิ้งกัน.com" ว่าต้องมี Cluster ใหญ่ขนาดไหนจากข้อมูลที่พอหามาได้
คำนิยมแรกโดยพี่โดมแห่ง (โดมคลาวด์)
เราไม่ทิ้งกัน ประสบความสำเร็จอย่างมาก ทำให้เกิดการตื่นตัวในการทำระบบลงทะเบียนให้รองรับคนจำนวนมากได้
ก่อนเปิด นอบอแซะไว้นิดหน่อยว่าไม่น่ารอด จนเมื่อดึกๆราวๆ 4 ทุ่มผม Chat คุยกับนอบอ
เราสองคนเห็นตรงกันว่า เจ๋งว่ะ ไม่ธรรมดา ปรบมือรัวๆ จากตัวเลขที่เห็นจากจอที่พี่สมคิดโพสต์ทำเห็นอะไรหลายอย่าง
นอบอ เลยทำระบบขึ้นมาทดสอบเล่นๆ แต่ได้ความรู้เยอะ เชิญเสพย์
ว่าแล้วก็มาดูกันก่อนดีกว่าว่าจริงๆ แล้วเราต้องประเมินขนาดของ cluster กันยังไงดี

จากแทรฟฟิกที่เห็นมีการเพิ่มความชันของจำนวนคนลงทะเบียนจาก 3M เป็น 4M สูงชัดเจนมากในเวลาแค่ 12 นาที เราจะใช้ความชันช่วงนี้มาคำนวนขนาดของระบบที่ต้องการกันซึ่งจะได้ว่าระบบต้องการ Peak throughput ประมาณ ~1400 TPS
ต่อไปเราจะมาก่อนว่า Macbook Pro 1 เครื่อง สามารถรองรับ traffic ได้ขนาดไหน โดยเราจะมาทำการ Load Test, Simple Spring Boot 2 ง่ายๆ โดยการทำ register data แบบ simple คือ just persist to RDBMS

