
Introduction
This is a true story.
One day
Me: Okay, the batch program is complete. This batch processing is super important, so it needs to work flawlessly.
Me: If it doesn't run...
Me: No use thinking about it now.
Me: Registering it with ECS's scheduled tasks..., Done!
Me: Even if the program fails, I'm monitoring for program errors and task failures, so it should be fine!
Few months later
Boss: Hey! The batch program seems to be not working!!

Me: Wha...?

Me: I haven't received any error or task failure notifications!
Boss: It's doesn't matter! Fix it!!
Me: Yes, sir! For now, I have manually run the task for today!!
After work
Me: I wonder why it didn't run. Let's take a look at CloudTrail...ECS tasks are launched via the RunTask API, so let's search for the event name RunTask...
Me: There it is. And the reason for the failure is...?
"failures": [
{
"arn": "arn:aws:ecs:ap-northeast-1:xxx:container-instance/xxx",
"reason": "AGENT"
}
]
Me: The reason is...AGENT?
Motivation
Ever heard of the saying, 'You can't stop the waves, but you can learn to surf'?
Well, in my case, the 'waves' were task failures in an ECS on EC2 environment and 'learning to surf' involved a lot of head-scratching, frantic Googling, and, ultimately, a date with CloudFormation Templates and Step Functions.
This post is a chronicle of my 'surfing' lessons: the struggles I faced and how I eventually tamed the 'waves'.
The Root Cause
In an ECS on EC2 environment, there are three patterns of failure for scheduled tasks:
Failure due to a program: This happens when a task fails due to an error in the program. If there is a stack trace in the standard output of the task indicating a program error, this is the case.
Failure due to task settings: This represents situations like insufficient memory. If there is not enough memory to launch the ECS task and run the program, the task will terminate prematurely.
Failure due to an inability to launch the task: This is the problem this article is addressing. It occurs when the connection with the ECS Agent is lost, or when there isn't enough memory left on the EC2 itself to launch the task. This case is difficult to detect because the task ends without running.
As we focus on the third type of failure in this article, let's delve deeper into its root cause.
On an EC2 running as a container instance, the ECS Agent is constantly active in order to communicate with ECS. However, this Agent is updated once every few hours, and if this timing overlaps with the launch of an ECS task, the operation results in an error. This is not due to a program error or an abnormal termination of the ECS task, but rather because it can't even board the EC2 in the first place.
So, what's the best way to counter this issue?"
The Solution
Firstly, one possible solution is to interpose StepFunctions.
This method is brilliant, as it allows for retries with StepFunctions via RunTask, and the changes are minimal. (While retries are possible with EventBridge Rules, it appears that it won't detect this particular case.)
However, if many tasks are in operation, the cost of migrating all of them can be a bit high.
Therefore, I thought about creating an infrastructure capable of detecting a failure to launch and retrying, and ended up creating the following CloudFormation Template 🎉

ecs_rerun_cfn
This repository contains a CloudFormation stack to rerun ECS tasks on EC2 instances if they fail before reaching the EC2 instance. This typically occurs when the ECS Agent running on the EC2 instance is disconnected. You can refer to API failure reasons for a comprehensive list of reasons why the ECS API may fail, particularly the RunTask or StartTask actions.
How it works
The stack creates the following resources:
- EventBridge (and rules)
- Step Functions
- SNS Topic
- Lambda Function
And some IAM roles and policies.
When an ECS API failure occurs, EventBridge catches the error and triggers the Step Functions. The Step Functions then notify the SNS Topic of the error, which triggers a Lambda Function to send a message to Slack. If the reason for the failure is AGENT, the task is retried up to three times.
How to use
To create the stack, use the quick-create links…
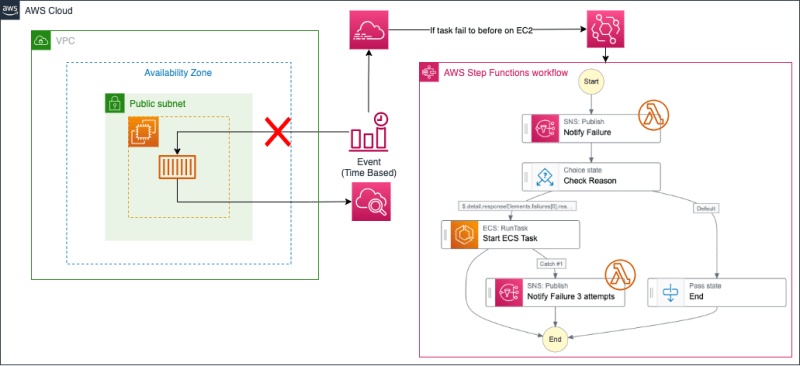
(Right-side resources of the architecture diagram will be created. The repository also includes Terraform for creating left-side resources.)
This template detects the failure of ECS task launch using EventBridge and uses Step Functions to retry the task.
Unlike the previously mentioned infrastructure, you don't need to migrate all existing ECS tasks to this template.
It attempts to retry only when the launch of a task fails.
Quick create link is here 💁♂️
Template Description
As shown in the architecture diagram, the Template creates the following resources:
- EventBridge (and rules)
- Step Functions
- SNS Topic
- Lambda Function
- (And associated IAM Roles and Policies.)
EventBridge
Firstly, we need to detect failure events. That's where EventBridge comes in. Here's a rule I created:
{
"detail-type": ["AWS API Call via CloudTrail"],
"source": ["aws.ecs"],
"detail": {
"responseElements": {
"failures": {
"reason": [{
"exists": true
}]
}
},
"requestParameters": {
"startedBy": [{
"anything-but": "AWS Step Functions"
}]
},
"eventSource": ["ecs.amazonaws.com"],
"eventName": ["RunTask"]
}
}
I'll provide a simple explanation of this rule. 'anything-but' means negation, implying that ECS task events kicked by StepFunctions are excluded to avoid the risk of an infinite loop. In fact, I experienced an infinite loop during testing and had to hurriedly delete the resources...
'exists' is a condition of existence, meaning in this case, it triggers when 'failures' are not an empty array.
For more details, refer to the official document.
https://docs.aws.amazon.com/eventbridge/latest/userguide/eb-event-patterns.html
Step Functions

SNS collaborates with Lambda and is used for Slack notifications. Check Reason verifies the cause of failure, and if it's AGENT, it attempts a retry.
Conclusion
Batch programs play a crucial role in many applications. When their execution is interrupted, it can lead to major problems. In this article, we proposed a solution for when task execution on Amazon ECS fails due to an AGENT error.
As a solution, we created a CloudFormation template to detect ECS launch failures and retry. We used EventBridge to detect failure events and Step Functions to restart tasks.
Moreover, this method does not require migrating all existing ECS tasks, and it only attempts to retry when a task's launch fails, making it an easy-to-implement external resource.
I hope this article will help you achieve reliable batch programs on Amazon ECS.😉

Top comments (0)