จากการรัน ab command จะเห็นว่าจะเห็นว่า throughput ที่ได้คือประมาณ 171.47 TPS อันนี้คือการเขียนโปรแกรมง่ายๆ 2 hrs เสร็จ ก็เอาตามนี้ละกัน
ตัวเลขที่ได้มาหมายถึงอะไร หมายถึงเราต้องการใช้ MBP 8.187 หรือ 9 เครื่องสำหรับรับเฉพาะ API Load. ในกรณีนี้ผมให้ 10 เครื่องเลย เผื่อมีเครื่องดาวน์ได้มีพอ buffer เผื่อ restart
แต่เดี๊ยวก่อน เดี๊ยว ระบบนี้จะมีแค่นี้ไม่ได้ เพราะว่าการมีหลายเครื่องเป็น API เราต้องการ Load Balance สำหรับกระจาย traffic ไปยังเครือ่ง API ด้านหลังด้วย ซึ่งผมคงเตรียมไว้ที่ 2 เครื่องสำหรับให้มี HA model (งาน LB นี่ 1 machine น่าจะทำได้ระดับ 50K TPS สบายๆ)
จากเราต้องมี Web Server สำหรับโหลดพวก Static File ต่างๆ ด้วย เท่ากับเราจะเพิ่ม Web Server เข้ามาอีก 3 เครื่อง สำหรับงานอื่นๆ
เพื่อให้เกิด Monitoring Tool เราจำเป็นต้องมี Grafana Dashboard และ Data Pipeline ซึ่งถ้ารู้ว่าผมใช้ Kafka มาระบบขึ้นเวที Big Data Conference ที่ Taipei ร่วมกับทีมงาน Kafka จาก Apache มาแล้วยังไงก็ใช้ตัวอื่นไม่เป็นนอกจาก Kafka สำหรับทำ message pipeline เราเลยจะได้ ภาพรวมระบบออกมาประมาณนี้
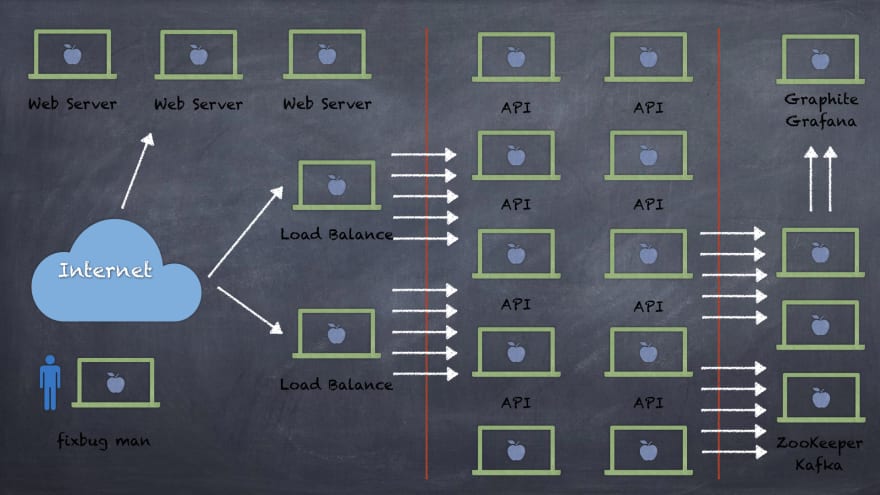
เท่าที่รู้มา ระบบนี้ใช้ทีมงานเพียงแค่ 20คน เท่านั้น ดังนั้นแล้วถ้าทีมงานทุกคนใช้ Macbook Pro เราจะสามารถเอาเครื่องของทีมงาน 19 คนมารันระบบได้ทันทีเพียงแค่เสียบสายแลนและเตรียม Docker Swarm สำหรับรันเอาไว้ให้เรียบร้อย ... รู้อย่างนี้แล้วรีบเอาบทความนี้ให้หัวหน้าคุณอ่านสิครับ
จะเห็นว่าเรายังเหลืออีก 1 เครื่องที่ไม่ถูกใช้ 1 เครื่องนี้เก็บเอาไว้ทำไม ก็เอาไว้สำหรับ fixbug man ไง ที่ต้องคอยตามแก้ปัญหา
ไม่ดราม่านะครับ นี่มันบทความเอาสนุกของจริงมันมีเบื้องหลังที่เราไม่เห็นอีกเยอะ นี่แค่เท่าที่เห็นก็ต้องใช้ Macbook Pro กว่า 20 เครื่องแล้ว
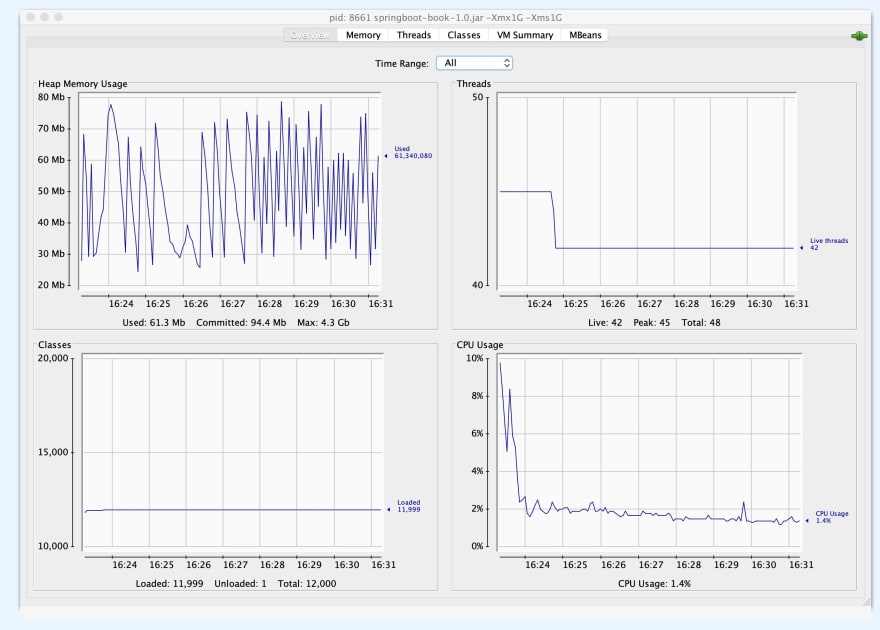
ไหนๆ ก็ไหนๆ แล้วมาเอาสาระกันบ้าง ภาพรวมการทำงานจริงที่ Capture ได้ของ Spring Boot เทียบกับ System เป็นอย่างไร จะเห็นว่า Java แทบไม่ได้ใช้งานเลยเพราะไปติดคอขวดที่ PostgreSQL เพียวๆ สำหรับระบบระดับนี้ RDBMS ไม่ใช่คำตอบจริงๆ ครับ ไว้วันอื่นจะมาทำให้ดูว่าถ้าขยับหนีไป No SQL ที่ผมชอบอย่าง Cassandra จะเป็นอย่างไร

ปล.
- เป็นการทำ Load Test บน MBP15" Model เก่าแล้ว ถ้าทำบน 16" รุ่นใหม่น่าจะได้ Traffic สูงกว่าระบบที่ทำประมาณ 25% [คอขวดน่าจะที่ Postgres vOSX hw change ไม่น่ามีผลมาก]
- ZooKeeper / Kafka ไม่ต้องทำ Load Test
- จริงๆ น่าจะยังเขียนโค้ดให้ดีกว่านี้ได้โดยการเลิกใช้ Spring JPA และ Tuning Prepared Statement ให้ดีกว่านี้ [ลองแล้วไม่มีผล คอขวดอยู่ที่อื่น]
- แอบคิดเหมือนกันว่ามันใช้กว่าปกติมาก ทั้งที่ไม่น่าช้าขนาดนี้ ไล่ๆ ดีบักดูเจอว่ามาจาก Spring JPA จะ Select ID ก่อนทุกรอบว่าเป็น New Record หรือเปล่า หลังจากทดลอง override isNew() โดยเปลี่ยนให้เป็น flag แทน เจอว่าสามารถดัน throughput ของ Spring Boot จาก 170 -> 440 TPS
Copyright (c) 2020. Peerapat Asoktummarungsri https://www.linkedin.com/in/peerapat

Top comments (0)